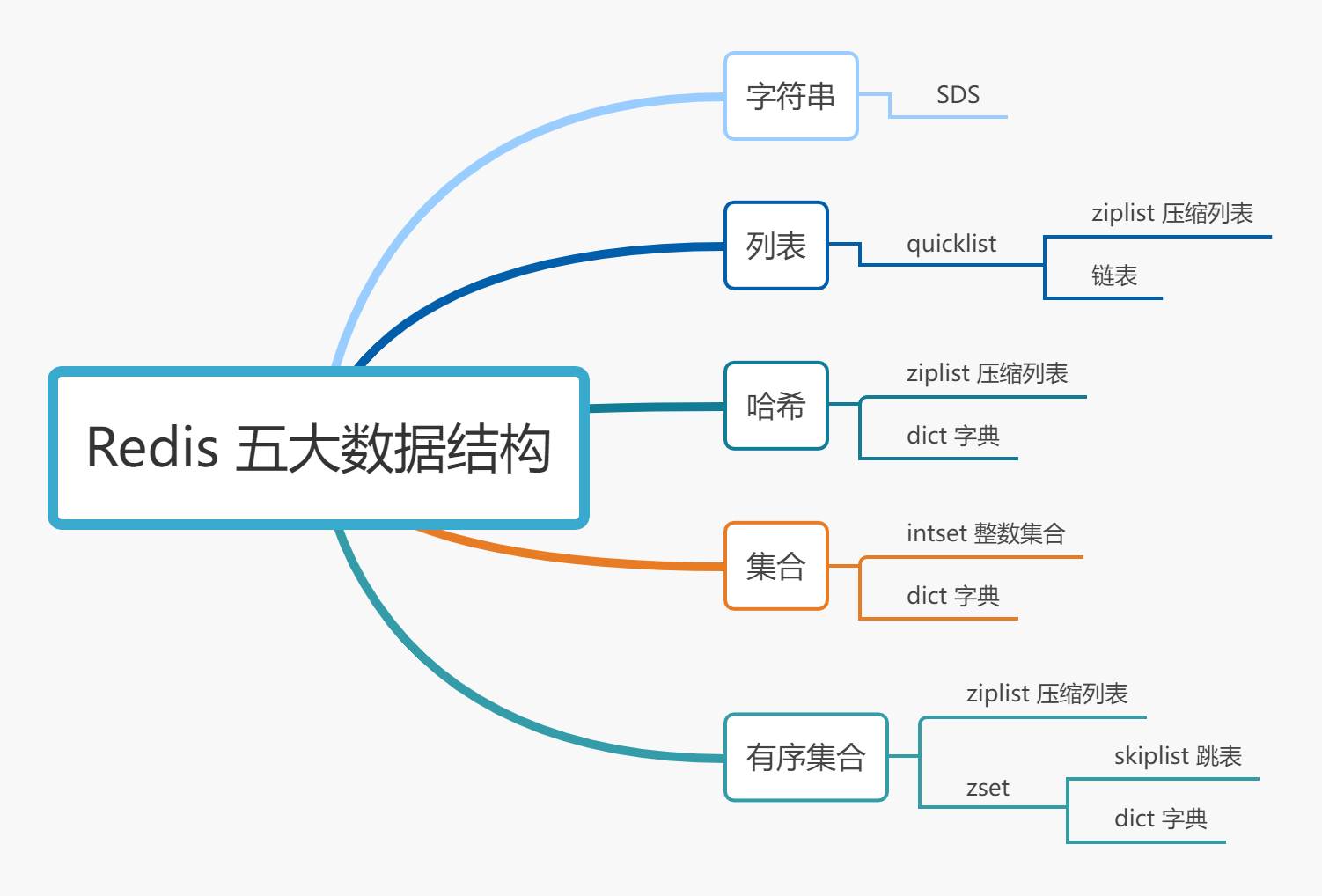
高性能主线:包括线程模型、数据结构、持久化、网络框架;
高可靠主线:包括主从复制、哨兵机制;
高可扩展主线;包括数据分片、负载均衡。
一、键和值以什么结构组织?
