我们总说的 Redis 具有高可靠性,其实有两层含义:
- 一是数据尽量少丢失
- 二是服务尽量少中断
AOF 和 RDB 保证了前者,而对于后者,Redis 的做法就是增加副本冗余量,将一份数据同时保存在多个实例上。即使有一个实例出现了故障,需要过一段时间才能恢复,其他实例也可以对外提供服务,不会影响业务使用。
多实例保存同一份数据,听起来好像很不错,但是,我们必须要考虑一个问题:这么多副本,它们之间的数据如何保持一致呢?数据读写操作可以发给所有的实例吗?
实际上,Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。读操作:主库、从库都可以接收;写操作:首先到主库执行,然后,主库将写操作同步给从库。
那么,主从库同步是如何完成的呢?主库数据是一次性传给从库,还是分批同步?要是主从库间的网络断连了,数据还能保持一致吗?本节我们就聊聊主从库同步的原理,以及应对网络断连风险的方案。
一、主从库间是如何同步的?
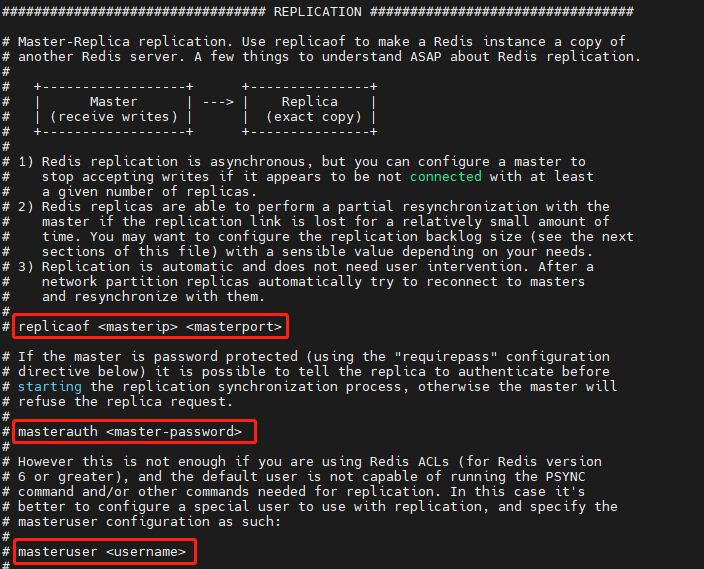
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof 命令形成主库和从库的关系:
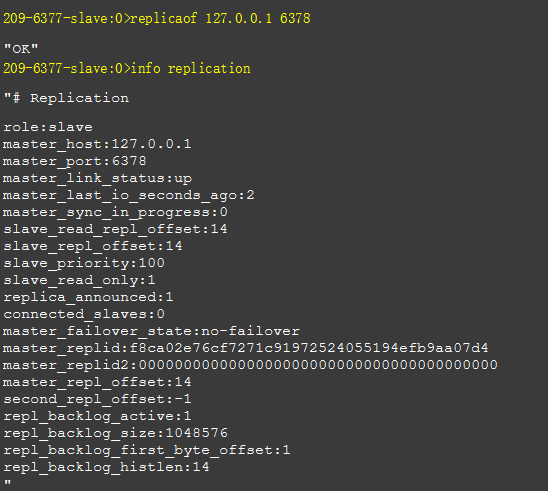
当然也可以直接在配置文件中配置:
之后会按照三个阶段完成数据的第一次同步:
1. 建立连接
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。
psync 命令包含了主库的 runID 和复制进度 offset 两个参数。runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。
当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。offset,此时设为 -1,表示第一次复制。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
注1:
旧版本的 redis 使用的是 sync 命令,当断线重连之后,需要全量同步一遍数据,效率低下。因此高版本 redis 增加了 psync 命令,用于同步断线期间的增量数据。
注2:
replication buffer:在主进程 fork 出子进程创建 rdb file 的时候,存储新收到的命令,每个 slave 一份。
replication backlog(buffer):一个环形的 buffer,专为增量同步设计的,全局一份。由于它是环形的,所以承载能力有限,当 master 和 slave 断连太久之后(积攒的命令太多会撑爆它,最早的数据就丢失了),此时就只能做全量同步了。
2. 同步全量数据
主库将所有数据(RDB 文件)同步给从库。从库收到数据后,在本地完成数据加载。
具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。
从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。
在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
3. 同步差异数据
主库会把第二阶段执行过程中新收到的写命令,再发送给从库。
具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
二、源码
0. state machine
先放一张整体流程图,对照着看更清晰一些

1. slave - master 建立连接
a. 通过配置文件
如果是通过配置文件设置为 slave,那么就会在 serverCron 中通过 replicationCron() 连接 master:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
······
/* Replication cron:用来连接 master、检测传输异常、发送 RDB 文件等。
* 如果之前发生过主从切换,那么提高 replicationCron() 频率 */
if (server.failover_state != NO_FAILOVER) {
run_with_period(100) replicationCron();
} else {
run_with_period(1000) replicationCron();
}
······
}replicationCron 的主要工作包括但不限于:检测 master - slave 的连接状态、尝试从异常中恢复连接、激活 pending 的 rdb 等
void replicationCron(void) {
static long long replication_cron_loops = 0;
/* 检测之前是否有异常发生,如果有,则尝试通过 replicationSetMaster()
* 方法重新连接 master */
updateFailoverStatus();
/* 检测是否连接超时,并尝试重新连接 master */
if (server.masterhost &&
(server.repl_state == REPL_STATE_CONNECTING ||
slaveIsInHandshakeState()) &&
(time(NULL)-server.repl_transfer_lastio) > server.repl_timeout)
{
serverLog(LL_WARNING,"Timeout connecting to the MASTER...");
cancelReplicationHandshake(1);
}
/* 检测是否 I/O 超时,并尝试重新连接 master */
if (server.masterhost && server.repl_state == REPL_STATE_TRANSFER &&
(time(NULL)-server.repl_transfer_lastio) > server.repl_timeout)
{
serverLog(LL_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value.");
cancelReplicationHandshake(1);
}
/* Timed out master when we are an already connected slave? */
if (server.masterhost && server.repl_state == REPL_STATE_CONNECTED &&
(time(NULL)-server.master->lastinteraction) > server.repl_timeout)
{
serverLog(LL_WARNING,"MASTER timeout: no data nor PING received...");
freeClient(server.master);
}
/* 如果状态是 REPL_STATE_CONNECT:Must connect to master,则连接 master*/
if (server.repl_state == REPL_STATE_CONNECT) {
serverLog(LL_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
connectWithMaster();
}
/* 如果 master 支持 REPLCONF 命令,则 Send ACK to master from time to time.
* 通知 master 当前处理的 offset */
if (server.masterhost && server.master &&
!(server.master->flags & CLIENT_PRE_PSYNC))
replicationSendAck();
/* 首先,
* 如果自身是 master 且有 slaves 节点, 每次都 ping 他们一下,这样便于 slaves 判断是否连接超时
* 如果自身是 slave,do nothing
*/
listIter li;
listNode *ln;
robj *ping_argv[1];
/* First, send PING according to ping_slave_period. */
if ((replication_cron_loops % server.repl_ping_slave_period) == 0 &&
listLength(server.slaves))
{
/* Note that we don't send the PING if the clients are paused during
* a Redis Cluster manual failover: the PING we send will otherwise
* alter the replication offsets of master and slave, and will no longer
* match the one stored into 'mf_master_offset' state. */
int manual_failover_in_progress =
((server.cluster_enabled &&
server.cluster->mf_end) ||
server.failover_end_time) &&
checkClientPauseTimeoutAndReturnIfPaused();
if (!manual_failover_in_progress) {
ping_argv[0] = shared.ping;
replicationFeedSlaves(server.slaves, server.slaveseldb,
ping_argv, 1);
}
}
/* 第二, 发一个 newline 给所有的 slaves,表示处于 pre-synchronization 状态,
* 表示 slaves 等待 master 创建 RDB file.
