在 Linux 系统之中有一个核心武器:epoll 池,在高并发的,高吞吐的 IO 系统中常常见到 epoll 的身影。
IO 多路复用
后台的程序只需要 1 个线程就可以管理多个 fd 句柄,来应对所有的业务方的 IO 请求。这种一对多的 IO 模式我们就叫做 IO 多路复用。
多路是指?多个业务方(句柄)并发下来的 IO 。
复用是指?复用这一个后台线程。
站在 IO 系统设计人员的角度,业务方要创建多个 fd,你就需要负责这些 fd 的处理,并且最好还要并发起来。
业务方没法限制,那么只能后台 loop 程序了,并且要 loop 的非常之快!要让每一个 fd 觉得,你只在给他一个人干活。
最朴实的实现方式?
如果不用任何其他系统调用,能否实现 IO 多路复用?
答案是可以的。
我们写个 for 循环,每次都尝试 IO 一下,读/写到了就处理,读/写不到就 sleep。这样我们不就实现了 1 对多的 IO 多路复用嘛。
while True:
for each 句柄数组 {
read/write(fd, /* 参数 */)
}
sleep(1s)这里有个问题,上面的程序可能会被卡死在第三行,使得整个系统不得运行,为什么?
默认情况下,我们 create 出的句柄是阻塞类型的。我们读数据的时候,如果数据还没准备好,是会需要等待的,当我们写数据的时候,如果还没准备好,默认也会卡住等待。
所以,在上面伪代码第三行是可能被直接卡死,而导致整个线程都得到不到运行。
举个例子,现在有 11,12,13 这 3 个句柄,现在 11 读写都没有准备好,只要 read/write(11, /参数/) 就会被卡住,但 12,13 这两个句柄都准备好了,那遍历句柄数组 11,12,13 的时候就会卡死在前面,后面 12,13 则得不到运行。这不符合我们的预期,因为我们 IO 多路复用的 loop 线程是公共服务,不能因为一个 fd 就直接瘫痪。
那这个问题怎么解决?
只需要把 fd 都设置成非阻塞模式。这样 read/write 的时候,如果数据没准备好,返回 EAGIN 的错误即可,不会卡住线程,从而整个系统就运转起来了。比如上面句柄 11 还未就绪,那么 read/write(11, /参数/) 不会阻塞,只会报个 EAGIN 的错误,这种错误需要特殊处理,然后 loop 线程可以继续执行 12,13 的读写。
以上就是最朴实的 IO 多路复用的实现了。
但它还有一个致命问题:for 循环每次要定期 sleep 1s,导致系统吞吐能力极差。
那不 sleep 了可以吗?这样就能及时处理了。
及时是及时了,但是 CPU 估计要跑飞了。不加 sleep ,那在没有 fd 需要处理的时候,CPU 都要跑到 100% 了。这个也是无法接受的。
纠结了,那 sleep 吞吐不行,不 sleep 浪费 cpu,怎么办?
这种情况下,用户态很难有所作为,只能求助内核来提供机制协助来。因为内核才能及时的管理这些通知和调度。
我们再梳理下 IO 多路复用的需求和原理:
IO 多路复用就是 1 个线程处理 多个 fd 的模式。
要求是:
这个 “1” 就要尽可能的快,避免一切无效工作,要把所有的时间都用在处理句柄的 IO 上,不能有任何空转,sleep 的时间浪费。
有没有一种工具,我们把一箩筐的 fd 放到里面,只要有一个 fd 能够读写数据,后台 loop 线程就要立马唤醒,全部马力跑起来。其他时间则要把 cpu 让出去。
Linux 内核
这时候只能依赖 Linux 内核了,毕竟 IO 的处理都是内核之中,数据好没好内核最清楚。
内核一口气提供了 3 种工具 select,poll,epoll 。
为什么有 3 种?
