目前,Redis 的持久化主要有两大机制,即 AOF(Append Only File)日志和 RDB 快照。
一、 AOF
说到日志,我们比较熟悉的是数据库的写前日志(Write Ahead Log, WAL)(redolog,binlog等),也就是说,在实际写数据前,先把修改的数据记到日志文件中,以便故障时进行恢复。不过,AOF 日志正好相反,它是写后日志,“写后”的意思是 Redis 是先执行命令,把数据写入内存,然后才记录日志。
那 AOF 为什么要先执行命令再记日志呢?要回答这个问题,我们要先知道 AOF 里记录了什么内容。
传统数据库的日志,例如 redo log(重做日志),记录的是修改后的数据,而 AOF 里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的。
我们以 Redis 收到“set testkey testvalue”命令后记录的日志为例,看看 AOF 日志的内容。其中,“*3”表示当前命令有三个部分,每部分都是由“$+数字”开头,后面紧跟着具体的命令、键或值。这里,“数字”表示这部分中的命令、键或值一共有多少字节。例如,“$3 set”表示这部分有 3 个字节,也就是“set”命令。
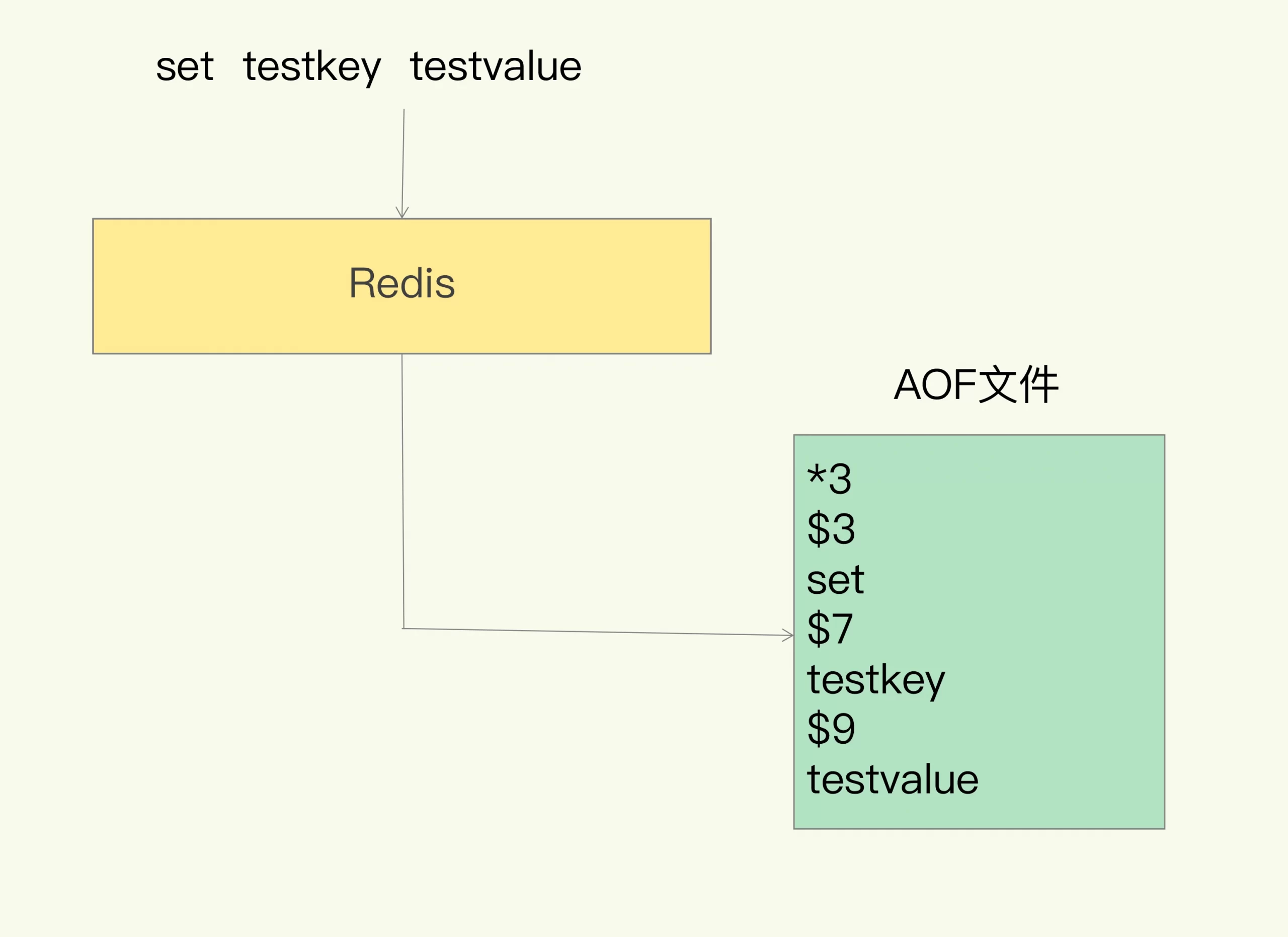
但是,为了避免额外的检查开销,Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误的命令,Redis 在使用日志恢复数据时,就可能会出错。
而写后日志这种方式,就是先让系统执行命令,只有命令能执行成功,才会被记录到日志中,否则,系统就会直接向客户端报错。所以,Redis 使用写后日志这一方式的一大好处是,可以避免出现记录错误命令的情况。
除此之外,AOF 还有一个好处:它是在命令执行后才记录日志,所以不会阻塞当前的写操作。
既然是“后写”日志,那么就存在两个问题:
- 如果刚执行完一个命令,还没来得及写日志,redis 就宕机了,这时候,就丢掉了最后一条数据。
- AOF 是在主线程中执行的,如果把日志写入磁盘的时候,发生了阻塞,就会降低整个 redis 的响应时间,甚至影响 redis 的正常使用。
1. 三种回写策略
对于这两个问题,redis 为我们提供了三种处理方案,也就是 AOF 的配置项 appendfsync 的三个可选值。
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
这三种策略,可靠性由高到低,性能由低到高。这里需要注意的一点是,即便是可靠性最高的 always,也是有可能丢掉最后一条数据的。
即便按照我们的需求选定了写回策略,也并不是“高枕无忧”了。毕竟,AOF 是以文件的形式在记录接收到的所有写命令。随着接收的写命令越来越多,AOF 文件会越来越大。这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题。
这里的问题是指:
- 文件系统本身对文件大小的限制
- 如果发生宕机,AOF 中的命令要依次执行一遍,日过日志文件过大,过程会非常缓慢
为了解决这个问题,redis 提供了 AOF 重写机制
2. AOF 重写
由于 AOF 文件是以追加的方式,逐一记录接收到的写命令的。当一个键值对被多条写命令反复修改时,AOF 文件会记录相应的多条命令。
所以只需要在重写的时候,根据这个键值对当前的最新状态,为它生成对应的写入命令。这样一来,一个键值对在重写日志中只用一条命令就行了,而且,在日志恢复时,只用执行这条命令,就可以直接完成这个键值对的写入了。
不过,虽然 AOF 重写后,日志文件会缩小,但是,要把整个数据库的最新数据的操作日志都写回磁盘,仍然是一个非常耗时的过程。这时,我们就要继续关注另一个问题了:重写会不会阻塞主线程?