*
* (级联模式下)还给所有 slave 的 slave 节点发一个 newline, 让他们知道他们的 master 还活着.
* This is needed since sub-slaves only receive proxied
* data from top-level masters, so there is no explicit pinging in order
* to avoid altering the replication offsets. This special out of band
* pings (newlines) can be sent, they will have no effect in the offset.
*
* slave 节点会忽略掉 newline,只是刷新一下 last interaction timer 防止超时
* In this case we ignore the
* ping period and refresh the connection once per second since certain
* timeouts are set at a few seconds (example: PSYNC response). */
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
int is_presync =
(slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START ||
(slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END &&
server.rdb_child_type != RDB_CHILD_TYPE_SOCKET));
if (is_presync) {
connWrite(slave->conn, "\n", 1);
}
}
/* 踢掉超时的 slave */
if (listLength(server.slaves)) {
listIter li;
listNode *ln;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
······
/* 只尝试关闭 socket mode 的 slave,而不关闭 disk mode 的 slave;
* 因为 disk mode 下,传输超时并不会一直卡住 fork child
* (事实上 fork child 只做 RDB,做完就可以退出了,传输是在后续的 handler 中异步执行的),
* 而在 socket mode 下,传输是在子进程中做的,如果超时了,那么 fork child 就会一直被卡住。*/
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END && server.rdb_child_type == RDB_CHILD_TYPE_SOCKET) {
if (slave->repl_last_partial_write != 0 &&
(server.unixtime - slave->repl_last_partial_write) > server.repl_timeout)
{
serverLog(LL_WARNING, "Disconnecting timedout replica (full sync): %s",
replicationGetSlaveName(slave));
freeClient(slave);
continue;
}
}
}
}
......
// 如果 RDB for replication 因为某种原因被挂起了,这里尝试激活一下
// 这个方法很重要,下文会做详细的介绍。
replicationStartPendingFork();
/* 如果没有开启持久化策略,需要在这里定期删除创建 replication 时生成的 RDB file */
removeRDBUsedToSyncReplicas();
/* 统计 slave 节点延迟。如果一定数量的 slave 节点延迟 > min-slaves-max-lag,master 将拒绝写命令*/
refreshGoodSlavesCount();
replication_cron_loops++; /* Incremented with frequency 1 HZ. */
}注意 connectWithMaster() 方法,就是它去连接 master 的,后文会介绍它的具体实现。
b. 通过 replicaof 命令建立连接
如果是启动之后,通过在客户端执行 replicaof [ip] [port] 命令连接 master:
void replicaofCommand(client *c) {
......
/* 如果命令中的 host/port 被设置为 "NO" "ONE" 时(即:replicaof no one),
* 本机将变为 master */
if (!strcasecmp(c->argv[1]->ptr,"no") &&
!strcasecmp(c->argv[2]->ptr,"one")) {
if (server.masterhost) {
replicationUnsetMaster();
sds client = catClientInfoString(sdsempty(),c);
serverLog(LL_NOTICE,"MASTER MODE enabled (user request from '%s')",
client);
sdsfree(client);
}
} else {
long port;
if (c->flags & CLIENT_SLAVE)
{
/* If a client is already a replica they cannot run this command,
* because it involves flushing all replicas (including this
* client) */
addReplyError(c, "Command is not valid when client is a replica.");
return;
}
// 校验端口号
if ((getLongFromObjectOrReply(c, c->argv[2], &port, NULL) != C_OK))
return;
/* 校验需要连接的 master,是不是当前已经连上的机器 */
if (server.masterhost && !strcasecmp(server.masterhost,c->argv[1]->ptr)
&& server.masterport == port) {
serverLog(LL_NOTICE,"REPLICAOF would result into synchronization "
"with the master we are already connected "
"with. No operation performed.");
addReplySds(c,sdsnew("+OK Already connected to specified "
"master\r\n"));
return;
}
/* 连接新指定的 master */
replicationSetMaster(c->argv[1]->ptr, port);
sds client = catClientInfoString(sdsempty(),c);
serverLog(LL_NOTICE,"REPLICAOF %s:%d enabled (user request from '%s')",
server.masterhost, server.masterport, client);
sdsfree(client);
}
addReply(c,shared.ok);
}设置并连接新的 master:
/* 连接到指定的 master */
void replicationSetMaster(char *ip, int port) {
int was_master = server.masterhost == NULL;
······
server.masterhost = sdsnew(ip);
server.masterport = port;
······
server.repl_state = REPL_STATE_CONNECT;
serverLog(LL_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
connectWithMaster();
}和 "配置文件配置 master" 类似,我们又一次见到了 connectWithMaster() 方法,它尝试与 master 建立物理连接:
int connectWithMaster(void) {
server.repl_transfer_s = server.tls_replication ? connCreateTLS() : connCreateSocket();
/* 尝试与 master 建立物理连接,连接成功后的 handler 是 syncWithMaster */
if (connConnect(server.repl_transfer_s, server.masterhost, server.masterport,
NET_FIRST_BIND_ADDR, syncWithMaster) == C_ERR) {
serverLog(LL_WARNING,"Unable to connect to MASTER: %s",
connGetLastError(server.repl_transfer_s));
connClose(server.repl_transfer_s);
server.repl_transfer_s = NULL;
return C_ERR;
}
······
server.repl_state = REPL_STATE_CONNECTING;
······
return C_OK;
}syncWithMaster 的主要工作是:ping-pong with master,向 master 同步自己的信息,下载 master 的 rdb 文件等。
/* 与 master 建立起 non blocking connect 之后,就会触发这个方法 */
void syncWithMaster(connection *conn) {
char tmpfile[256], *err = NULL;
int dfd = -1, maxtries = 5;
int psync_result;
······
/* 向 master 发送 ping 命令,发送完就 return 了。
* 注意这里的 handler 还是 syncWithMaster() 自身,
* 收到回复(pong)之后,会在下一段代码里处理. */
if (server.repl_state == REPL_STATE_CONNECTING) {
serverLog(LL_NOTICE,"Non blocking connect for SYNC fired the event.");
/* Delete the writable event so that the readable event remains
* registered and we can wait for the PONG reply. */
connSetReadHandler(conn, syncWithMaster);
connSetWriteHandler(conn, NULL);
server.repl_state = REPL_STATE_RECEIVE_PING_REPLY;
/* Send the PING, don't check for errors at all, we have the timeout
* that will take care about this. */
err = sendCommand(conn,"PING",NULL);
if (err) goto write_error;
return;
}
/* 处理 PONG 命令. */
if (server.repl_state == REPL_STATE_RECEIVE_PING_REPLY) {
err = receiveSynchronousResponse(conn);
if (err[0] != '+' &&
strncmp(err,"-NOAUTH",7) != 0 &&
strncmp(err,"-NOPERM",7) != 0 &&
strncmp(err,"-ERR operation not permitted",28) != 0)
{
serverLog(LL_WARNING,"Error reply to PING from master: '%s'",err);
sdsfree(err);
goto error;
} else {
serverLog(LL_NOTICE,
"Master replied to PING, replication can continue...");
}
······
// ping-pong 完成,表示可以连接上,准备 handshake 交换信息
server.repl_state = REPL_STATE_SEND_HANDSHAKE;
}
// handshake:通过账号密码连接 master
// 连接成功后,发送自己的信息
if (server.repl_state == REPL_STATE_SEND_HANDSHAKE) {
/* AUTH with the master if required. */
if (server.masterauth) {
char *args[3] = {"AUTH",NULL,NULL};
size_t lens[3] = {4,0,0};
int argc = 1;
if (server.masteruser) {
args[argc] = server.masteruser;
lens[argc] = strlen(server.masteruser);
argc++;
}
args[argc] = server.masterauth;
lens[argc] = sdslen(server.masterauth);
argc++;
err = sendCommandArgv(conn, argc, args, lens);
if (err) goto write_error;
}
/* 发送 slave 节点的 port, 以便 Master 的 info replication 命令
* 可以正确的打印 slave 监听的端口 */
{
int port;
if (server.slave_announce_port)
port = server.slave_announce_port;
else if (server.tls_replication && server.tls_port)
port = server.tls_port;
else
port = server.port;
sds portstr = sdsfromlonglong(port);
err = sendCommand(conn,"REPLCONF",
"listening-port",portstr, NULL);
sdsfree(portstr);
if (err) goto write_error;
}
/* 发送 slave ip, , 以便 Master 的 info replication 命令
* 可以正确的打印 slave 的 ip 地址 */
if (server.slave_announce_ip) {
err = sendCommand(conn,"REPLCONF",
"ip-address",server.slave_announce_ip, NULL);
if (err) goto write_error;
}
/* 通知 master 自己支持哪些命令(capabilities).