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。
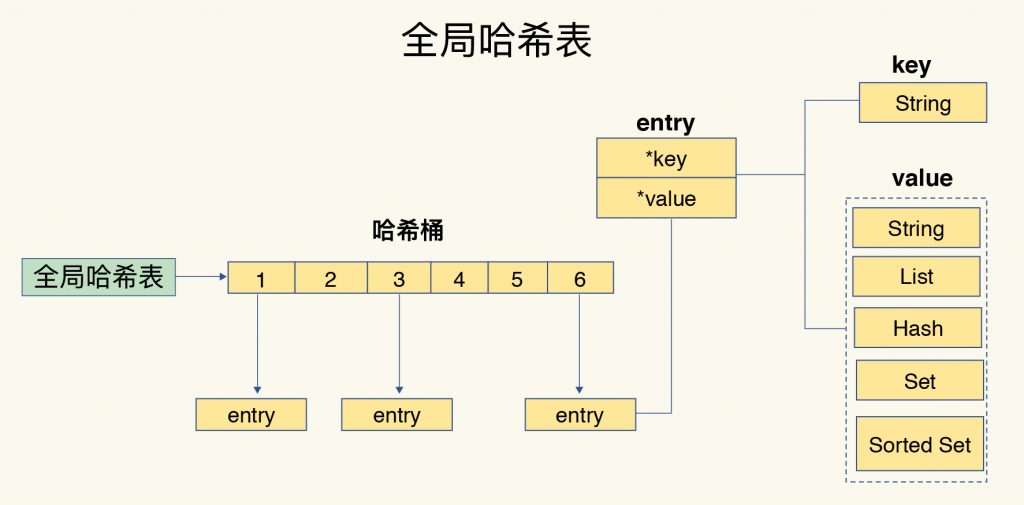
当我们往哈希表中写入更多数据时,哈希冲突是不可避免的问题。Redis 解决哈希冲突的方式,就是链式哈希。
但是,这里依然存在一个问题,哈希冲突链上的元素只能通过指针逐一查找再操作。随着哈希表里写入的数据越来越多,哈希冲突可能也会越来越多,这就会导致某些哈希冲突链过长,进而导致这个链上的元素查找耗时长,效率下降。因此,redis 引入了 rehash 机制,来对哈希表进行扩容。
1. rehash
rehash 的主要思路是增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量(缩短链表的长度),从而减少单个桶中的冲突。
具体到 Redis, 它默认使用了两个全局哈希表:哈希表1和哈希表2。一开始,当你刚插入数据时,默认使用哈希表1,此时的哈希表2并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
- 给哈希表 2 分配更大的空间,默认是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 释放哈希表 1 的空间;
这个过程看似简单,但是第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法服务其他请求。
2. 应对哈希冲突和 rehash 可能带来性能阻塞:渐进式 rehash
在第二步拷贝数据时,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries
渐进式 rehash 开始时,会在 redis 中维护一个 rehashidx 的变量,代表 ht[0] 的索引,初始值为0。渐进式 rehash 是“随着执行请求,顺带 rehash”,而不是 “根据当前请求的 key,顺带 rehash”。每次处理一次请求,对当前 rehashidx 对应的元素进行拷贝,拷贝完成,rehashidx++。当整个 rehash 执行结束,rehashidx 设置为 -1,此时 ht[0] 的空间就可以释放了。
同时,在渐进式 rehash 执行期间,新添加到字典的键值对一律会被保存到 ht[1] 里面,而 ht[0] 则不再进行任何添加操作:这一措施保证了 ht[0] 包含的键值对数量会只减不增。