答案是:不会。和 AOF 日志由主线程写回不同,重写过程是由后台子进程 bgrewriteaof 来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。
这里先补充两个知识点:
页表,属于操作系统的知识范畴,可以参考下面这两篇文章:
https://zhuanlan.zhihu.com/p/393005902
https://zhuanlan.zhihu.com/p/270577411写时复制(Copy On Write):
https://blog.csdn.net/qq_32131499/article/details/94561780
我们再回到 AOF 重写的过程:
每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的页表等拷贝一份给 bgrewriteaof 子进程;通过操作系统的 fork 机制,保证了子进程可以访问数据库的全量数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
-
这个过程中,如果 redis 收到读命令,则对父、子进程,都没有任何影响。
-
这个过程中,如果 redis 收到写命令,则依赖上文提到的 写时复制(Copy On Write)机制,父进程将 copy 一份需要修改的 page,在新的 page 上做变更,同时修改自己的页表,指向新的 page,然后写 aof 日志。同时,子进程也会同样处理这条命令,并写自己的 aof 日志。
fork这个瞬间一定是会阻塞主线程的。注意,fork时并不会一次性拷贝所有内存数据给子进程,,fork采用操作系统提供的写实复制(Copy On Write)机制,就是为了避免一次性拷贝大量内存数据给子进程造成的长时间阻塞问题,但fork子进程需要拷贝进程必要的数据结构,其中有一项就是拷贝内存页表(虚拟内存和物理内存的映射索引表),这个拷贝过程会消耗大量CPU资源,拷贝完成之前整个进程是会阻塞的,阻塞时间取决于整个实例的内存大小,实例越大,内存页表越大,fork阻塞时间越久。
另外,在 aof rewrite 过程中,会做 page 的拷贝,因此如果操作系统开启了内存大页机制(huge page),则会对整体的性能造成影响。因此,运行 redis 的机器,是不推荐开启 huge page 选项的。
相应的,如果 redis 中存在 bigkey,重新申请大块内存耗时会变长,也是有可能会产阻塞风险的。
3. 源码阅读
1. 用户命令
redis 在处理客户端的用户命令之后,通过下面的 propagate 方法,将命令传递给 aof 和 slave:
/* 将命令传播给 AOF 和 Slaves.
*
* flags are an xor between:
* + PROPAGATE_NONE (no propagation of command at all)
* + PROPAGATE_AOF (propagate into the AOF file if is enabled)
* + PROPAGATE_REPL (propagate into the replication link)
*
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
······
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
// 将命令传递给 aof
feedAppendOnlyFile(cmd,dbid,argv,argc);
if (flags & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}从 redisServer 的结构中,我们可以看到,aof buffer 的结构,其实就是一个 sds 字符串:
struct redisServer {
sds aof_buf; /* AOF buffer, written before entering the event loop */
};下面是 feedAppendOnlyFile 的具体实现:
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
sds buf = sdsempty();
/* 确定当前命令选定的 db */
if (dictid != server.aof_selected_db) {
char seldb[64];
snprintf(seldb,sizeof(seldb),"%d",dictid);
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n",
(unsigned long)strlen(seldb),seldb);
server.aof_selected_db = dictid;
}
/* 下面这一大段if else,主要是将命令做一定的转换,方便 redis 处理,暂时可以不用追究其中的细节 */
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand ||
cmd->proc == expireatCommand) {
// 将 EXPIRE/PEXPIRE/EXPIREAT 转换成 PEXPIREAT
// 这几个 expire 命令,其实都是调用的 expireGenericCommand() 方法,只不过是参数有区别罢了
buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]);
} else if (cmd->proc == setCommand && argc > 3) {
robj *pxarg = NULL;
/* When SET is used with EX/PX argument setGenericCommand propagates them with PX millisecond argument.