*
* EOF: supports EOF-style RDB transfer for diskless replication.
* PSYNC2: supports PSYNC v2, so understands +CONTINUE <new repl ID>.
*
* The master will ignore capabilities it does not understand. */
err = sendCommand(conn,"REPLCONF",
"capa","eof","capa","psync2",NULL);
if (err) goto write_error;
server.repl_state = REPL_STATE_RECEIVE_AUTH_REPLY;
return;
}
······
/* slave 跑完上面的代码块之后,state 被设置为 REPL_STATE_RECEIVE_AUTH_REPLY
* 当 IO 多路复用机制监听到下一次 conn 对应的 fd 有数据来时,就会在这里处理 */
if (server.repl_state == REPL_STATE_RECEIVE_AUTH_REPLY) {
err = receiveSynchronousResponse(conn);
if (err[0] == '-') {
serverLog(LL_WARNING,"Unable to AUTH to MASTER: %s",err);
sdsfree(err);
goto error;
}
······
server.repl_state = REPL_STATE_RECEIVE_PORT_REPLY;
return;
}
/* 对应上面的发送 port(REPLCONF 命令),这里处理 master 的返回 */
if (server.repl_state == REPL_STATE_RECEIVE_PORT_REPLY) {
err = receiveSynchronousResponse(conn);
/* Ignore the error if any, not all the Redis versions support
* REPLCONF listening-port. */
if (err[0] == '-') {
serverLog(LL_NOTICE,"(Non critical) Master does not understand "
"REPLCONF listening-port: %s", err);
}
sdsfree(err);
server.repl_state = REPL_STATE_RECEIVE_IP_REPLY;
return;
}
if (server.repl_state == REPL_STATE_RECEIVE_IP_REPLY && !server.slave_announce_ip)
server.repl_state = REPL_STATE_RECEIVE_CAPA_REPLY;
/* 对应上面的发送 ip(REPLCONF 命令),这里处理 master 的返回 */
if (server.repl_state == REPL_STATE_RECEIVE_IP_REPLY) {
err = receiveSynchronousResponse(conn);
/* Ignore the error if any, not all the Redis versions support
* REPLCONF listening-port. */
if (err[0] == '-') {
serverLog(LL_NOTICE,"(Non critical) Master does not understand "
"REPLCONF ip-address: %s", err);
}
sdsfree(err);
server.repl_state = REPL_STATE_RECEIVE_CAPA_REPLY;
return;
}
/* 对应上面的发送自己支持的能力(CAPA 命令),这里处理 master 的返回 */
if (server.repl_state == REPL_STATE_RECEIVE_CAPA_REPLY) {
err = receiveSynchronousResponse(conn);
/* Ignore the error if any, not all the Redis versions support
* REPLCONF capa. */
if (err[0] == '-') {
serverLog(LL_NOTICE,"(Non critical) Master does not understand "
"REPLCONF capa: %s", err);
}
sdsfree(err);
err = NULL;
server.repl_state = REPL_STATE_SEND_PSYNC;
}
/* 发送命令 PSYNC <MASTER_RUN_ID> <OFFSET> 给 master
* 如果没有 cached master(就没法做增量同步),命令变为 PSYNC ? -1
* 这里主要是为了从 master 拿到 master_replid 和 master_repl_offset,
* 等到 master 回复的时候,尝试做增量同步(一般情况下这时候肯定会失败,
* 所以最终会变成全量同步) */
if (server.repl_state == REPL_STATE_SEND_PSYNC) {
if (slaveTryPartialResynchronization(conn,0) == PSYNC_WRITE_ERROR) {
err = sdsnew("Write error sending the PSYNC command.");
abortFailover("Write error to failover target");
goto write_error;
}
// 修改状态为:待接收 psync replay
server.repl_state = REPL_STATE_RECEIVE_PSYNC_REPLY;
return;
}
/* 如果代码走到了这里, 说明 master 已经回复了 slave 的 psync 命令 */
// 下面会根据 master 的回复,进行 全量同步 或者 增量同步(psync)
// 尝试增量同步,slaveTryPartialResynchronization 中不实际做同步操作,
// 只是j接受 master 的回复,并更新信息:
// 1. 如果 master 答复 CONTINUE:说明可以 psync,
// 更新 cached_master(replId、offset)
// 2. 如果 master 答复 FULLRESYNC:说明只能做全量同步,
// 更新 master_replid、master_initial_offset,删除 cached_master
psync_result = slaveTryPartialResynchronization(conn,1);
······
// 如果可以进行 psync,那么就在这里结束了,继续等待 master 传输数据过来。
if (psync_result == PSYNC_CONTINUE) {
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.");
······
return;
}
/* (级联情况下)如果当前节点不能和 master 增量同步,那么也一定不能和自己的
* slave 增量同步。
* 这时候需要踢掉自己的 slave,让它们做全量同步 */
disconnectSlaves(); /* Force our slaves to resync with us as well. */
freeReplicationBacklog(); /* Don't allow our chained slaves to PSYNC. */
/* 如果 master 不支持增量同步,就做全量同步 */
if (psync_result == PSYNC_NOT_SUPPORTED) {
serverLog(LL_NOTICE,"Retrying with SYNC...");
if (connSyncWrite(conn,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) {
serverLog(LL_WARNING,"I/O error writing to MASTER: %s",
strerror(errno));
goto error;
}
}
/* 为了接受 master 的 rdb 文件,需要创建一个 temp file */
if (!useDisklessLoad()) {
while(maxtries--) {
snprintf(tmpfile,256,
"temp-%d.%ld.rdb",(int)server.unixtime,(long int)getpid());
dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644);
if (dfd != -1) break;
sleep(1);
}
if (dfd == -1) {
serverLog(LL_WARNING,"Opening the temp file needed for MASTER <-> REPLICA synchronization: %s",strerror(errno));
goto error;
}
server.repl_transfer_tmpfile = zstrdup(tmpfile);
server.repl_transfer_fd = dfd;
}
/* (异步)下载 master 的 rdb 文件(每 8MB 做一次 fsync). */
if (connSetReadHandler(conn, readSyncBulkPayload)
== C_ERR)
{
char conninfo[CONN_INFO_LEN];
serverLog(LL_WARNING,
"Can't create readable event for SYNC: %s (%s)",
strerror(errno), connGetInfo(conn, conninfo, sizeof(conninfo)));
goto error;
}
server.repl_state = REPL_STATE_TRANSFER;
server.repl_transfer_size = -1;
server.repl_transfer_read = 0;