另外的,Redis本身还会有一个定时任务在执行rehash,如果没有键值对操作时,这个定时任务会周期性地(例如每100ms一次)搬移一些数据到新的哈希表中。
二、底层数据结构
1. 简单动态字符串 SDS
之所以构造了 SDS,不使用 c 中的字符串,主要是出于以下几点考虑
- SDS 获取长度的复杂度为O(1)
- SDS 可保存二进制数据(通过len来判断长度,而不是以'\0'作为结尾)
- SDS 可以减少内存分配的次数
- SDS api不会造成缓冲区溢出(持有free空间大小)
struct sdshdr {
int len; //已使用的长度
int free; //未使用的长度
char buf[]; //用于保存字符串
}2. 链表
struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void (*free) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match) (void *ptr,void *key);
}3. 字典
typedef struct dictEntry{
//键
void *key;
//值。可以是一个指针,也可以是uint64_t整数,也可以是int64_t整数
union{
void *val;
uint64_tu64;
int64_ts64;
}
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值。总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}
typedef struct dict{
dictType *type; //保存了一簇用于操作特定键值对类型的函数
void *privdata; //保存上面函数可能用到的参数
dictht ht[2]; //包含两个哈希表的引用
int trehashidx; //rehash索引,没有发生rehash时,是-1
}4. 跳表 skiplist
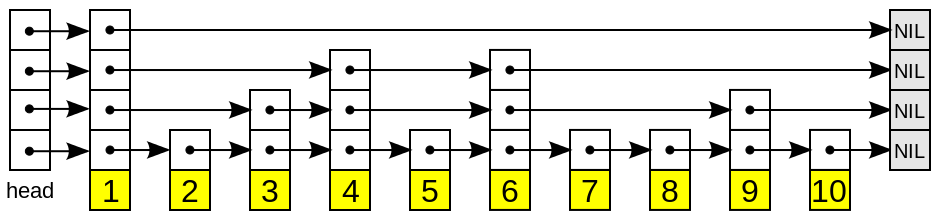
1. 普通的跳表
2. redis中改进的跳表
实际应用中,普通的跳表在增、删数据的时候相当不方便。新插入(删除)一个节点之后,就会打乱上下相邻两层链表上节点个数严格的 2:1 的对应关系(步长)。如果要重新调整,这会让时间复杂度重新蜕化成 O(n)。