* So since the command arguments are re-written there, we can rely here on the index of PX being 3. */
if (!strcasecmp(argv[3]->ptr, "px")) {
pxarg = argv[4];
}
/* For AOF we convert SET key value relative time in milliseconds to SET key value absolute time in
* millisecond. Whenever the condition is true it implies that original SET has been transformed
* to SET PX with millisecond time argument so we do not need to worry about unit here.*/
if (pxarg) {
robj *millisecond = getDecodedObject(pxarg);
long long when = strtoll(millisecond->ptr,NULL,10);
when += mstime();
decrRefCount(millisecond);
robj *newargs[5];
newargs[0] = argv[0];
newargs[1] = argv[1];
newargs[2] = argv[2];
newargs[3] = shared.pxat;
newargs[4] = createStringObjectFromLongLong(when);
buf = catAppendOnlyGenericCommand(buf,5,newargs);
decrRefCount(newargs[4]);
} else {
buf = catAppendOnlyGenericCommand(buf,argc,argv);
}
} else {
buf = catAppendOnlyGenericCommand(buf,argc,argv);
}
/* 将命令追加到 AOF buffer 中,aof buffer 中的内容,会在下一次事件循环中被写到 aof file 中 */
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
/* 如果 background aof rewrite 正在执行,
* 还需要把命令追加到 aof rewrite buffer 中 */
if (server.child_type == CHILD_TYPE_AOF)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
sdsfree(buf);
}大体流程如下图所示:

2. AOF 写入磁盘
上一篇文章中,我们了解了 ae 事件框架,在处理事件循环的时候,会调用 beforeSleep 方法;正是在这个 beforeSleep 方法中,完成了 aof 的刷盘操作。

注意这个图片中绿色文字所在的两个分支,如果下一个 event 一直不来临,那么就不会触发 beforeSleep(),难道就永远不会去刷盘了吗?
不是的;这种情况下,serverCron() 会帮我们做补偿,当它检测到此种情况出现,就会去调用 flushAppendOnlyFile() 刷盘,由于 serverCron() 默认执行频率是 100ms/次,所以我们最多会丢 2s + 100ms = 2100ms 的数据。
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
······
/* 调用 before sleep 方法. */
if (eventLoop->beforesleep != NULL && flags & AE_CALL_BEFORE_SLEEP)
eventLoop->beforesleep(eventLoop);
······
/* 调用多路复用 api,比如 epoll
* Call the multiplexing API, will return only on timeout or when
* some event fires. */
numevents = aeApiPoll(eventLoop, tvp);
······
/* 调用 after sleep 方法. */
if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP)
eventLoop->aftersleep(eventLoop);
······
return processed; /* return the number of processed file/time events */
}接下来看看 beforesleep 的具体实现:
/* This function gets called every time Redis is entering the
* main loop of the event driven library, that is, before to sleep
* for ready file descriptors.
*
* 注意,一般情况下,此方法的调用方有两个:
* 1. aeMain - 主事件循环
* 2. processEventsWhileBlocked - Process clients during RDB/AOF load
* 在调用方是 processEventsWhileBlocked 的时候,有些工作是不需要做的,比如淘汰过期 key
*/
void beforeSleep(struct aeEventLoop *eventLoop) {
UNUSED(eventLoop);
····
/* Handle precise timeouts of blocked clients. */
handleBlockedClientsTimeout();
/* We should handle pending reads clients ASAP after event loop. */
handleClientsWithPendingReadsUsingThreads();
/* Handle TLS pending data. (must be done before flushAppendOnlyFile) */
tlsProcessPendingData();
/* If tls still has pending unread data don't sleep at all. */
aeSetDontWait(server.el, tlsHasPendingData());
······
/* 如果开启了 aof 的话,在这里执行刷盘操作 */
if (server.aof_state == AOF_ON)
flushAppendOnlyFile(0);
/* Handle writes with pending output buffers. */
handleClientsWithPendingWritesUsingThreads();
/* Close clients that need to be closed asynchronous */
freeClientsInAsyncFreeQueue();
}
flushAppendOnlyFile() 的主要工作,就是把 aof buffer 中的内容,写到 aof file,并 fsync 到磁盘上:
/* 把 append only file buffer 写到磁盘上
*
* 因为
* 1. 我们要先写 aof,再响应 client,
* 2. client socket 唯一的能写数据的机会就是进入 event loop 的时候
* 所以,我们要在下一次进入 event loop 之前,(即调用 epoll_wait之前,通过 beforeSleep()方法)
* 把所有的 aof 写请求,放入内存 buffer,然后写进磁盘
*
* 关于参数 force,
* force = 1 表示要强制刷盘;只在 1.关闭 AOF 2.关机 的时候使用
* force = 0 表示不要强制刷盘;当刷盘(fsync)策略为 everysec 每秒一次的时候,
* 如果后台已经在跑 fsync 操作了,那么这里的 fsync 可能会延迟,导致 buffer 中会遗留一些数据没有刷盘,
* 这些数据最终在 serverCron 中被处理掉
* 例如:Linux 的系统调用 write(2) 就会被后台的 fsync 阻塞
*
*/
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
if (sdslen(server.aof_buf) == 0) {
/* Check if we need to do fsync even the aof buffer is empty,
* because previously in AOF_FSYNC_EVERYSEC mode, fsync is
* called only when aof buffer is not empty, so if users
* stop write commands before fsync called in one second,
* the data in page cache cannot be flushed in time. */
if (server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.aof_fsync_offset != server.aof_current_size &&
server.unixtime > server.aof_last_fsync &&
!(sync_in_progress = aofFsyncInProgress())) {
goto try_fsync;
} else {
return;
}
}
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = aofFsyncInProgress();
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
/* With this append fsync policy we do background fsyncing.
* If the fsync is still in progress we can try to delay
* the write for a couple of seconds. */
if (sync_in_progress) {
if (server.aof_flush_postponed_start == 0) {
/* No previous write postponing, remember that we are
* postponing the flush and return. */
server.aof_flush_postponed_start = server.unixtime;
return;
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
/* We were already waiting for fsync to finish, but for less
* than two seconds this is still ok. Postpone again. */
return;
}
/* Otherwise fall trough, and go write since we can't wait
* over two seconds. */
server.aof_delayed_fsync++;
serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
/* 执行 write 操作. 它的原子性由操作系统保证.