server.repl_transfer_last_fsync_off = 0;
server.repl_transfer_lastio = server.unixtime;
return;
······
}2. slave 尝试进行增量同步
slave 和 master 建立起连接之后,syncWithMaster() 方法中有一个slaveTryPartialResynchronization(),slave 就是通过它向 master 发起 psync 请求的:
// 这个方法,分为两部分,writing half 和 reading half
// writing half 是用来向 master 发起 psync 请求的。
// reading half 是用来接受 master 的回复的
int slaveTryPartialResynchronization(connection *conn, int read_reply) {
char *psync_replid;
char psync_offset[32];
sds reply;
/* Writing half */
if (!read_reply) {
······
// 向 master 发送 psync 命令,尝试增量同步
reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,NULL);
······
return PSYNC_WAIT_REPLY;
}
/* Reading half */
reply = receiveSynchronousResponse(conn);
······
// 注意,这里将 readhandler 设置为 null,
// 是为了先处理 master 的应答,判断是 psync 还是 sync。
// 后面会重新绑定对应的 handler,来处理真正的数据。
connSetReadHandler(conn, NULL);
// 全量同步
if (!strncmp(reply,"+FULLRESYNC",11)) {
······
/* FULL RESYNC, 从 master 的回复中,解析 replid 和 replication offset. */
memcpy(server.master_replid, replid, offset-replid-1);
server.master_replid[CONFIG_RUN_ID_SIZE] = '\0';
server.master_initial_offset = strtoll(offset,NULL,10);
······
// 本方法是用来 psync 的,到这里发现只能做 full resync,
// 所以直接退出,由后续的代码流程来处理
return PSYNC_FULLRESYNC;
}
// 增量同步
if (!strncmp(reply,"+CONTINUE",9)) {
serverLog(LL_NOTICE,
"Successful partial resynchronization with master.");
······
replicationResurrectCachedMaster(conn);
······
return PSYNC_CONTINUE;
}
······
// master 没有按照预期的内容答复,我们认为 master 不支持 psync
// 做个标记,后续进行全量同步
return PSYNC_NOT_SUPPORTED;
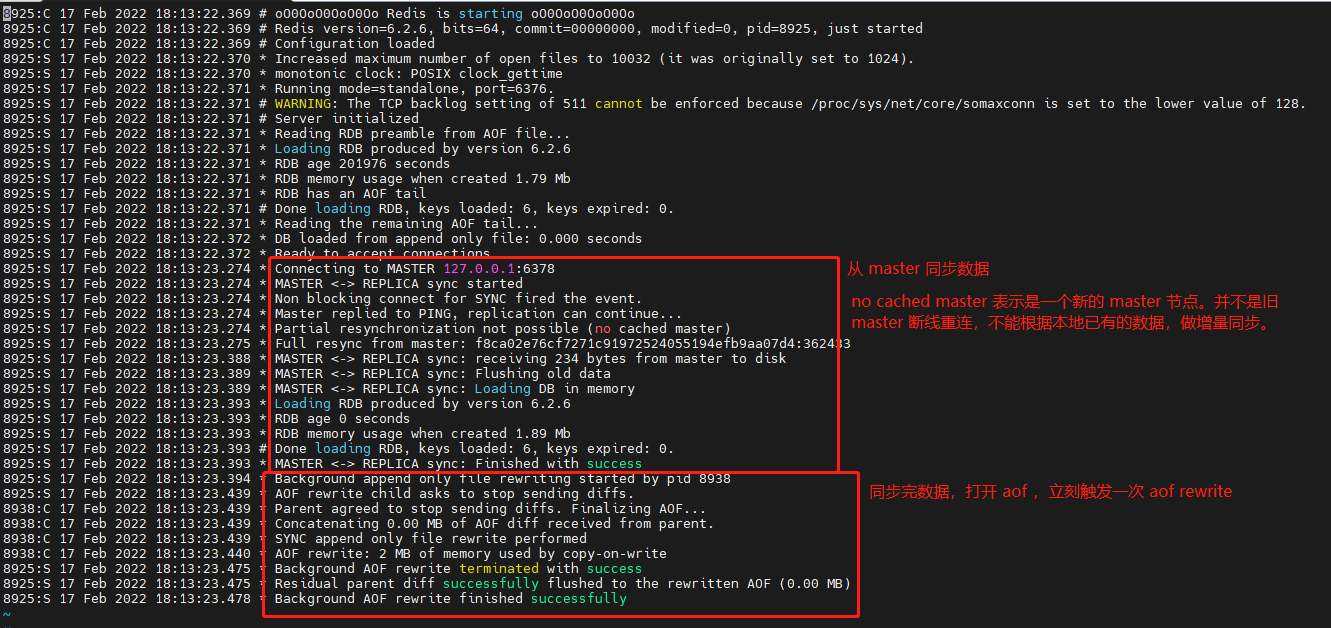
}下面的日志是通过配置文件启动的 slave 节点的初始化过程,可以对照上面的代码看看:
3. master 应答 slave 同步请求
先看总体流程图:

syncCommand() 具体实现如下:
/* SYNC and PSYNC command implementation. */
void syncCommand(client *c) {
/* slave 会忽略 PSYNC/SYNC 请求*/
if (c->flags & CLIENT_SLAVE) return;
/* 如果 psync 命令中带有 failover 参数(并且持有相同的 replId 的实例),
* 则进行故障转移,收到命令的 slave 会切换成 master。
* (master 节点会拒绝带有 failover 的 psync 命令)。
*/
if (c->argc > 3 && !strcasecmp(c->argv[0]->ptr,"psync") &&
!strcasecmp(c->argv[3]->ptr,"failover"))
{
serverLog(LL_WARNING, "Failover request received for replid %s.", (unsigned char *)c->argv[1]->ptr);
······
// 取消复制,把自己设置为 master。主要工作是:
// 1. 释放 server.master,释放 server.cached_master
// 2. 启用新的 replId,将旧的 replId 设为 master_replid2
// 3. 重置一些副本相关的计数器、计时器
// 4. (如果需要的话)打开被 sync 关闭的 aof
replicationUnsetMaster();
······
serverLog(LL_NOTICE, "MASTER MODE enabled (failover request from '%s')", client);
······
}
······
serverLog(LL_NOTICE,"Replica %s asks for synchronization", replicationGetSlaveName(c));
/* slave 发过来的如果是 PSYNC 命令,判断是否可以增量同步
* (判断 slave 发过来的 replid 和 offset 是否能用)。
* 如果不行, masterTryPartialResynchronization()
* 就会通过 +FULLRESYNC <replid> <offset> 命令通知客户端进行全量同步 */
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return; /* 增量同步成功,结束 */
} else {
char *master_replid = c->argv[1]->ptr;
/* Increment stats for failed PSYNCs, but only if the
* replid is not "?", as this is used by slaves to force a full
* resync on purpose when they are not albe to partially
* resync. */
if (master_replid[0] != '?') server.stat_sync_partial_err++;
}
}
······
/* 全量复制. */
server.stat_sync_full++;
/* 全量同步时,需要 master 生成并发送自己的 rdb 文件,
* 所以先把 slave 的状态设置为 SLAVE_STATE_WAIT_BGSAVE_START 等待状态 */
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START;
if (server.repl_disable_tcp_nodelay)
connDisableTcpNoDelay(c->conn); /* Non critical if it fails. */
c->repldbfd = -1;
c->flags |= CLIENT_SLAVE;
listAddNodeTail(server.slaves,c);
/* Create the replication backlog if needed. */
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) {
/* When we create the backlog from scratch, we always use a new
* replication ID and clear the ID2, since there is no valid
* past history. */
changeReplicationId();
clearReplicationId2();
createReplicationBacklog();
serverLog(LL_NOTICE,"Replication backlog created, my new "
"replication IDs are '%s' and '%s'",
server.replid, server.replid2);
}
/* CASE 1: BGSAVE 正在运行中(with disk target) */
if (server.child_type == CHILD_TYPE_RDB &&
server.rdb_child_type == RDB_CHILD_TYPE_DISK)
{
/* Ok a background save is in progress. Let's check if it is a good
* one for replication, i.e. if there is another slave that is
* registering differences since the server forked to save. */
client *slave;
listNode *ln;
listIter li;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
slave = ln->value;
/* 找一找 in progress bgsave 是不是某个 slave 触发的 */
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END &&
(!(slave->flags & CLIENT_REPL_RDBONLY) ||
(c->flags & CLIENT_REPL_RDBONLY)))
break;
}
/* 当前 client(新的 slave),和刚才找到的 slave 支持的能力一致,
* 那么 bgsave 的结果新的 slave 也能使用 */
if (ln && ((c->slave_capa & slave->slave_capa) == slave->slave_capa)) {