为了避免动态调整造成的负担,redis 不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)(Redis 跳跃表默认允许最大的层数是 32)。比如,一个节点随机出的层数是 3,那么就把它链入到第 1 层到第 3 层这三层链表中。
结合下面的数据结构,redis 中的跳表的结构是:
typedef struct zskiplistNode {
struct zskiplistLevel{ //层,表头默认32层
struct zskiplistNode *forward; //前进指针
unsigned int span; //跨度
}level[];
struct zskiplistNode *backward; //后退指针
double score; //分值
robj *obj; //成员对象
}
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}1. 创建跳表
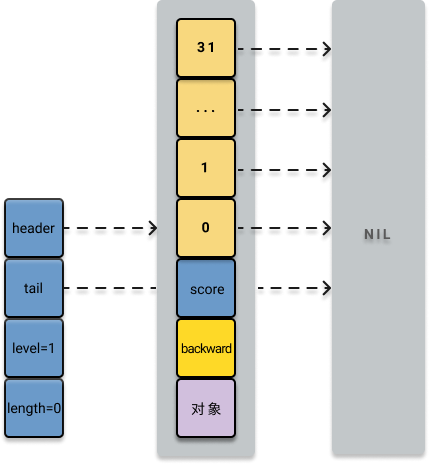
这个过程比较简单,参考源码中的 t_zset.c/zslCreate
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 申请内存空间
zsl = zmalloc(sizeof(*zsl));
// 初始化层数为 1
zsl->level = 1;
// 初始化长度为 0
zsl->length = 0;
// 创建一个层数为 32,分数为 0,没有 value 值的跳跃表头节点
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 跳跃表头节点初始化
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
// 将跳跃表头节点的所有前进指针 forward 设置为 NULL
zsl->header->level[j].forward = NULL;
// 将跳跃表头节点的所有跨度 span 设置为 0
zsl->header->level[j].span = 0;
}
// 跳跃表头节点的后退指针 backward 置为 NULL
zsl->header->backward = NULL;
// 表头指向跳跃表尾节点的指针置为 NULL
zsl->tail = NULL;
return zsl;