历史不断改进,矬 -> 较矬 -> 高效 的演变而已。
这 3 种工具都能够管理 fd 的读写事件,在所有 fd 不可读不可写无所事事的时候,可以阻塞线程,切走 cpu。fd 有情况的时候,都要线程能够要能被唤醒。
select
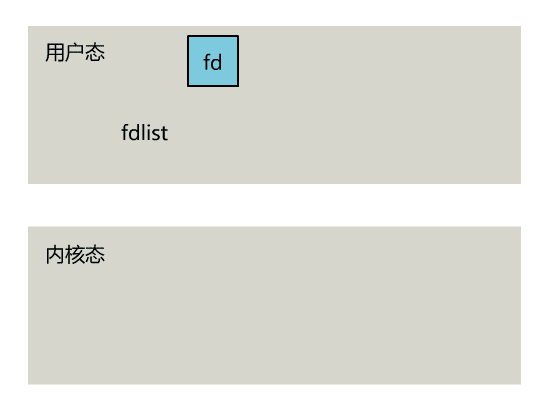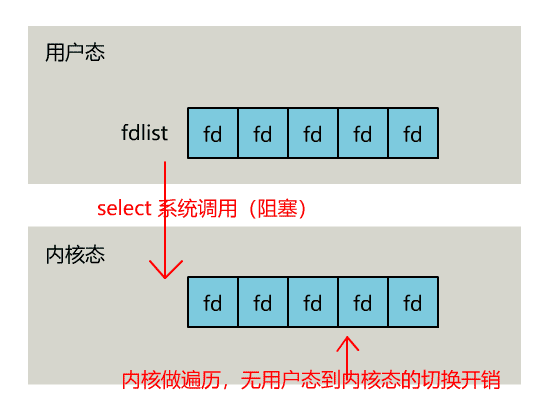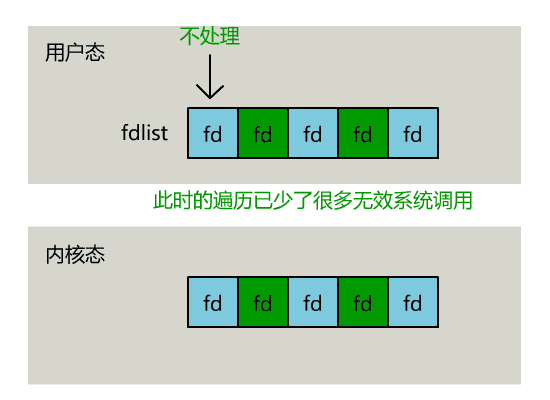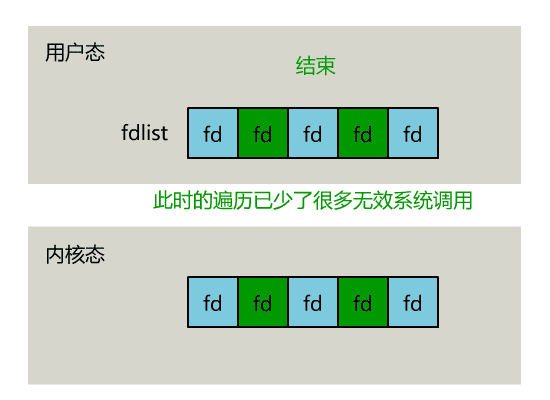
当用户process调用select的时候,
- select会将需要监控的read fd集合拷贝到内核空间(假设监控的仅仅是socket可读)
- 然后遍历自己监控的socket,挨个调用socket的poll逻辑以便检查该socket是否有可读事件,
- 遍历完所有的socket后,如果没有任何一个socket可读,那么select会调用schedule_timeout进入schedule循环,使得process进入睡眠。
- 如果在timeout时间内某个socket上有数据可读了,或者等待timeout了,则调用select的process会被唤醒,接下来select就是遍历监控的socket集合,挨个收集可读事件并返回给用户了
通过上面的select逻辑过程分析,相信大家都意识到,select存在三个问题:
- 每次调用select,都需要把被监控的fds集合从用户态空间拷贝到内核态空间,高并发场景下这样的拷贝会使得消耗的资源是很大的。
- 能监听端口的数量有限,单个进程所能打开的最大连接数有FD_SETSIZE宏定义限制,当然我们可以对宏FD_SETSIZE进行修改,然后重新编译内核,但是性能可能会受到影响,一般该数和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。
- 被监控的fd集合中,只要有一个有数据可读,整个socket集合就会被遍历一次调用socket的poll函数收集可读事件:由于当初的需求是朴素,仅仅关心是否有数据可读这样一个事件,当事件通知来的时候,由于数据的到来是异步的,我们不知道事件来的时候,有多少个被监控的socket有数据可读了,于是,只能挨个遍历每个socket来收集可读事件了。
poll
select/poll的差异
select与poll本质上基本类似,其中select是由BSD UNIX引入,poll由SystemV引入;
select与poll需要轮询文件描述符集合,并在用户态和内核态之间进行拷贝,在文件描述符很多的情况下开销会比较大,select默认支持的文件描述符数量是1024;