/* 把主节点的 replid 和 offset 发给新的 slave,即回复命令 “+FULLRESYNC replid offset”*/
if (!(c->flags & CLIENT_REPL_RDBONLY)) copyClientOutputBuffer(c,slave);
replicationSetupSlaveForFullResync(c,slave->psync_initial_offset);
serverLog(LL_NOTICE,"Waiting for end of BGSAVE for SYNC");
} else {
/* 本次的 bgsave 结果不能用来创建 replication,只能等下次 bgsave 触发了 */
serverLog(LL_NOTICE,"Can't attach the replica to the current BGSAVE. Waiting for next BGSAVE for SYNC");
}
/* CASE 2: BGSAVE 正在运行中, with socket target. */
} else if (server.child_type == CHILD_TYPE_RDB &&
server.rdb_child_type == RDB_CHILD_TYPE_SOCKET)
{
/* 已经有 slave 触发 bgsave 了,但是它是 with socket target
* 直接把数据写给 socket 的,所以没办法重用。只能等下次 bgsave
* 再做同步。*/
serverLog(LL_NOTICE,"Current BGSAVE has socket target. Waiting for next BGSAVE for SYNC");
/* CASE 3: There is no BGSAVE is progress. */
} else {
if (server.repl_diskless_sync && (c->slave_capa & SLAVE_CAPA_EOF) &&
server.repl_diskless_sync_delay)
{
/* diskless replication 会立即把数据写到 socket 里,
* 中途再过来的 slave 就只能等下次 rdb 了,所以为了减少压力,
* 让后续的 slaves 都尽量重用这次 rdb,所以我们不用着急立刻启动 rdb。
* 而是在 replicationCron() 中启动 Diskless replication RDB */
serverLog(LL_NOTICE,"Delay next BGSAVE for diskless SYNC");
} else {
/* 启动 bgsave */
if (!hasActiveChildProcess()) {
startBgsaveForReplication(c->slave_capa);
} else {
serverLog(LL_NOTICE,
"No BGSAVE in progress, but another BG operation is active. "
"BGSAVE for replication delayed");
}
}
}
return;
}a. 增量同步
先来看增量同步。增量同步意味着只需要把同步缓冲区 backlog 中的数据发给 slave 就完成同步了。当然并不是直接把 backlog 中所有的数据发过去就可以了,而是根据 slave 的 psync_offset,将 psync_offset 之后的数据发送给 slave。
int masterTryPartialResynchronization(client *c) {
long long psync_offset, psync_len;
char *master_replid = c->argv[1]->ptr;
char buf[128];
int buflen;
/* 解析 slave 的 psync_offset */
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) !=
C_OK) goto need_full_resync;
/* 比较 master 的 replid、offset,如果不一致,
* 说明无法进行增量同步,只能进行 full_resync*/
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset))
{
······
goto need_full_resync;
}
/* replid 对得上,但是 offset 越界了,只能进行 full_resync */
if (!server.repl_backlog ||
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen))
{
······
goto need_full_resync;
}
/* 准备开始增量同步:
* 1) Set client state to make it a slave.
* 2) Inform the client we can continue with +CONTINUE
* 3) 发送缓冲区 backlog 中的数据给 slave */
c->flags |= CLIENT_SLAVE;
c->replstate = SLAVE_STATE_ONLINE;
c->repl_ack_time = server.unixtime;
c->repl_put_online_on_ack = 0;
listAddNodeTail(server.slaves,c);
/* 应答 slave */
if (c->slave_capa & SLAVE_CAPA_PSYNC2) {
buflen = snprintf(buf,sizeof(buf),"+CONTINUE %s\r\n", server.replid);
} else {
buflen = snprintf(buf,sizeof(buf),"+CONTINUE\r\n");
}
if (connWrite(c->conn,buf,buflen) != buflen) {
freeClientAsync(c);
return C_OK;
}
// 发送数据给 slave
// 这个方法不再展开,实际上就是根据 slave.offset
// 把 master 的复制缓冲区 backlog 中剩余的数据发送给 client
psync_len = addReplyReplicationBacklog(c,psync_offset);
serverLog(LL_NOTICE,
"Partial resynchronization request from %s accepted. Sending %lld bytes of backlog starting from offset %lld.",
replicationGetSlaveName(c),
psync_len, psync_offset);
······
/* 增量同步完成 */
return C_OK;
need_full_resync:
// 增量同步 如果返回错误,那么同步的主流程就会去执行 全量同步
/* We need a full resync for some reason... Note that we can't
* reply to PSYNC right now if a full SYNC is needed. The reply
* must include the master offset at the time the RDB file we transfer
* is generated, so we need to delay the reply to that moment. */
return C_ERR;
}
b. 全量同步
master 在收到 psync/sync 之后,先尝试增量同步,如果没有成功,就会进行全量同步,这部分代码就在上面的 syncCommand 方法中。
这时候有下面几种情况要处理,详细的流程可以参考 master 收到 slave 同步请求 的大图:
有后台 bgsave 正在运行:
- 有盘复制:如果可以复用本次 bgsave 结果(backlog中正在存储差异),则直接通知 slave;如果不行,则等待下次 bgsave
- 无盘复制:等待下次 bgsave
没有后台 bgsave 任务:
- 有盘复制:fork 子进程、通知 slave(replid&offset)
- 无盘复制:直接 return,等待后台 replicationCron() 拉起 bgsave 任务
4. slave 收到 master 答复之后
这部分的逻辑其实就在上文的syncWithMaster() 方法中:在 slave-master 建立连接过程中,通过connSetReadHandler(conn, syncWithMaster) 将自身设为了处理器。即:master 应答(slave 的 socket 中有数据可读)之后,还是通过syncWithMaster()自身来进行处理,这时候,根据 master、slave 的状态不同,会进入正确的代码分支。
全局查找syncWithMaster,从上文的源码中可以看到,收到答复之后,slave 会调用 slaveTryPartialResynchronization 方法处理,上面提到过,这个方法分为 writing half(向 master 发起 psync 请求)和 reading half(接收 master 对 psync 的答复)两部分,这时候 reading half 分支就发挥作用了。
a. 增量同步
如果是增量同步,在 slaveTryPartialResynchronization 方法中,会调用 replicationResurrectCachedMaster 设置接受数据的 handler,来处理增量同步的数据:
/* 这段英文注释没怎么看明白,不过好在代码比较简单,不影响我们理解
* 就是设置了 read handler 和 write handler
*
* This function is called when successfully setup a partial resynchronization
* so the stream of data that we'll receive will start from were this
* master left. */
void replicationResurrectCachedMaster(connection *conn) {
......