* 当然,如果出现像断电这样的不可抗现象,那么 AOF 文件也是可能会出现问题的
* 这时候就可以用 redis-check-aof 程序来进行修复 */
/* 测试用:aof_flush_sleep:Micros to sleep before flush. (used by tests) */
if (server.aof_flush_sleep && sdslen(server.aof_buf)) {
usleep(server.aof_flush_sleep);
}
/* 用于记录 event 执行的时间 */
latencyStartMonitor(latency);
/* 把 buffer 中的内容写 aof 文件的内存缓冲区 */
/* 下面这段是 aofWrite 的方法注释,没太看懂,后面有时间再深究下*/
/* This is a wrapper to the write syscall in order to retry on short writes
* or if the syscall gets interrupted. It could look strange that we retry
* on short writes given that we are writing to a block device: normally if
* the first call is short, there is a end-of-space condition, so the next
* is likely to fail. However apparently in modern systems this is no longer
* true, and in general it looks just more resilient to retry the write. If
* there is an actual error condition we'll get it at the next try. */
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
latencyEndMonitor(latency);
/* 记录延迟的原因(用于监控/画图) */
if (sync_in_progress) {
latencyAddSampleIfNeeded("aof-write-pending-fsync",latency);
} else if (hasActiveChildProcess()) {
latencyAddSampleIfNeeded("aof-write-active-child",latency);
} else {
latencyAddSampleIfNeeded("aof-write-alone",latency);
}
latencyAddSampleIfNeeded("aof-write",latency);
/* 写 aof file 完成,重置延迟记录器为 0*/
server.aof_flush_postponed_start = 0;
/* 记录错误日志:
* 正常情况下,buffer 中的内容会被全部写到 aof 缓冲区中。
* 如果 buffer 中的内容长度,和实际写入 aof 缓冲区的长度不一致,需要记录错误日志*/
if (nwritten != (ssize_t)sdslen(server.aof_buf)) {
static time_t last_write_error_log = 0;
int can_log = 0;
/* Limit logging rate to 1 line per AOF_WRITE_LOG_ERROR_RATE seconds. */
if ((server.unixtime - last_write_error_log) > AOF_WRITE_LOG_ERROR_RATE) {
can_log = 1;
last_write_error_log = server.unixtime;
}
/* 记录错误日志 */
if (nwritten == -1) {
// buffer 中的内容一个字都没写进去
if (can_log) {
serverLog(LL_WARNING,"Error writing to the AOF file: %s",
strerror(errno));
server.aof_last_write_errno = errno;
}
} else {
// buffer 中的内容没写完
if (can_log) {
serverLog(LL_WARNING,"Short write while writing to "
"the AOF file: (nwritten=%lld, "
"expected=%lld)",
(long long)nwritten,
(long long)sdslen(server.aof_buf));
}
// 尝试移除(由操作系统造成的,比如断电)新追加的不完整内容
if (ftruncate(server.aof_fd, server.aof_current_size) == -1) {
if (can_log) {
serverLog(LL_WARNING, "Could not remove short write "
"from the append-only file. Redis may refuse "
"to load the AOF the next time it starts. "
"ftruncate: %s", strerror(errno));
}
} else {
/* 如果 ftruncate() 移除成功,那就当本次 write error 没发生过,下个循环再重试。
* -1 since there is no longer partial data into the AOF. */
nwritten = -1;
}
server.aof_last_write_errno = ENOSPC;
}
/* 处理写入 AOF 文件时出现的错误. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* fsync 策略是 ALWAYS 时,我们是先处理了客户端请求,再次进入 eventLoop 时才写 aof 的
* 所以,这个时候如果写 aof 异常,我们只能关闭 redis */
serverLog(LL_WARNING,"Can't recover from AOF write error when the AOF fsync policy is 'always'. Exiting...");
exit(1);
} else {
// 如果 ftruncate 移除失败,nwritten > 0,buffer 中剩下的内容,下个循环再尝试写剩下的内容。
// 如果 ftruncate 移除成功,那就当本次 write error 没发生过,下个循环再重试。
server.aof_last_write_status = C_ERR;
if (nwritten > 0) {
server.aof_current_size += nwritten;
sdsrange(server.aof_buf,nwritten,-1);
}
return; /* We'll try again on the next call... */
}
} else {
/* Successful write(2). If AOF was in error state, restore the
* OK state and log the event. */
if (server.aof_last_write_status == C_ERR) {
serverLog(LL_WARNING,
"AOF write error looks solved, Redis can write again.");
server.aof_last_write_status = C_OK;
}
}
server.aof_current_size += nwritten;
/* 如果 buffer 比较小的话,可以复用。否则就释放掉,重新分配 */
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
sdsclear(server.aof_buf);
} else {
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
try_fsync: // 将 aof 文件内存缓冲区的内容,写入磁盘
/* 如果 no-appendfsync-on-rewrite = yes,那么有子进程在做后台 I/O 的时候,不做 fsync */
if (server.aof_no_fsync_on_rewrite && hasActiveChildProcess())
return;
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
// 既然是 AOF_FSYNC_ALWAYS,那么每次写完 aof 之后,就得执行 fsync
/* redis_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
/* Let's try to get this data on the disk. To guarantee data safe when
* the AOF fsync policy is 'always', we should exit if failed to fsync
* AOF (see comment next to the exit(1) after write error above). */
if (redis_fsync(server.aof_fd) == -1) {
serverLog(LL_WARNING,"Can't persist AOF for fsync error when the "
"AOF fsync policy is 'always': %s. Exiting...", strerror(errno));
exit(1);
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_fsync_offset = server.aof_current_size;
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
// 如果是 AOF_FSYNC_EVERYSEC,则每秒执行一次
// 注意:由于 server.unixtime 是一个缓存,每秒更新一次(参考 updateCachedTime 方法),
// 所以只用 server.unixtime > server.aof_last_fsync,就可以保证“每秒处理一次”
if (!sync_in_progress) {
// 注意,此处是创建一个后台 fsync 任务,这里就和方法开始的
// sync_in_progress = aofFsyncInProgress() 检测任务呼应上了。
aof_background_fsync(server.aof_fd);
server.aof_fsync_offset = server.aof_current_size;
}
server.aof_last_fsync = server.unixtime;
}
}
在 redis 的启动过程中,会创建一个定时器 serverCron,定期执行一些后台操作,比如 上文中被延迟的flush操作(aof_flush_postponed_start),又比如 AOF rewrite。
- Active expired keys collection (it is also performed in a lazy way on lookup).