poll的实现和select非常相似,只是描述fd集合的方式不同。
针对select遗留的三个问题中,(问题2是fd限制问题,问题1和3则是性能问题),poll只是使用pollfd结构而不是select的fd_set结构,这就解决了select的问题2 fd集合大小限制问题。
但poll和select同样存在一个性能缺点,就是包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大;
同时,个别描述符就绪仍会触发整体描述符集合的遍历。poll随着监控的socket集合的增加性能线性下降,使得poll也并不适合用于大并发场景。
细说 epoll
我们举个例子来对比 select 和 epoll:假设池子里管理了 1024 个句柄,loop 线程被唤醒的时候,select 都是蒙的,都不知道这 1024 个 fd 里谁 IO 准备好了。这种情况只能遍历这 1024 个 fd ,一个个测试。假如只有一个句柄准备好了,那相当于做了 1 千多倍的无效功。
epoll 则不同,从 epoll_wait 醒来的时候就能精确的拿到就绪的 fd 数组,不需要任何测试,拿到的就是要处理的。
事实上,epoll 之所以高效是因为:
- 内部管理 fd 使用了高效的红黑树结构管理,做到了增删改之后性能的优化和平衡;
- 通过事件通知的形式(回调),做到最高效的运行,而不是像 select/poll 一样轮训它们管理的所有 socket
接下来,我们举一个使用了 epoll 的简单示例(只是个例子,实践中不这么写):
int main(){
listen(lfd, ...);
cfd1 = accept(...);
efd = epoll_create(...);
epoll_ctl(efd, EPOLL_CTL_ADD, cfd1, ...);
epoll_wait(efd, ...)
}
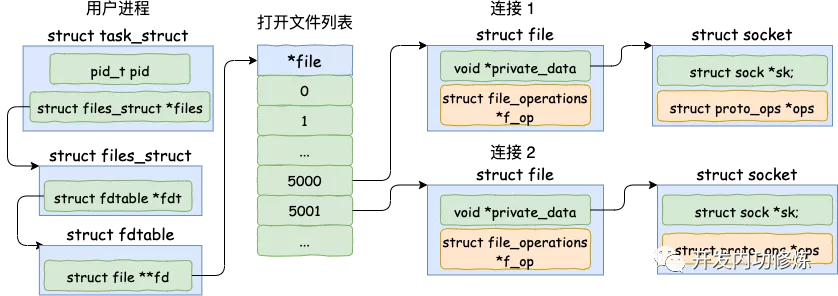
1. accept 创建新的 socket
cfd1 = accept(...);当 accept 之后,进程会创建一个新的 socket 出来,专门用于和对应的客户端通信,然后把它放到当前进程的打开文件列表中
- 根据 fd 查找到要监听的 socket
- 申请并初始化新的 socket;将 sock->ops 赋给新 socket
- 申请新的 file 对象,将其赋给上一步的 socket
- 调用 socket 的 accept 方法接收连接
- 添加新文件到当前进程的打开文件列表
完成后的结构图如下:
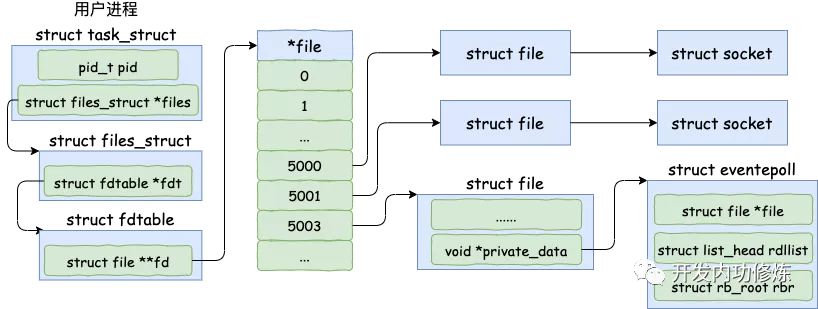