/* Re-add to the list of clients. */
linkClient(server.master);
// read handler 是 readQueryFromClient,
// 在 readme.txt 中对 readQueryFromClient 有这样一段说明:
// `readQueryFromClient()` is the *readable event handler* and accumulates data read from the client into the query buffer.
// 即,增量同步的数据,其实是被当做普通 redis 命令来处理的
if (connSetReadHandler(server.master->conn, readQueryFromClient)) {
serverLog(LL_WARNING,"Error resurrecting the cached master, impossible to add the readable handler: %s", strerror(errno));
freeClientAsync(server.master); /* Close ASAP. */
}
/* We may also need to install the write handler as well if there is
* pending data in the write buffers. */
if (clientHasPendingReplies(server.master)) {
if (connSetWriteHandler(server.master->conn, sendReplyToClient)) {
serverLog(LL_WARNING,"Error resurrecting the cached master, impossible to add the writable handler: %s", strerror(errno));
freeClientAsync(server.master); /* Close ASAP. */
}
}
}b. 全量同步
如果是 full resync,在 slaveTryPartialResynchronization 之中会更新 master 的 replid 和 offset 等信息。
这时候,就可以准备接收 master的数据了,我们给 socket 上加一个回调函数,用来接收 rdb data
connSetReadHandler(conn, readSyncBulkPayload)你可以全局搜索上面这行代码,来了解它执行的时机。
5. master rdb 执行完成,发送 rdb data
在 rdb 执行的过程中,serverCron 会一直扫描子进程的状态(serverCron 的默认频率是 10次/秒):
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
······
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
}
······
}checkChildrenDone 检查有没有子进程退出,如果有,根据子进程的任务类型(server.child_type),调用对应的 handler 处理
void checkChildrenDone(void) {
······
// 等待任意子进程结束退出,如果没有(WNOHANG),就立即返回0
// 这样,serverCron 就不会被阻塞住了
if ((pid = waitpid(-1, &statloc, WNOHANG)) != 0) {
······
if (pid == -1) {
serverLog(LL_WARNING,"waitpid() returned an error: %s. "
"child_type: %s, child_pid = %d",
strerror(errno),
strChildType(server.child_type),
(int) server.child_pid);
} else if (pid == server.child_pid) {
if (server.child_type == CHILD_TYPE_RDB) {
// 如果子进程是 rdb
backgroundSaveDoneHandler(exitcode, bysignal);
} else if (server.child_type == CHILD_TYPE_AOF) {
// 如果子进程是 aof rewrite
backgroundRewriteDoneHandler(exitcode, bysignal);
} else if (server.child_type == CHILD_TYPE_MODULE) {
ModuleForkDoneHandler(exitcode, bysignal);
} else {
serverPanic("Unknown child type %d for child pid %d", server.child_type, server.child_pid);
exit(1);
}
if (!bysignal && exitcode == 0) receiveChildInfo();
resetChildState();
} else {
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long) pid);
}
//(RDB 持久化不会为 slave 积累差异的数据,所以没法被 slave 直接使用)
// 检测有没有因为 RDB 持久化而延迟的任务,如果有,就启动它。
replicationStartPendingFork();
}
}backgroundSaveDoneHandler()
/* When a background RDB saving/transfer terminates, call the right handler. */
void backgroundSaveDoneHandler(int exitcode, int bysignal) {
······
/* Possibly there are slaves waiting for a BGSAVE in order to be served
* (the first stage of SYNC is a bulk transfer of dump.rdb) */
updateSlavesWaitingBgsave((!bysignal && exitcode == 0) ? C_OK : C_ERR, type);
}updateSlavesWaitingBgsave 会检测当前连接的所有 slave,如果有 SLAVE_STATE_WAIT_BGSAVE_END(表示等待接受 rdb file)状态的 slave,就会尝试将 rdb file 发送给 slave。
void updateSlavesWaitingBgsave(int bgsaveerr, int type) {
listNode *ln;
listIter li;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END) {
struct redis_stat buf;
······
/* 如果 rdb 是在磁盘上的,我们需要将它发送给 slave。
* 如果是 socket 模式的,那么 rdb 信息已经被发送给 slave 了,
* 我们只需要将它标记位 online 状态。 */
if (type == RDB_CHILD_TYPE_SOCKET) {
serverLog(LL_NOTICE,
"Streamed RDB transfer with replica %s succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming",
replicationGetSlaveName(slave));
/* Note: we wait for a REPLCONF ACK message from the replica in
* order to really put it online (install the write handler
* so that the accumulated data can be transferred). However
* we change the replication state ASAP, since our slave
* is technically online now.
*
* So things work like that:
*
* 1. We end trasnferring the RDB file via socket.
* 2. The replica is put ONLINE but the write handler
* is not installed.
* 3. The replica however goes really online, and pings us
* back via REPLCONF ACK commands.
* 4. Now we finally install the write handler, and send
* the buffers accumulated so far to the replica.