- Software watchdog.
- Update some statistic.
- Incremental rehashing of the DBs hash tables.
- Triggering BGSAVE / AOF rewrite, and handling of terminated children.
- Clients timeout of different kinds.
- Replication reconnection.
- Many more...
void initServer(void) {
......
/* Create the timer callback, this is our way to process many background
* operations incrementally, like clients timeout, eviction of unaccessed
* expired keys and so forth. */
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
......
}如果我们开启了 AOF 或者 RDB,就会在这个 serverCron 里定期执行。它的执行频率默认是 10 次/秒(10hertz)
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
······
server.hz = server.config_hz;
/* 如果连接的 client 太多,则需要动态的提升 serverCron 的执行频率。
* 这里采用的是小步快跑的思路,提升频率,降低每个 cron 处理的 client 数量,
* 以此来保证 serverCron 的总体执行时间不会太长。
*/
if (server.dynamic_hz) {
while (listLength(server.clients) / server.hz >
MAX_CLIENTS_PER_CLOCK_TICK)
{
server.hz *= 2;
if (server.hz > CONFIG_MAX_HZ) {
server.hz = CONFIG_MAX_HZ;
break;
}
}
}
······
/* 当执行了 kill -9 或者 shutdown,会在这里优雅的关停服务(比如 flush aof 文件、创建 RDB file 等) */
if (server.shutdown_asap) {
if (prepareForShutdown(SHUTDOWN_NOFLAGS) == C_OK) exit(0);
serverLog(LL_WARNING,"SIGTERM received but errors trying to shut down the server, check the logs for more information");
server.shutdown_asap = 0;
}
······
/* 处理一些 client 相关的事物,比如踢掉超时的 client、统计 client 内存使用;
* 为了不拖慢 serverCron 的整体处理时间,每次调用 clientsCron 只处理一部分 client;
* 尽量保证 1s 内处理完所有的 client。
*/
clientsCron();
/* 数据库相关的定时任务,比如删除过期key、rehash 等 */
databasesCron();
/* 启动 AOF rewrite */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* 如果有 BGSAVE 或 AOF rewrite,则检查并更新状态 */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 如果没有子任务在运行,确认是否需要执行 save/rewrite */
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* 判断是否需要 BGSAVE
* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* 主动触发 AOF rewrite if,触发条件是由 conf 文件中下面两个参数控制的:
* auto-aof-rewrite-percentage 100
* auto-aof-rewrite-min-size 64mb
*/
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
······
/*
* 通过上面的 flushAppendOnlyFile 源码,我们可以知道,在 AOF_FSYNC_EVERYSEC 策略下,
* fsync 都是通过后台任务的方式执行的(aof_background_fsync 方法)。
* 如果某一次 aof_background_fsync 时间较长,直到下一次 flushAppendOnlyFile 启动仍没有完成,
* 那么后续的 flushAppendOnlyFile 中的写 aof 就会延迟(最多2s),
*
* 在 serverCron 中通过定时任务来检测,如果前一次 aof_background_fsync 执行完了,
* 并且存在延迟的情况,就立刻去执行一次 flushAppendOnlyFile
*/
if (server.aof_state == AOF_ON && server.aof_flush_postponed_start)
flushAppendOnlyFile(0);
/* 如果写 AOF 出现错误,尝试在做一次 fsync */
run_with_period(1000) {
if (server.aof_state == AOF_ON && server.aof_last_write_status == C_ERR)
flushAppendOnlyFile(0);
}
······
server.cronloops++;
return 1000/server.hz;
}
至此,我们就看完了 “用户命令 -> aof buffer -> aof file(fsync磁盘)” 的基本流程。
对应的主要方法是:propagate() -> feedAppendOnlyFile() -> flushAppendOnlyFile()
3. AOF rewrite
serverCron 的源码中我们可以看到,当 aof 文件增加到一定程度时,就会触发 rewrite:rewriteAppendOnlyFileBackground()
/* background aof rewrite 的工作流程如下:
*
* 1) 用户发送 BGREWRITEAOF 命令 / 达到 aof 文件的阈值自动触发
* 2) Redis calls this function, that forks():
* 2a) 子进程在一个 tmp file 中执行 rewrite aof file
* 2b) 父进程在 server.aof_rewrite_buf 中统计后续的增量命令
* 3) 子进程完成之后,会发送一个 signal.
* 4) 主进程会捕获这个 signal, 如果结果是 OK, 就会将这段时间内积攒的命令(存放在 server.aof_rewrite_buf 中)
* append 到 tmp file 中,之后再 rename(2) temp file,这样它就成了新的 aof file 了
*/
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
if (aofCreatePipes() != C_OK) return C_ERR;
if ((childpid = redisFork(CHILD_TYPE_AOF)) == 0) {
char tmpfile[256];
/* Child */
redisSetProcTitle("redis-aof-rewrite");
redisSetCpuAffinity(server.aof_rewrite_cpulist);
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
sendChildCowInfo(CHILD_INFO_TYPE_AOF_COW_SIZE, "AOF rewrite");
exitFromChild(0);
} else {
exitFromChild(1);
}
} else {
/* Parent */
if (childpid == -1) {
serverLog(LL_WARNING,
"Can't rewrite append only file in background: fork: %s",
strerror(errno));
aofClosePipes();
return C_ERR;
}
serverLog(LL_NOTICE,
"Background append only file rewriting started by pid %ld",(long) childpid);
server.aof_rewrite_scheduled = 0;
server.aof_rewrite_time_start = time(NULL);
/* We set appendseldb to -1 in order to force the next call to the
* feedAppendOnlyFile() to issue a SELECT command, so the differences
* accumulated by the parent into server.aof_rewrite_buf will start
* with a SELECT statement and it will be safe to merge. */
server.aof_selected_db = -1;
replicationScriptCacheFlush();
return C_OK;
}
return C_OK; /* unreached */
}
子进程 aof rewrite
/* Write a sequence of commands able to fully rebuild the dataset into
* "filename". Used both by REWRITEAOF and BGREWRITEAOF.