2. epoll_create 实现
efd = epoll_create(...);在用户进程调用 epoll_create 时,内核会创建一个 struct eventpoll 的内核对象。并同样把它关联到当前进程的已打开文件列表中
- 新建 eventpoll 对象
- 初始化等待队列链表 wq。(软中断数据就绪的时候会通过 wq 来找到阻塞在 epoll 对象上的用户进程,这个过程下文会详细说明)
- 初始化就绪队列链表 rdllist。当有连接就绪的时候,内核会把就绪的连接放到 rdllist 链表里。这样应用进程只需要判断链表就能找出就绪的用户进程,而不用去遍历整棵树。
- 初始化红黑树 rbr。用来管理添加进来的 socket,红黑树的节点就是 epitem
结构图如下:
其中 eventpoll 对象的结构如下:
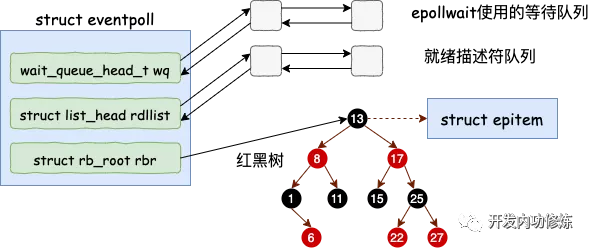
3. epoll_ctl 添加 socket
epoll_ctl(efd, EPOLL_CTL_ADD, cfd1, ...);epoll_ctl 可以控制对象的添加、删除等,这里以添加为例进行讨论
- 创建一个红黑树节点对象 epitem,
- 创建一个等待事件到 socket 对象的等待队列中,其回调函数是 ep_poll_callback,还包含上一步创建的 epitem 的引用
- 将 epitem 插入到 epoll 对象的红黑树里
通过 epoll_ctl 添加两个 socket 以后,这些内核数据结构最终在进程中的关系图大致如下:
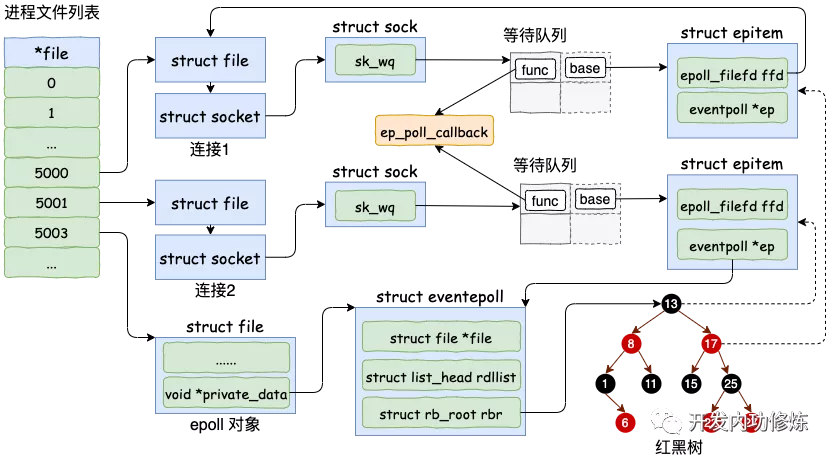
这里需要注意一下上面的第二步,socket 的等待队列中,包含着 epoll 的红黑树节点 epitem 的引用,正是由于这个引用的存在,才能完成 IO事件 - socket - epoll - 唤醒用户进程 的调用流程。
4. epoll_wait 等待接收
epoll_wait(efd, ...)epoll_wait 做的事情不复杂,当它被调用时它观察 eventpoll->rdllist 链表里有没有数据即可。有数据就返回,没有数据就创建一个等待队列项,将其添加到 eventpoll 的等待队列上,然后把自己阻塞掉就完事
- 判断就绪队列上有没有事件就绪
- 假设确实没有就绪的连接,则创建一个 waitqueue 的 entry,并把 current (当前进程的引用)添加到 entry 上
- 把等待事件(上一步的 entry)添加到 epoll 对象的等待队列中
- 让出CPU 主动进入睡眠状态