*
* But why we do that? Because the replica, when we stream
* the RDB directly via the socket, must detect the RDB
* EOF (end of file), that is a special random string at the
* end of the RDB (for streamed RDBs we don't know the length
* in advance). Detecting such final EOF string is much
* simpler and less CPU intensive if no more data is sent
* after such final EOF. So we don't want to glue the end of
* the RDB trasfer with the start of the other replication
* data. */
slave->replstate = SLAVE_STATE_ONLINE;
slave->repl_put_online_on_ack = 1;
slave->repl_ack_time = server.unixtime; /* Timeout otherwise. */
} else {
······
// 将 rdb 文件发给 slave
if (connSetWriteHandler(slave->conn,sendBulkToSlave) == C_ERR) {
freeClient(slave);
continue;
}
}
}
}
}void sendBulkToSlave(connection *conn) {
client *slave = connGetPrivateData(conn);
char buf[PROTO_IOBUF_LEN];
ssize_t nwritten, buflen;
/* 先给 slave 发送 RDB 文件的总大小
* Before sending the RDB file, we send the preamble as configured by the
* replication process. Currently the preamble is just the bulk count of
* the file in the form "$<length>\r\n". */
if (slave->replpreamble) {
nwritten = connWrite(conn,slave->replpreamble,sdslen(slave->replpreamble));
······
atomicIncr(server.stat_net_output_bytes, nwritten);
sdsrange(slave->replpreamble,nwritten,-1);
if (sdslen(slave->replpreamble) == 0) {
sdsfree(slave->replpreamble);
slave->replpreamble = NULL;
/* fall through sending data. */
} else {
return;
}
}
/* 发送 RDB data. */
······
if ((nwritten = connWrite(conn,buf,buflen)) == -1) {
if (connGetState(conn) != CONN_STATE_CONNECTED) {
serverLog(LL_WARNING,"Write error sending DB to replica: %s",
connGetLastError(conn));
freeClient(slave);
}
return;
}
slave->repldboff += nwritten;
atomicIncr(server.stat_net_output_bytes, nwritten);
if (slave->repldboff == slave->repldbsize) {
close(slave->repldbfd);
slave->repldbfd = -1;
connSetWriteHandler(slave->conn,NULL);
putSlaveOnline(slave);
}
}注意,在checkChildrenDone方法最后的replicationStartPendingFork方法,如果检测到 pending 的 bgsave for replication(说明本次 RDB 是持久化用的,没有收集持久化过程中的差异命令,不能用来发给 slave),就会重新触发一次 bgsave,检测的标志就是SLAVE_STATE_WAIT_BGSAVE_START,你可以在 syncCommand 方法中搜索它,来查看它是什么时候设置的。
6. slave 接收并加载 rdb data
上文中,slave 在和 master 交换完 replid、offset、psync/sync 之后,为 socket 设置了一个 handler
connSetReadHandler(conn, readSyncBulkPayload)
当 socket 中有数据时,就会唤醒它进行处理:
void readSyncBulkPayload(connection *conn) {
······
/* 这几个 Static 变量用来存储结束符(EOF mark), 当匹配到它时,说明传输结束了 */
static char eofmark[CONFIG_RUN_ID_SIZE];
static char lastbytes[CONFIG_RUN_ID_SIZE];
static int usemark = 0;
······
// 如果 slave 的模式是使用磁盘加载 rdb 文件,则需要把文件下载下来,并 fsync 到磁盘上
if (!use_diskless_load) {
······
// 读数据
nread = connRead(conn,buf,readlen);
······
/* 更新 last I/O time (这个参数是用来判断超时的),并把接受到的数据写进磁盘. */
server.repl_transfer_lastio = server.unixtime;
if ((nwritten = write(server.repl_transfer_fd,buf,nread)) != nread) {
serverLog(LL_WARNING,
"Write error or short write writing to the DB dump file "
"needed for MASTER <-> REPLICA synchronization: %s",
(nwritten == -1) ? strerror(errno) : "short write");
goto error;
}
server.repl_transfer_read += nread;
/* 如果传完了,删掉文件最后的结束符*/
if (usemark && eof_reached) {
if (ftruncate(server.repl_transfer_fd,
server.repl_transfer_read - CONFIG_RUN_ID_SIZE) == -1)
{
serverLog(LL_WARNING,
"Error truncating the RDB file received from the master "
"for SYNC: %s", strerror(errno));
goto error;
}
}
/* 每 8MB 刷一次盘 */
if (server.repl_transfer_read >=
server.repl_transfer_last_fsync_off + REPL_MAX_WRITTEN_BEFORE_FSYNC)
{
off_t sync_size = server.repl_transfer_read -
server.repl_transfer_last_fsync_off;
rdb_fsync_range(server.repl_transfer_fd,
server.repl_transfer_last_fsync_off, sync_size);
server.repl_transfer_last_fsync_off += sync_size;
}
......
/* 如果没传完(没有读到结束符),则直接 return,直到下一次 handler 被唤醒 */
if (!eof_reached) return;
}
/* 以下两种情况,代码会走到这里:
* 1. diskless replication:不使用磁盘做 replication
* 2. 从 master 读到了完整的 RDB file
*/
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Flushing old data");
/* 防止 copy-on-write disaster,需要停掉 aof rewriting */
if (server.aof_state != AOF_OFF) stopAppendOnly();
······
/* 在加载 RDB 到内存文件之前,需要关闭 conn 的 read handler,
* 否则每当我们读数据的时候,eventLoop 就会被唤醒,然后调用 rdbLoad()。
* Before loading the DB into memory we need to delete the readable
* handler, otherwise it will get called recursively since
* rdbLoad() will call the event loop to process events from time to
* time for non blocking loading. */
connSetReadHandler(conn, NULL);
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Loading DB in memory");
rdbSaveInfo rsi = RDB_SAVE_INFO_INIT;
/* 场景1:不使用磁盘做 replication */
if (use_diskless_load) {
rio rdb;
rioInitWithConn(&rdb,conn,server.repl_transfer_size);
/* 设置为 blocking mode 来简化 RDB transfer.
* RDB 数据接收完后,会关闭 blocking mode */
connBlock(conn);
connRecvTimeout(conn, server.repl_timeout*1000);
// 这里,就是从 socket 中持续读数据了
startLoading(server.repl_transfer_size, RDBFLAGS_REPLICATION);
······
stopLoading(1);
/* 清理现场,恢复 non blocking mode */
rioFreeConn(&rdb, NULL);
connNonBlock(conn);
connRecvTimeout(conn,0);
} else {
/* 场景2:从磁盘加载 RDB 文件做 replication */
······
/* 通过重命名的方式,加载从 master 拿到的 rdb 文件 */
int old_rdb_fd = open(server.rdb_filename,O_RDONLY|O_NONBLOCK);
// 把接收到的 tmp file,rename 成正式文件
if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) {
serverLog(LL_WARNING,
"Failed trying to rename the temp DB into %s in "
"MASTER <-> REPLICA synchronization: %s",
server.rdb_filename, strerror(errno));
cancelReplicationHandshake(1);
if (old_rdb_fd != -1) close(old_rdb_fd);
return;
}
······
// 加载 RDB 文件中的数据
if (rdbLoad(server.rdb_filename,&rsi,RDBFLAGS_REPLICATION) != C_OK) {
serverLog(LL_WARNING,
"Failed trying to load the MASTER synchronization "
"DB from disk");
cancelReplicationHandshake(1);
if (server.rdb_del_sync_files && allPersistenceDisabled()) {
serverLog(LL_NOTICE,"Removing the RDB file obtained from "
"the master. This replica has persistence "
"disabled");
bg_unlink(server.rdb_filename);
}
/* Note that there's no point in restarting the AOF on sync failure,
it'll be restarted when sync succeeds or replica promoted. */
return;
}
······
}
/* 保存与 master 的连接信息 */
replicationCreateMasterClient(server.repl_transfer_s,rsi.repl_stream_db);
server.repl_state = REPL_STATE_CONNECTED;
server.repl_down_since = 0;
/* Fire the master link modules event. */
moduleFireServerEvent(REDISMODULE_EVENT_MASTER_LINK_CHANGE,
REDISMODULE_SUBEVENT_MASTER_LINK_UP,
NULL);
/* 记录 master 的 master_replid 和 master_repl_offset(通过 info replication 可以查询到) */
memcpy(server.replid,server.master->replid,sizeof(server.replid));
server.master_repl_offset = server.master->reploff;
······
/* 通知 master 自己当前的 offset,此时,当前 slave 就处于 online 状态了 */
if (usemark) replicationSendAck();
/* 同步完成后,打开 AOF(同时触发 aof rewrite)*/
if (server.aof_enabled) restartAOFAfterSYNC();
return;
error:
cancelReplicationHandshake(1);
return;
}7. 加载 backlog
在上面一段代码的最后,slave 接受完 rdb file 之后,会通过replicationSendAck()发送REPLCONF ACK通知 master。而 master 在收到通知之后,就会把 replication buffer 中(从 bgsave fork 开始)积攒的差异命令发送给 slave。
/* This function should be called just after a replica received the RDB file
* for the initial synchronization, and we are finally ready to send the
* incremental stream of commands.