*
* In order to minimize the number of commands needed in the rewritten
* log Redis uses variadic commands when possible, such as RPUSH, SADD
* and ZADD. However at max AOF_REWRITE_ITEMS_PER_CMD items per time
* are inserted using a single command. */
int rewriteAppendOnlyFile(char *filename) {
rio aof;
FILE *fp = NULL;
char tmpfile[256];
char byte;
/* Note that we have to use a different temp name here compared to the
* one used by rewriteAppendOnlyFileBackground() function. */
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
serverLog(LL_WARNING, "Opening the temp file for AOF rewrite in rewriteAppendOnlyFile(): %s", strerror(errno));
return C_ERR;
}
server.aof_child_diff = sdsempty();
rioInitWithFile(&aof,fp);
/* Set the file-based rio object to auto-fsync every 'bytes' file written.
* By default this is set to zero that means no automatic file sync is
* performed.
*
* This feature is useful in a few contexts since when we rely on OS write
* buffers sometimes the OS buffers way too much, resulting in too many
* disk I/O concentrated in very little time. When we fsync in an explicit
* way instead the I/O pressure is more distributed across time. */
if (server.aof_rewrite_incremental_fsync)
rioSetAutoSync(&aof,REDIS_AUTOSYNC_BYTES);
startSaving(RDBFLAGS_AOF_PREAMBLE);
if (server.aof_use_rdb_preamble) {
// rdb-aof 混合模式:RDB 做全量持久化,AOF 做增量持久化
// AOF 重写产生的文件将同时包含 RDB 格式的内容和 AOF 格式的内容,
// 该文件的前半段是 RDB 格式的全量数据,而后半段是 Redis 命令格式的增量数据
int error;
if (rdbSaveRio(&aof,&error,RDBFLAGS_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
/* Do an initial slow fsync here while the parent is still sending
* data, in order to make the next final fsync faster. */
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
/* 因为主进程可能会持续收到新命令,这里尝试从主进程多度一些数据
* 最多多读 1s,如果 20ms 内没有新的数据,也会跳过这部分代码. */
int nodata = 0;
mstime_t start = mstime();
while(mstime()-start < 1000 && nodata < 20) {
if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0)
{
nodata++;
continue;
}
nodata = 0; /* Start counting from zero, we stop on N *contiguous*
timeouts. */
aofReadDiffFromParent();
}
/* 通知主进程不需要再发 diff 数据了*/
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK)
goto werr;
/* 等候主进程的 replay(5s超时 */
if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1 ||
byte != '!') goto werr;
serverLog(LL_NOTICE,"Parent agreed to stop sending diffs. Finalizing AOF...");
/* 再读一次 */
aofReadDiffFromParent();
/* 把差异数据写到 aof file 中. */
serverLog(LL_NOTICE,
"Concatenating %.2f MB of AOF diff received from parent.",
(double) sdslen(server.aof_child_diff) / (1024*1024));
/* 现在,把子进程运行过程中,收到的所有数据写入到 AOF buffer 中。
* 每秒休息一次,跟主线程同步一下 COW(copy-on-write) 的信息。
*/
size_t bytes_to_write = sdslen(server.aof_child_diff);
const char *buf = server.aof_child_diff;
long long cow_updated_time = mstime();
long long key_count = dbTotalServerKeyCount();
while (bytes_to_write) {
/* 每 8MB 写一次 AOF buffer,这个大小就足够我们统计时间了 */
size_t chunk_size = bytes_to_write < (8<<20) ? bytes_to_write : (8<<20);
if (rioWrite(&aof,buf,chunk_size) == 0)
goto werr;
bytes_to_write -= chunk_size;
buf += chunk_size;
/* 跟主线程同步信息 Update COW info */
long long now = mstime();
if (now - cow_updated_time >= 1000) {
sendChildInfo(CHILD_INFO_TYPE_CURRENT_INFO, key_count, "AOF rewrite");
cow_updated_time = now;
}
}
/* 确保没有数据遗留在 OS 的 output buffer 中,都已经被刷到磁盘上了 */
if (fflush(fp)) goto werr;
if (fsync(fileno(fp))) goto werr;
if (fclose(fp)) { fp = NULL; goto werr; }
fp = NULL;
/* 使用 RENAME 来替换 DB file */
if (rename(tmpfile,filename) == -1) {
serverLog(LL_WARNING,"Error moving temp append only file on the final destination: %s", strerror(errno));
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
serverLog(LL_NOTICE,"SYNC append only file rewrite performed");
stopSaving(1);
return C_OK;
werr:
serverLog(LL_WARNING,"Write error writing append only file on disk: %s", strerror(errno));
if (fp) fclose(fp);
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}新命令记录到 aof rewrite buffer
当后台进程在执行 rewrite 的时候,又有新的命令进来了,这个时候就需要将命令也发一份给子进程,保证数据的最终一致性。
先看一看 rewrite buffer 的实现,从源码中的注释可以看出,这是一个列表,列表中的表项是一个 10MB 的 block。
/* ----------------------------------------------------------------------------
* AOF rewrite buffer implementation.
*
* The following code implement a simple buffer used in order to accumulate
* changes while the background process is rewriting the AOF file.
*
* We only need to append, but can't just use realloc with a large block
* because 'huge' reallocs are not always handled as one could expect
* (via remapping of pages at OS level) but may involve copying data.
*
* For this reason we use a list of blocks, every block is
* AOF_RW_BUF_BLOCK_SIZE bytes.
* ------------------------------------------------------------------------- */
#define AOF_RW_BUF_BLOCK_SIZE (1024*1024*10) /* 10 MB per block */
typedef struct aofrwblock {
unsigned long used, free;
char buf[AOF_RW_BUF_BLOCK_SIZE];
} aofrwblock;上文说到的 feedAppendOnlyFile() 方法的最后,如果发现有 aof rewrite 子任务正在进行,就会将命令再发一份给 aof rewrite buffer
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
······
if (server.child_type == CHILD_TYPE_AOF)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
}aofRewriteBufferAppend() 在方法最后,会注册一个 file event,通知正在做 aof rewrite 的子进程记录最新的命令
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
......