注意:epoll_ctl 添加 socket 时也创建了等待队列项。不同的是这里的等待队列是属于 epoll 对象的,而前者是属于 socket 对象的。
是的,当没有 IO 事件的时候, epoll 也是会阻塞掉当前进程。这个是合理的,因为没有事情可做了占着 CPU 也没啥意义。epoll 本身是阻塞的,但一般会把 socket 设置成非阻塞。
5. 数据来了
在前面 epoll_ctl 执行的时候,内核为每一个 socket 上都添加了一个等待队列项。在 epoll_wait 运行完的时候,又在 event poll 对象上添加了等待队列元素。在讨论数据开始接收之前,我们把这些队列项的内容再稍微总结一下。
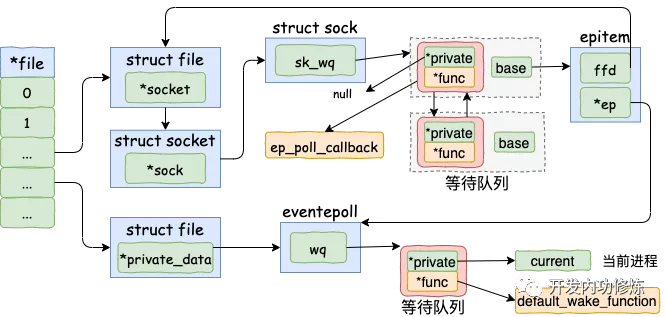
- 在 socket 的等待队列项中,其回调函数是 ep_poll_callback。另外其 private 没有用了,指向的是空指针 null(本来应该指向用户进程,当 IO 事件触发的时候,就通过这个指针来唤醒用户进程,但是现在由 epoll 来处理整个流程了,所以设置为 null)。
- 在 eventpoll 的等待队列项中,回调函数是 default_wake_function。其 private 指向的是等待该事件的用户进程(epoll 就是通过这个指针,找到并唤醒用户进程的)。
在这一小节里,我们将看到从网卡接受数据,直到用户进程被唤醒的全部流程。
首先,网卡接收到数据后,到tcp 协议栈处理前,需要经过以下步骤,参考《图解Linux网络包接收过程》:
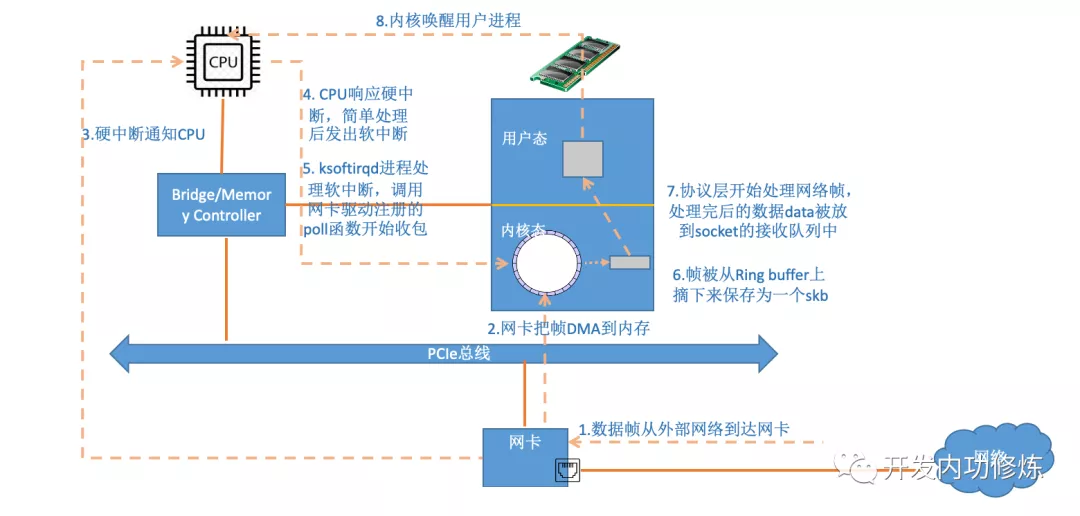
- 数据包抵达网卡,网卡把帧存入内存 RingBuffer,硬中断通知 cpu
- cpu 调用网卡启动时注册的中断函数
- 中断函数不做过多处理,发出软中断请求
- 内核线程 ksoftirqd 线程发现软中断请求,先关闭硬中断,让出 cpu
- ksoftirqd 线程开始调用驱动的 poll 函数收包
- poll 函数将收到的包送到协议栈注册的 ip_rcv 函数中
- ip_rcv函数再讲包送到 udp_rcv 函数中(对于tcp包就送到tcp_rcv)
接下来,我们将看到软中断是怎么样在数据处理完之后依次进入各个回调函数,最后通知到用户进程的。它的大体流程是这样的
- 有数据到来
- 激活 socket
- 通过回调 ep_poll_callback 查找并激活 epoll
- 通过回调 default_wake_function 查找并激活用户线程
我们直接从 tcp 协议栈的处理入口函数 tcp_v4_rcv 开始说起:
1. 接收数据到任务队列