}此时,跳表的结构是:
2. 插入元素
现在我们有了一个空的跳表,试着往里面插入一个元素(先忽略具体操作),假设随机出的层高是2,结构变成了这样:

为了演示一般性的插入操作,这里我再往跳表里插入几个元素:
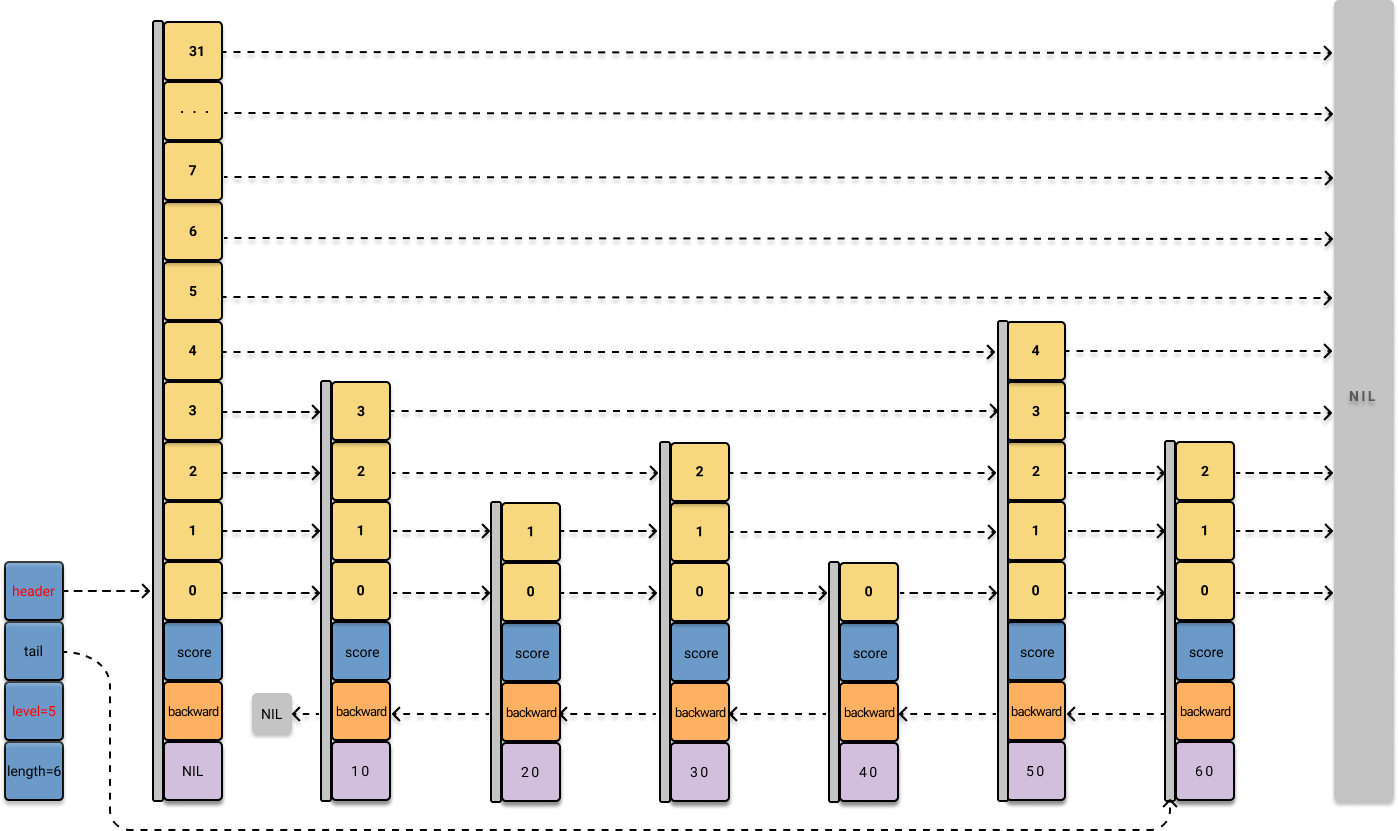
接下来,我们参考源码 t_zset.c/zslInsert,尝试插入一个新元素,假设这个元素的 score = value = 45,那么可以预见,它将被插入到 40 和 50 之间的位置。
一、声明变量
// 存储搜索路径
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 存储经过的节点跨度
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;二、搜索位置
serverAssert(!isnan(score));
x = zsl->header;
// 逐步降级寻找目标节点,得到 "搜索路径"
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 如果 score 相等,还需要比较 value 值
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
// 记录 "搜索路径"
update[i] = x;
}搜索过程中,读到的节点值用红线标出:
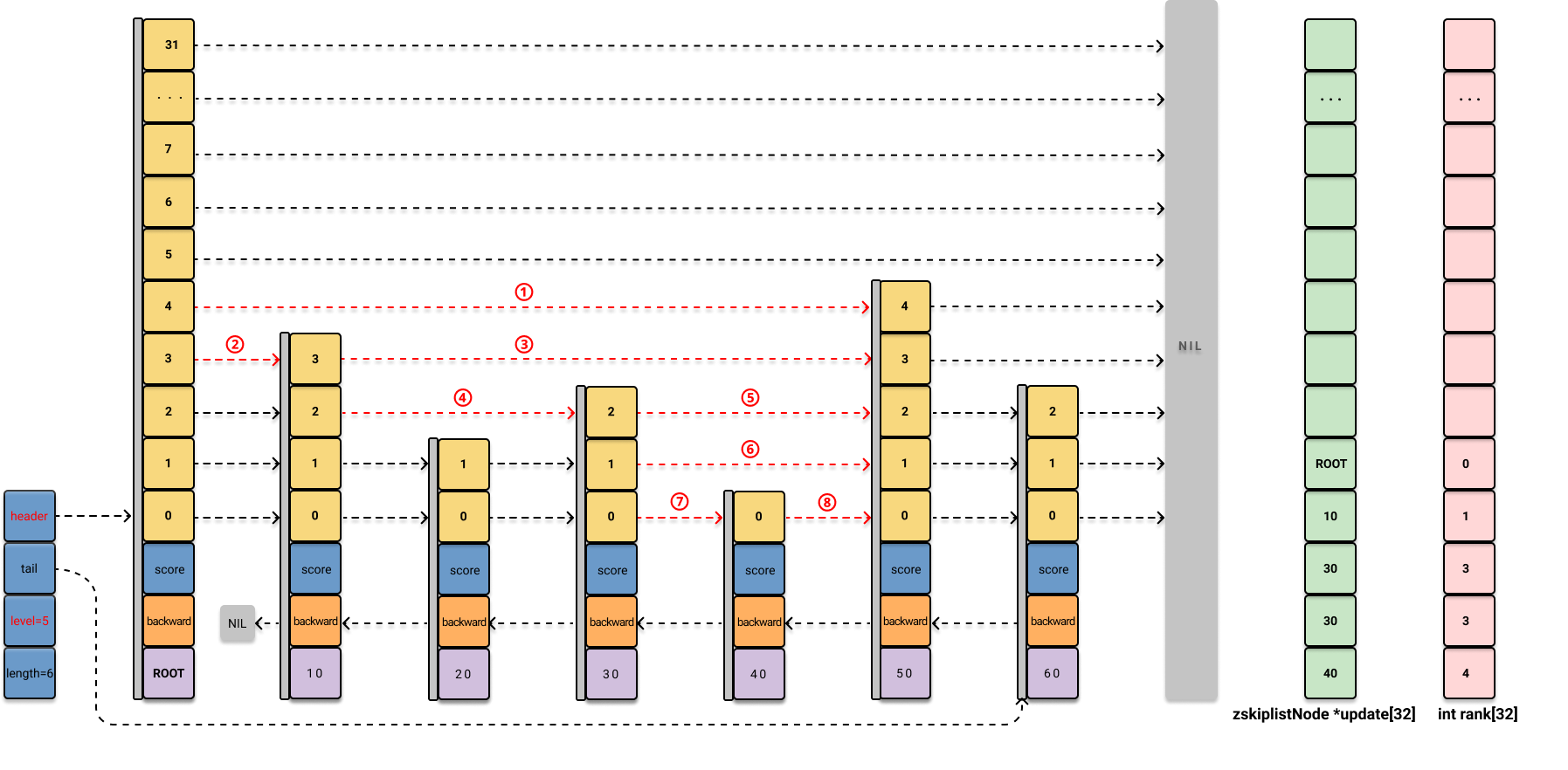
zskiplistNode *update[] 数组存储了搜索过程中,向level数组低一层前进的转折点。最终第五步的时候,会修改这些节点的 forward 指针,将新节点串到 skiplist 中 40-45 之间的位置。
三、生成节点
经过上一步的的处理,我们就知道新节点最终要插入的位置了,也保存了搜索的路径(即 update[]);接下来的操作就类似于链表的插入操作了,我们要把新节点的level[]数组,从低位到高位,依次链到原来的跳表中。
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
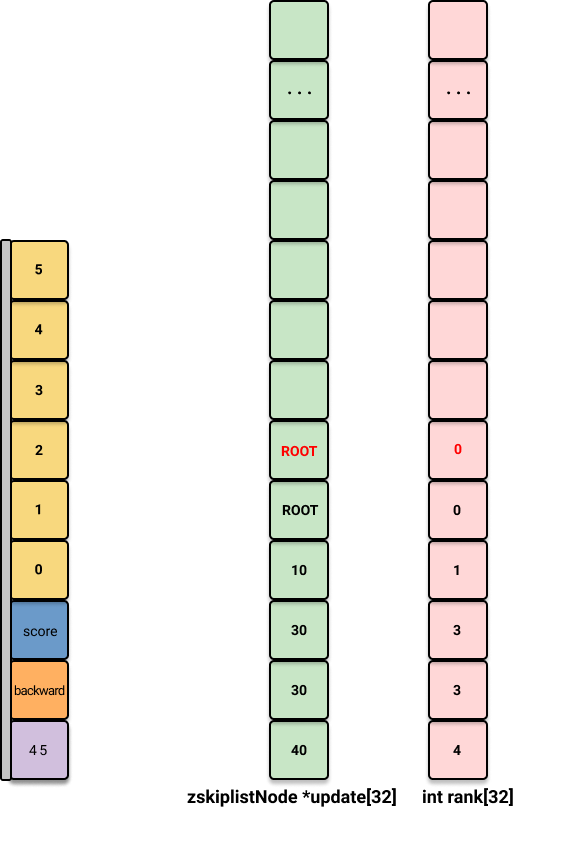
/*
level = zslRandomLevel();
// 如果随机生成的 level 超过了当前最大 level 需要更新跳跃表的信息