/* Install a file event to send data to the rewrite child if there is
* not one already. */
if (!server.aof_stop_sending_diff &&
aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0)
{
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child,
AE_WRITABLE, aofChildWriteDiffData, NULL);
}
}file event 的 handler 是 aofChildWriteDiffData():
/* 这是一个 Event handler,用来向 aof rewrite 子进程发送数据。
* 将 AOF differences buffer 分批发送过来,这样完成 aof rewrite 之后,需要处理的数据量就会比较小. */
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
UNUSED(el);
UNUSED(fd);
UNUSED(privdata);
UNUSED(mask);
while(1) {
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
if (server.aof_stop_sending_diff || !block) {
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,
AE_WRITABLE);
return;
}
if (block->used > 0) {
nwritten = write(server.aof_pipe_write_data_to_child,
block->buf,block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}至此,我们就基本看完了 aof rewrite 的主要流程。
练习题环节
- 如果 redis 运行了一段时间,这时候开启 aof,会发生什么?
startAppendOnly(void) 方法:Called when the user switches from "appendonly no" to "appendonly yes" at runtime using the CONFIG command.
其中调用了 rewriteAppendOnlyFileBackground(),执行了一次 rewrite,将 redis 中的数据全量备份到了 aof 文件中。
二、RDB
上文介绍的 AOF 记录的是操作命令,而不是实际的数据,所以,用 AOF 方法进行故障恢复的时候,需要逐一把操作日志都执行一遍。如果操作日志非常多,Redis 就会恢复得很缓慢,影响到正常使用。
那么,还有没有既可以保证可靠性,还能在宕机时实现快速恢复的其他方法呢?当然有了,这就是 Redis 提供的另一种持久化方法:内存快照 RDB。所谓内存快照,就是指内存中的数据在某一个时刻的状态记录。这就类似于照片,当你给朋友拍照时,一张照片就能把朋友一瞬间的形象完全记下来。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。
- save:在主线程中执行,会导致阻塞;
- bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。
为了保证子进程在写 RDB 的时候,主线程能正常增删改查,Redis 借助了操作系统提供的写时复制技术(Copy-On-Write, COW)。简单来说就是:bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件
此时,如果主线程对这些数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那么,这块数据(所在的 page)就会被复制一份,生成该数据的副本。然后,主线程(修改自己的页表)在这个数据副本上进行修改。同时,bgsave 子进程可以继续把原来的数据写入 RDB 文件。
这既保证了快照的完整性,也允许主线程同时对数据进行修改,避免了对正常业务的影响。
1. 源码阅读
1. RDB 的时机
先看看 redis.conf 中,关于 rdb 时机的配置项:
# Save the DB to disk.
#
# save <seconds> <changes>
#
# Redis will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# Snapshotting can be completely disabled with a single empty string argument
# as in following example:
#
# save ""
#
# Unless specified otherwise, by default Redis will save the DB:
# * After 3600 seconds (an hour) if at least 1 key changed
# * After 300 seconds (5 minutes) if at least 100 keys changed
# * After 60 seconds if at least 10000 keys changed
#
# You can set these explicitly by uncommenting the three following lines.
#
# save 3600 1
# save 300 100
# save 60 10000默认情况下,redis 初始化的时候,就会执行如下命令
appendServerSaveParams(60*60,1); /* save after 1 hour and 1 change */
appendServerSaveParams(300,100); /* save after 5 minutes and 100 changes */
appendServerSaveParams(60,10000); /* save after 1 minute and 10000 changes */saveParam 的结构如下:
struct saveparam {
time_t seconds;
int changes;
};而 redisServer 中记录着当前已经发生的变更数量,和上次 rdb 的时间:
struct redisServer {
······
/* RDB persistence */
long long dirty; /* 距离上一次 save 发生了多少次变更 */
struct saveparam *saveparams; /* 通过 “save 3600 1 *” 方式设置的 RDB 策略,都存在这个结构中 */
······
time_t lastsave; /* 上一次成功执行 save 的时间*/
time_t lastbgsave_try; /* 上一次执行 bgsave 的时间 */
time_t rdb_save_time_last; /* 上一次 RDB save 跑了多久. */
time_t rdb_save_time_start; /* 本次 RDB save 开始的时间. */
int rdb_bgsave_scheduled; /* 如果 bgsave 的时候,正在 aof rewrite,就会标记 scheduled,
* 等 aof rewrite完成后,在后续的 serverCron 中继续执行 bgsave */
int lastbgsave_status; /* 上一次执行 bgsave 的是否成功 */
······
}这样,我们只需要在 serverCron 中,比较 dirty--saveparam.changes 以及 seconds--lastsave 就可以判断是否该做 RDB 了:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
······
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 如果当前没有 bgSave / AOF rewrite 任务正在运行,就检查下是否要做 bgSave / AOF rewrite */
// RDB bgSave
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* Trigger an AOF rewrite if needed. */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
}
······
/* 如果 client 发送命令执行 bgsave 的时候,有子任务(比如 AOF rewrite、bgSave)正在运行,
* 则停止本次任务,返回 “Background saving scheduled”
* 同时标记 rdb_bgsave_scheduled,等到 serverCron 中下面这一段代码再做补偿:
* Start a scheduled BGSAVE if the corresponding flag is set. This is
* useful when we are forced to postpone a BGSAVE because an AOF
* rewrite is in progress. */
if (!hasActiveChildProcess() &&
server.rdb_bgsave_scheduled &&
(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK)
server.rdb_bgsave_scheduled = 0;
}
······
}2. RDB 的实现
下面是 rdbSaveBackground() 方法的实现,和 AOF 类似,还是依赖了 fork 机制。
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCowInfo(CHILD_INFO_TYPE_RDB_COW_SIZE, "RDB");
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent */
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}然后是 rdbSave() 方法:
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
int rdbSave(char *filename, rdbSaveInfo *rsi) {
······
/* rio 是 redis 提供的一个 IO 模块,将 buffer、file、socket 的读写,统一抽象成下面三个方法:
* read: read from stream.