*
* replica 接受 rdb file 之后,会立刻调用这个方法,此时,我们就可以
* 把增量的命令发给 slave 了
*
* 它的主要功能是重新 install writable event,它在 sync 命令开始的时候就被移除了,
* 原因是防止 rdb file 和 增量命令 混淆。等我们传完 rdb file,就可以装载
* writable event 了,然后通过它,就可以发送增量的命令了(replication buffer)
*
* 注:
* rdb file 是通过直接往 socket 写数据的方式发送的
* 而增量命令,是先写在 socket 的 buffer 里,然后异步地通过事件驱动(writable event)的方式发送的。
*/
void replicaStartCommandStream(client *slave) {
slave->repl_start_cmd_stream_on_ack = 0;
······
clientInstallWriteHandler(slave);
}这里并不是直接往 socket 里写数据,而是添加到一个队列里,这么做的意图下面会介绍
/* This function puts the client in the queue of clients that should write
* their output buffers to the socket. Note that it does not *yet* install
* the write handler, to start clients are put in a queue of clients that need
* to write, so we try to do that before returning in the event loop (see the
* handleClientsWithPendingWrites() function).
* If we fail and there is more data to write, compared to what the socket
* buffers can hold, then we'll really install the handler. */
void clientInstallWriteHandler(client *c) {
/* Schedule the client to write the output buffers to the socket only
* if not already done and, for slaves, if the slave can actually receive
* writes at this stage. */
if (!(c->flags & CLIENT_PENDING_WRITE) &&
(c->replstate == REPL_STATE_NONE ||
(c->replstate == SLAVE_STATE_ONLINE && !c->repl_start_cmd_stream_on_ack)))
{
/* Here instead of installing the write handler, we just flag the
* client and put it into a list of clients that have something
* to write to the socket. This way before re-entering the event
* loop, we can try to directly write to the client sockets avoiding
* a system call. We'll only really install the write handler if
* we'll not be able to write the whole reply at once. */
c->flags |= CLIENT_PENDING_WRITE;
listAddNodeHead(server.clients_pending_write,c);
}
}按照上面注释的要求,我们再读一读 handleClientsWithPendingWrites 方法
/* 原来是为了减少系统调用(install handler、handler called)
* This function is called just before entering the event loop, in the hope
* we can just write the replies to the client output buffer without any
* need to use a syscall in order to install the writable event handler,
* get it called, and so forth. */
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
······
/* Try to write buffers to the client socket. */
if (writeToClient(c,0) == C_ERR) continue;
······
}
}
return processed;
}8. 同步完成
同步完成之后,后续就只需要把 master 收到的命令发一份给 slave 了。即在 master 执行命令的void call(client *c, int flags) 方法最后,会将命令传递给 slave
static void propagateNow(int dbid, robj **argv, int argc, int target) {
if (!shouldPropagate(target))
return;
/* This needs to be unreachable since the dataset should be fixed during
* client pause, otherwise data may be lost during a failover. */
serverAssert(!(areClientsPaused() && !server.client_pause_in_transaction));
if (server.aof_state != AOF_OFF && target & PROPAGATE_AOF)
feedAppendOnlyFile(dbid,argv,argc);
if (target & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}/* Propagate write commands to replication stream.
* 只有 master 能使用这个方法,级联情况下的中间层级,使用的是
* replicationFeedStreamFromMasterStream() */
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {
int j, len;
char llstr[LONG_STR_SIZE];
/* 不操作 keys 的命令,不需要传递给 slave(比如 PING, REPLCONF) */
serverAssert(dictid == -1 || (dictid >= 0 && dictid < server.dbnum));
/* 只有 master 能使用这个方法,其他情况退出 */
if (server.masterhost != NULL) return;
/* no slaves, no backlog buffer */
if (server.repl_backlog == NULL && listLength(slaves) == 0) return;
····
/* Send SELECT command to every slave if needed. */
if (server.slaveseldb != dictid) {
robj *selectcmd;
/* For a few DBs we have pre-computed SELECT command. */
if (dictid >= 0 && dictid < PROTO_SHARED_SELECT_CMDS) {
selectcmd = shared.select[dictid];
} else {
int dictid_len;
dictid_len = ll2string(llstr,sizeof(llstr),dictid);
selectcmd = createObject(OBJ_STRING,
sdscatprintf(sdsempty(),
"*2\r\n$6\r\nSELECT\r\n$%d\r\n%s\r\n",
dictid_len, llstr));
}
feedReplicationBufferWithObject(selectcmd);
if (dictid < 0 || dictid >= PROTO_SHARED_SELECT_CMDS)
decrRefCount(selectcmd);
server.slaveseldb = dictid;
}
/* Write the command to the replication buffer if any. */
char aux[LONG_STR_SIZE+3];
/* Add the multi bulk reply length. */
aux[0] = '*';
len = ll2string(aux+1,sizeof(aux)-1,argc);
aux[len+1] = '\r';
aux[len+2] = '\n';
feedReplicationBuffer(aux,len+3);
for (j = 0; j < argc; j++) {
long objlen = stringObjectLen(argv[j]);
/* We need to feed the buffer with the object as a bulk reply
* not just as a plain string, so create the $..CRLF payload len
* and add the final CRLF */
aux[0] = '$';
len = ll2string(aux+1,sizeof(aux)-1,objlen);
aux[len+1] = '\r';
aux[len+2] = '\n';
feedReplicationBuffer(aux,len+3);
feedReplicationBufferWithObject(argv[j]);
feedReplicationBuffer(aux+len+1,2);
}
}三、过期 key 的淘汰(つづく)
这篇文章写太久了,需要换换脑子,这部分内容暂时搁置
四、后记
在这片文章写到差不多 80% 的时候,在 redis 的 readme.txt 中看到这段话
replication.c
This is one of the most complex files inside Redis, it is recommended to
approach it only after getting a bit familiar with the rest of the code base.
In this file there is the implementation of both the master and replica role
of Redis.我果然是天选之子,稀里糊涂捡了一块最难啃的骨头,不好还好勉强读下来了,还为 redis 的源码贡献了两个 pull request
Fix outdated comments on updateSlavesWaitingBgsave
Fix a mistake in comments
加油加油,继续下一个话题~