- 在 tcp_v4_rcv 中首先根据收到的网络包的 header 里的 source 和 dest 信息来在本机上查询对应的 socket
- 将接收到的数据放到 socket 的接收队列的尾部
2. 查找就绪回调函数
查找在 socket 上等待的对象:socket 上数据就绪的时候(收到软中断?),会调用 socket 创建的时候注册的 sk_data_ready 函数,来唤醒在 sock 上等待的进程。具体步骤如下:
- 检测 socket 的等待队列 wq 是否有元素
- 调用上一步拿到的 wq item 的 func 方法(即 ep_poll_callback 方法。ep_insert 调用的时候,把这个 func 设置成 ep_poll_callback)
3. 执行 socket 就绪回调函数
即 ep_poll_callback 方法:
- 获取对应的 epitem
- 获取 epitem 指向的 eventpoll
- 将 epitem 添加到 eventpoll 的就绪队列 rdllist 中(rdllist 中的对象是 epitem,其中保存着 socket 的 fd 和 eventpoll 对象)
- 查看 eventpoll 的等待队列上是否有在等待,如果没有,那么执行软中断的事情就做完了(说明当前没有任何用户进程需要这个 socket 的数据,不需要通知任何用户进程)。如果有等待项,那就查找到等待项里设置的回调函数 default_wake_function,预备通知等待项,执行 epoll 就绪通知
4. 执行 epoll 就绪通知
唤醒在 socket上等待的用户进程。
- 找到 epoll 等待队列 wq 中的表项 entry,其中存储着进程描述符
- 将用户进程(被 epoll_wait 阻塞)推入可运行队列,等待内核重新调度进程。
- 当进程醒来后,继续从 epoll_wait 时暂停的代码继续执行。把 rdlist 中就绪的事件返回给用户进程
从用户角度来看,epoll_wait 只是多等了一会儿而已,但执行流程还是顺序的。
6. 总结
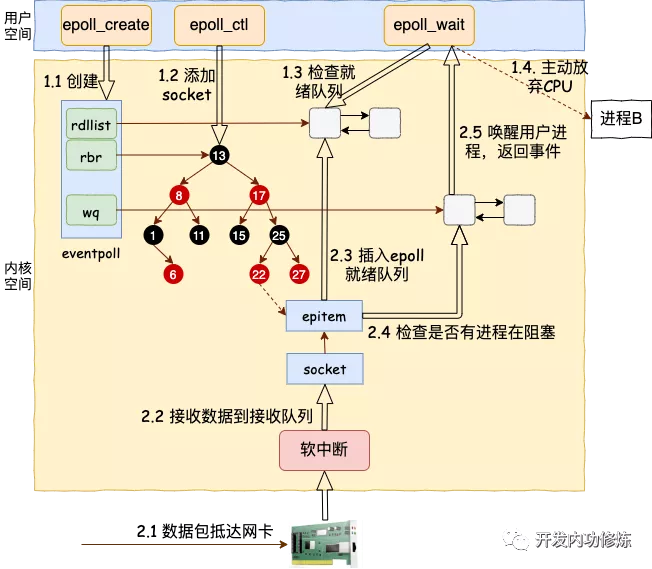
为了介绍到每个细节,本文涉及到的流程比较多,把阻塞都介绍进来了。
但其实在实践中,只要活儿足够的多,epoll_wait 根本都不会让进程阻塞。用户进程会一直干活,一直干活,直到 epoll_wait 里实在没活儿可干的时候才主动让出 CPU。这就是 epoll 高效的地方所在!
参考
https://mp.weixin.qq.com/s/OmRdUgO1guMX76EdZn11UQ
https://zhuanlan.zhihu.com/p/367591714