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 创建新节点
x = zslCreateNode(level,score,ele);我们假设新节点假设随机生成的 level=6(高于原来的层数5),所以需要手动补充 update[5], 和 span[5] 的信息,用于更新索引和span:
四、重排 forward 指针
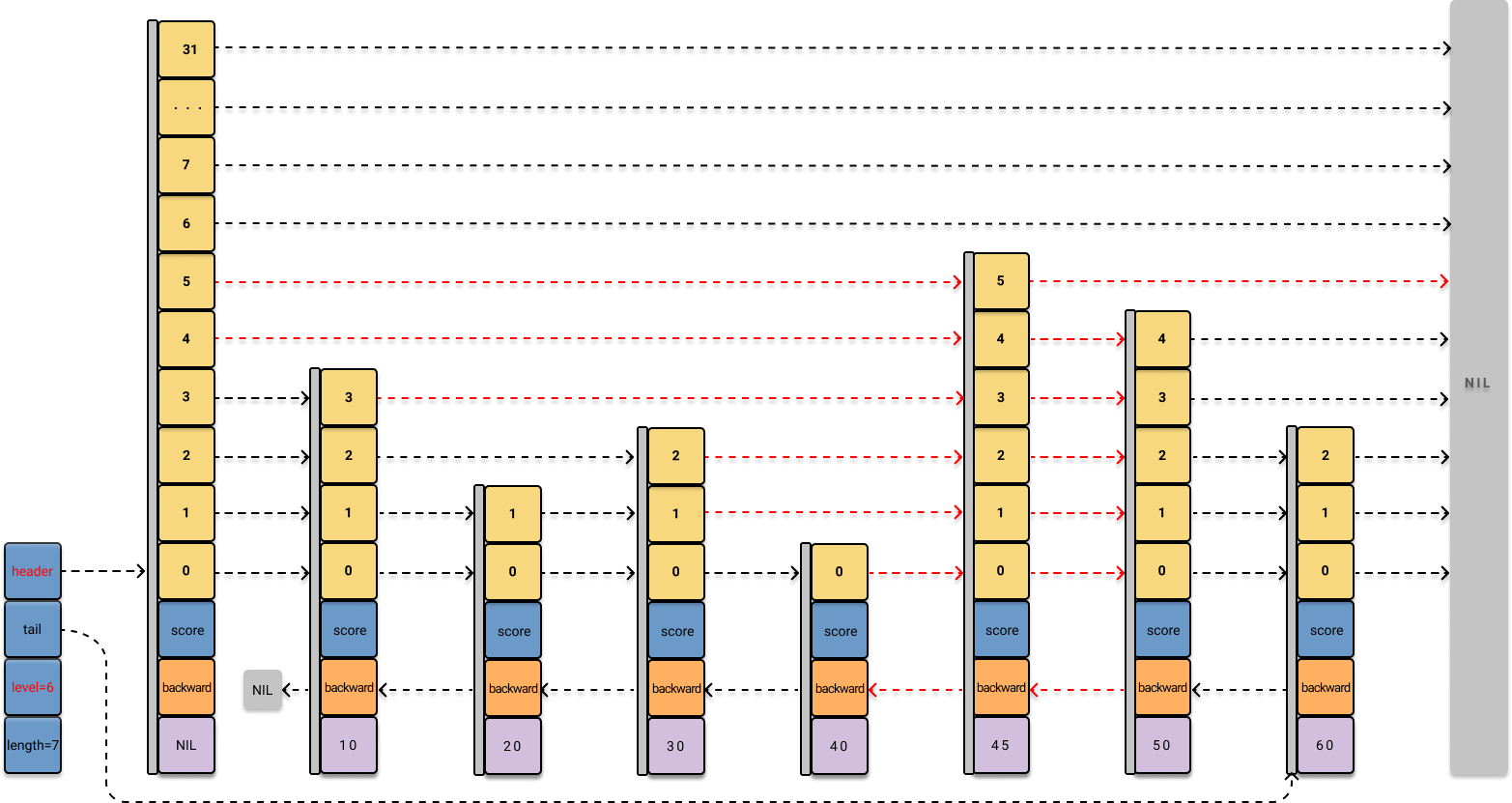
依次更新新节点的 level 数组,从 level[0] 到 level[5],将新节点串到跳表中:
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
五、重排 backward 指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;5. 整数集合 intset
整数集合(intset)是Redis用于保存整数值的集合抽象数据类型,它可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。
定义如下:
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;需要注意的是虽然 contents 数组声明为 int8_t 类型,但是实际上contents 数组并不保存任何 int8_t 类型的值,其真正类型由 encoding 来决定。
6. 压缩列表 ziplist
压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
注意:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域。
压缩列表的结构:

压缩列表的每个节点构成如下:
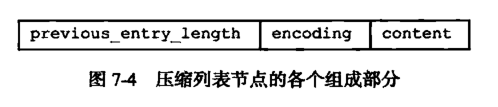
- previous_entry_ength:记录压缩列表前一个字节的长度。保证压缩列表可以从尾部向头部遍历。
- encoding:节点的encoding保存的是节点的content的内容类型以及长度。
- content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。
三、应用层数据结构
Redis每次创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象;Redis中每个对象都是由 redisObject 结构来表示的:
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj- type: 就是 redis 的五大基础数据类型
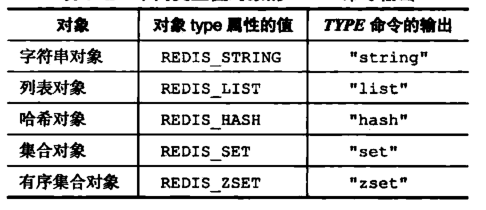
- prt指针: 指向对象底层的数据结构
- encoding: 对象的数据结构(注意下面图片中的部分内容已过时,后文会重新做总结)
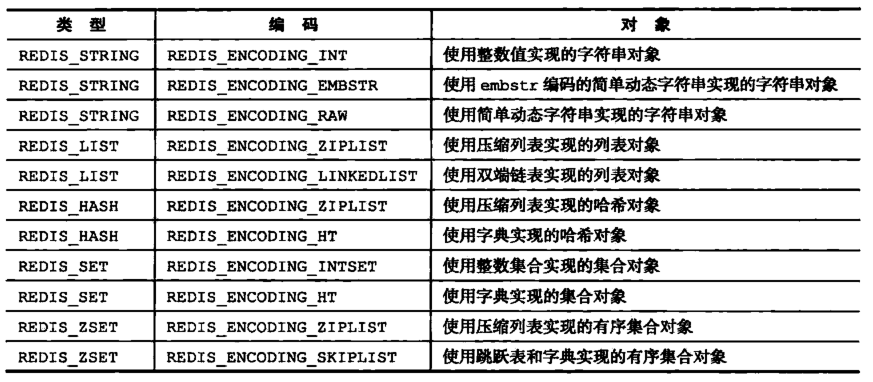
1. 字符串
字符串是Redis最基本的数据类型,不仅所有key都是字符串类型,其它几种数据类型构成的元素也是字符串。注意字符串的长度不能超过512M。
字符串对象的编码可以是int,raw或者embstr。
- int 编码:保存的是可以用 long 类型表示的整数值。
- raw 编码:保存长度大于44字节的字符串。
- embstr 编码:保存长度小于44字节的字符串。
由此可以看出,int 编码是用来保存整数值,raw编码是用来保存长字符串,而embstr是用来保存短字符串。
其实 embstr 编码是专门用来保存短字符串的一种优化编码,它分配了一块连续的内存,用来保存字符串的 redisObject 和 字符串的具体内容,用来减少新增、删除操作时,内存的操作次数。
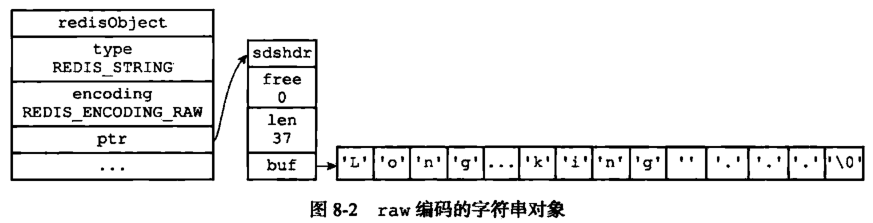
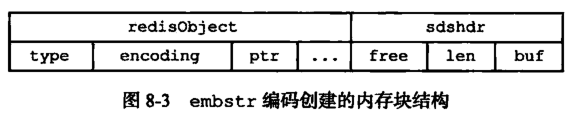
而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。当我们修改一个字符串(比如append)的时候,它的编码就会变为 raw
其实,Redis中对于浮点数类型也是作为字符串保存的,在需要的时候再将其转换成浮点数类型。
Redis 之所以自己构造出了 sds,而不使用 c 中的字符串,主要是由于以下几点考虑:
- SDS 获取长度的复杂度为O(1)
- SDS 可保存二进制数据(通过len来判断长度,而不是'\0')
- SDS 减少内存分配的次数
- SDS api不会造成缓冲区溢出(持有free空间大小)
2. 列表
低版本的 redis 中,列表对象的编码可以是 ziplist(压缩列表) 或 linkedlist(双端链表)。
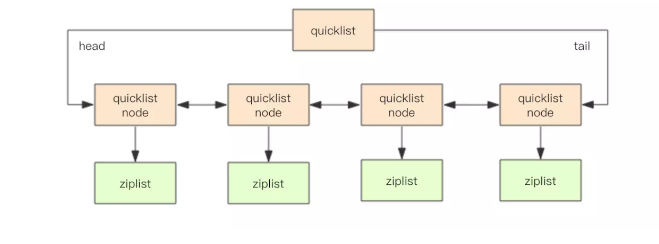