* write: write to stream.
* tell: get the current offset. */
rioInitWithFile(&rdb,fp);
// 此处触发一个 event,主线程发现该 event 之后,
// 会打印日志“module-event-persistence-rdb-start”(参考 persistenceCallback())
startSaving(RDBFLAGS_NONE);
// 每处理 32MB,fsync一次
if (server.rdb_save_incremental_fsync)
rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
// 核心方法
if (rdbSaveRio(&rdb,&error,RDBFLAGS_NONE,rsi) == C_ERR) {
errno = error;
goto werr;
}
······
/* 用 tmp rdb file 替换原来的 rdb file. */
if (rename(tmpfile,filename) == -1) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty = 0;
server.lastsave = time(NULL);
server.lastbgsave_status = C_OK;
stopSaving(1);
return C_OK;
werr:
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
if (fp) fclose(fp);
unlink(tmpfile);
// 此处触发一个 event,主线程发现该 event 之后,会打印日志“module-event-persistence-end”
// 或“module-event-persistence-failed”
stopSaving(0);
return C_ERR;
}
下面是写 RDB 的核心方法:
/* 生成数据库 RDB 格式的 dump 文件 */
int rdbSaveRio(rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
uint64_t cksum;
size_t processed = 0;
int j;
long key_count = 0;
long long info_updated_time = 0;
// AOF + RDB 混合模式也会调用此方法
// (你可以在本页面全局搜索 rdbSaveRio,会发现 aof rewrite 中也会调用此方法)
char *pname = (rdbflags & RDBFLAGS_AOF_PREAMBLE) ? "AOF rewrite" : "RDB";
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
// 向文件头写入 magic 字符,表示这是一个 rdb 文件
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
if (rdbSaveInfoAuxFields(rdb,rdbflags,rsi) == -1) goto werr;
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr;
// 依次处理所有的 db
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue;
di = dictGetSafeIterator(d);
/* Write the SELECT DB opcode */
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(rdb,j) == -1) goto werr;
/* Write the RESIZE DB opcode. */
uint64_t db_size, expires_size;
db_size = dictSize(db->dict);
expires_size = dictSize(db->expires);
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
/* 迭代 db 中所有的 entry */
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
initStaticStringObject(key,keystr);
expire = getExpire(db,&key);
if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
/* 当使用 AOF + RDB 混合模式的时候,尝试从主进程读一些后续新增的命令,
* 这样做的目的是,尽可能的减少 rewrite 期间积攒的新命令,使最后一次 merge 的内容少一点
*/
if (rdbflags & RDBFLAGS_AOF_PREAMBLE &&
rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES)
{
processed = rdb->processed_bytes;
aofReadDiffFromParent();
}
/* 定期更新一下子进程的信息。Update child info every 1 second (approximately).
* in order to avoid calling mstime() on each iteration, we will
* check the diff every 1024 keys */
if ((key_count++ & 1023) == 0) {
long long now = mstime();
if (now - info_updated_time >= 1000) {
sendChildInfo(CHILD_INFO_TYPE_CURRENT_INFO, key_count, pname);
info_updated_time = now;
}
}
}
dictReleaseIterator(di);
di = NULL; /* So that we don't release it again on error. */
}
······
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;
/* EOF opcode */
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
/* CRC64 checksum. It will be zero if checksum computation is disabled, the
* loading code skips the check in this case. */
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
werr:
if (error) *error = errno;
if (di) dictReleaseIterator(di);
return C_ERR;
}在 rdbSaveKeyValuePair() 方法中,真正的写入了 redis 的 kv:
/* Save a key-value pair, with expire time, type, key, value.
* On error -1 is returned.
* On success if the key was actually saved 1 is returned. */
int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) {
int savelru = server.maxmemory_policy & MAXMEMORY_FLAG_LRU;
int savelfu = server.maxmemory_policy & MAXMEMORY_FLAG_LFU;
/* Save the expire time */
if (expiretime != -1) {
if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1;
if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1;
}
/* Save the LRU info. */
if (savelru) {
uint64_t idletime = estimateObjectIdleTime(val);
idletime /= 1000; /* Using seconds is enough and requires less space.*/
if (rdbSaveType(rdb,RDB_OPCODE_IDLE) == -1) return -1;
if (rdbSaveLen(rdb,idletime) == -1) return -1;
}
/* Save the LFU info. */
if (savelfu) {
uint8_t buf[1];
buf[0] = LFUDecrAndReturn(val);
/* We can encode this in exactly two bytes: the opcode and an 8
* bit counter, since the frequency is logarithmic with a 0-255 range.
* Note that we do not store the halving time because to reset it
* a single time when loading does not affect the frequency much. */
if (rdbSaveType(rdb,RDB_OPCODE_FREQ) == -1) return -1;
if (rdbWriteRaw(rdb,buf,1) == -1) return -1;
}
/* 保存:类型、key、value */
if (rdbSaveObjectType(rdb,val) == -1) return -1;
if (rdbSaveStringObject(rdb,key) == -1) return -1;
if (rdbSaveObject(rdb,val,key) == -1) return -1;
.......
}三、AOF + RDB
不管是 fork 还是 写磁盘,频繁操作都会影响机器性能;所以,默认情况下,
因为 RDB 是在做某一时刻的“快照”,如果服务器在两次 RDB 之间宕机,这段时间的数据就会丢失。
因此,为了既满足快速恢复的特性,又能保证数据不丢失,redis 提供了一种 AOF+RDB 混合的持久化方案。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。
具体的代码其实已经包含在上文 aof 的代码中了,你可以在本页面全局搜索 rdbSaveRio,来查看具体实现。