高版本中,redis 使用 quicklist 来作为 list 的底层数据结构。
事实上,quickList 是 zipList 和 链表 的混合体,linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来
3. 哈希
哈希对象的编码可以是 ziplist 或者 hashtable。
当使用ziplist,也就是压缩列表作为底层实现时,新增的键值对是保存到压缩列表的表尾。

当使用 hashtable 编码时,底层使用字典数据结构
当同时满足下面两个条件时,使用ziplist(压缩列表)编码:
- 列表保存元素个数小于512个
- 每个元素长度小于64字节
不能满足这两个条件的时候使用 hashtable 编码。
4. 集合
集合对象的编码可以是 intset 或者 hashtable。
intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
hashtable 编码的集合对象使用 字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值则全部设置为 null。这里可以类比Java集合中HashSet 集合的实现,HashSet 集合是由 HashMap 来实现的,集合中的元素就是 HashMap 的key,而 HashMap 的值都设为 null。
当集合同时满足以下两个条件时,使用 intset 编码:
- 集合对象中所有元素都是整数
- 集合对象所有元素数量不超过512
不能满足这两个条件的就使用 hashtable 编码。
5. 有序集合
有序集合对象是有序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
有序集合的编码可以是 ziplist 或者 skiplist。
ziplist 编码的有序集合,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
skiplist 编码的有序集合,使用 zset 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表:
- 字典的 key 保存元素的值,字典的 value 则保存元素的 score;
- 跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。
四、 总结