上一篇文章,我们了解了主从库集群模式。在这个模式下,如果从库发生故障了,可以通过 psync/sync 重新进行同步。那么如果主库发生了故障,我们该怎么办呢?
这时候我们就需要一个新主库,比方说把一个从库切换为主库。这就涉及到三个问题:
- 主库真的挂了吗?
- 该选择哪个从库作为主库?
- 怎么把新主库的相关信息通知给从库和客户端呢?
为了解决这些问题,redis 引入了哨兵机制。在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了上面三个问题。
一、哨兵模式
哨兵其实就是一个运行在特殊模式下的 Redis 进程,主从库实例运行的同时,它也在运行。哨兵主要负责的就是三个任务:监控、选主和通知
1. 监控
监控是指哨兵进程在运行时,周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行。如果实例没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为“下线状态”;如果它是主库的话,哨兵就会判定主库下线,然后开始自动切换主库的流程。
1. 主观下线”和“客观下线”
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态。
如果哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为“主观下线”(S_DOWN, Subjectively Down)。
如果检测的是从库,那么,哨兵简单地把它标记为“主观下线”就行了,因为从库的下线影响一般不太大,集群的对外服务不会间断。
但是,如果检测的是主库,那么,哨兵还不能简单地把它标记为“主观下线”,开启主从切换。因为很有可能存在这么一个情况:那就是哨兵误判了,其实主库并没有故障。可是,一旦启动了主从切换,后续的选主和通知操作都会带来额外的计算和通信开销。为了避免这些不必要的开销,我们要特别注意误判的情况。
误判一般会发生在集群网络压力较大、网络拥塞,或者是主库本身压力较大的情况下。所以,哨兵机制采用多实例组成的集群模式进行部署,这也被称为哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。在判断主库是否下线时,不能由一个哨兵说了算,只有大多数的哨兵实例,都判断主库已经“主观下线”了,主库才会被标记为“客观下线”(O_DOWN, Objectively Down),这个叫法也是表明主库下线成为一个客观事实了,然后会进一步触发哨兵开始主从切换流程。
2. 选主
主库挂了以后,哨兵就需要从很多个从库里,按照一定的规则选择一个从库实例,把它作为新的主库。这一步完成后,现在的集群里就有了新主库。
1. 筛选
一般来说,我把哨兵选择新主库的过程称为“筛选 + 打分”。简单来说,我们在多个从库中,先按照一定的筛选条件,把不符合条件的从库去掉。然后,我们再按照一定的规则,给剩下的从库逐个打分,将得分最高的从库选为新主库。
具体怎么判断呢?
- sdown 的 slave 淘汰掉
- 断连的 slave 淘汰掉
- 配置项 down-after-milliseconds,如果在 down-after-milliseconds 毫秒内,我们(sentinel)都没有连接上 master,我们就可以认为主从节点断连了。如果某个 slave 和 master 断开连接超过了 10*down-after-milliseconds,就给它淘汰掉。
- sentinel_ping_period(1s): slave 每次收到 master 的 INFO 命令,就会更新 info_refresh 时间,如果 slave 的 info_refresh 参数距今大于 5*sentinel_ping_period,也给它淘汰掉。
·····
在下面的源码阅读部分,会再做详细的介绍。
2. 打分
接下来就要给剩余的从库打分了。我们可以分别按照三个规则依次进行三轮打分,这三个规则分别是从库优先级、从库复制进度以及从库 ID 号。只要在某一轮中,有从库得分最高,那么它就是主库了,选主过程到此结束。
如果没有出现得分最高的从库,那么就继续进行下一轮。
从库优先级:优先级最高的从库得分高。用户可以通过 slave-priority 配置项,给不同的从库设置不同优先级。比如,你有两个从库,它们的内存大小不一样,你可以手动给内存大的实例设置一个高优先级。在选主时,哨兵会给优先级高的从库打高分,如果有一个从库优先级最高,那么它就是新主库了。如果从库的优先级都一样,那么哨兵开始第二轮打分。
从库复制进度:和旧主库同步程度最接近的从库得分高。(replication backlog buffer 的 offset)
从库 ID 号:在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库(最小的说明最早连接上,数据也就最全,能活到现在也就最稳定,毕竟久经考验)
3. 通知
选定新的 master 后,哨兵会把新主库的连接信息发给其他从库,让它们执行 replicaof 命令,和新主库建立连接,并进行数据复制(这个过程可以参考Redis 详解之高可靠主线 - 主从复制)。
同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。
二、哨兵集群
为了降低误判率,在实际应用时,哨兵机制通常采用多实例的方式进行部署,多个哨兵实例通过“少数服从多数”的原则,来判断主库是否客观下线。一般来说,我们可以部署 2n+1 个哨兵,如果有 n+1 个哨兵认定主库“主观下线”,就可以开始切换过程。但是,引入多个哨兵的时候,我们有面临着一些新的问题,例如:哨兵集群中有实例挂了,怎么办,会影响主库状态判断和选主吗?哨兵集群多数实例达成共识,判断出主库“客观下线”后,由哪个实例来执行主从切换呢?
还有一个问题,在配置哨兵的信息时,我们只需要用到下面的这个配置项,设置主库的 IP 和端口。
sentinel monitor <master-name> <ip> <redis-port> <quorum>我们并没有配置其他哨兵的连接信息,既然这些哨兵实例都不知道彼此的地址,又是怎么组成集群的呢?要弄明白这个问题,我们就需要了解一下哨兵集群的组成和运行机制了。
1. 基于 pub/sub 机制的哨兵集群组成
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅机制。
哨兵只要和主库建立起了连接,就可以在主库上发布消息了,比如说发布它自己的连接信息(IP 和端口)。同时,它也可以从主库上订阅消息,获得其他哨兵发布的连接信息。当多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。
事实上哨兵和主备集群中的每个节点都有两个连接,命令(commands)连接和发布订阅(Pub/Sub)连接,而哨兵之间只保留命令连接。
除了哨兵实例,我们自己编写的应用程序也可以通过 Redis 进行消息的发布和订阅。所以,为了区分不同应用的消息,Redis 会以频道的形式,对这些消息进行分门别类的管理。所谓的频道,实际上就是消息的类别。当消息类别相同时,它们就属于同一个频道。反之,就属于不同的频道。只有订阅了同一个频道的应用,才能通过发布的消息进行信息交换。
在主从集群中,主库上有一个名为__sentinel__:hello的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
哨兵除了彼此之间建立起连接形成集群外,还需要和从库建立连接。这是因为,在哨兵的监控任务中,它需要对主从库都进行心跳判断,而且在主从库切换完成后,它还需要通知从库,让它们和新主库进行同步。
那么,哨兵是如何知道从库的 IP 地址和端口的呢?
这是由哨兵向主库发送 INFO 命令来完成的。主库接受到这个命令后,就会把从库列表返回给哨兵。接着,哨兵就可以根据从库列表中的连接信息,和每个从库建立连接,并在这个连接上持续地对从库进行监控。
2. 基于 pub/sub 机制的客户端事件通知
从本质上说,哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。所以,每个哨兵实例也提供 pub/sub 机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。
下面列出几个重要的频道
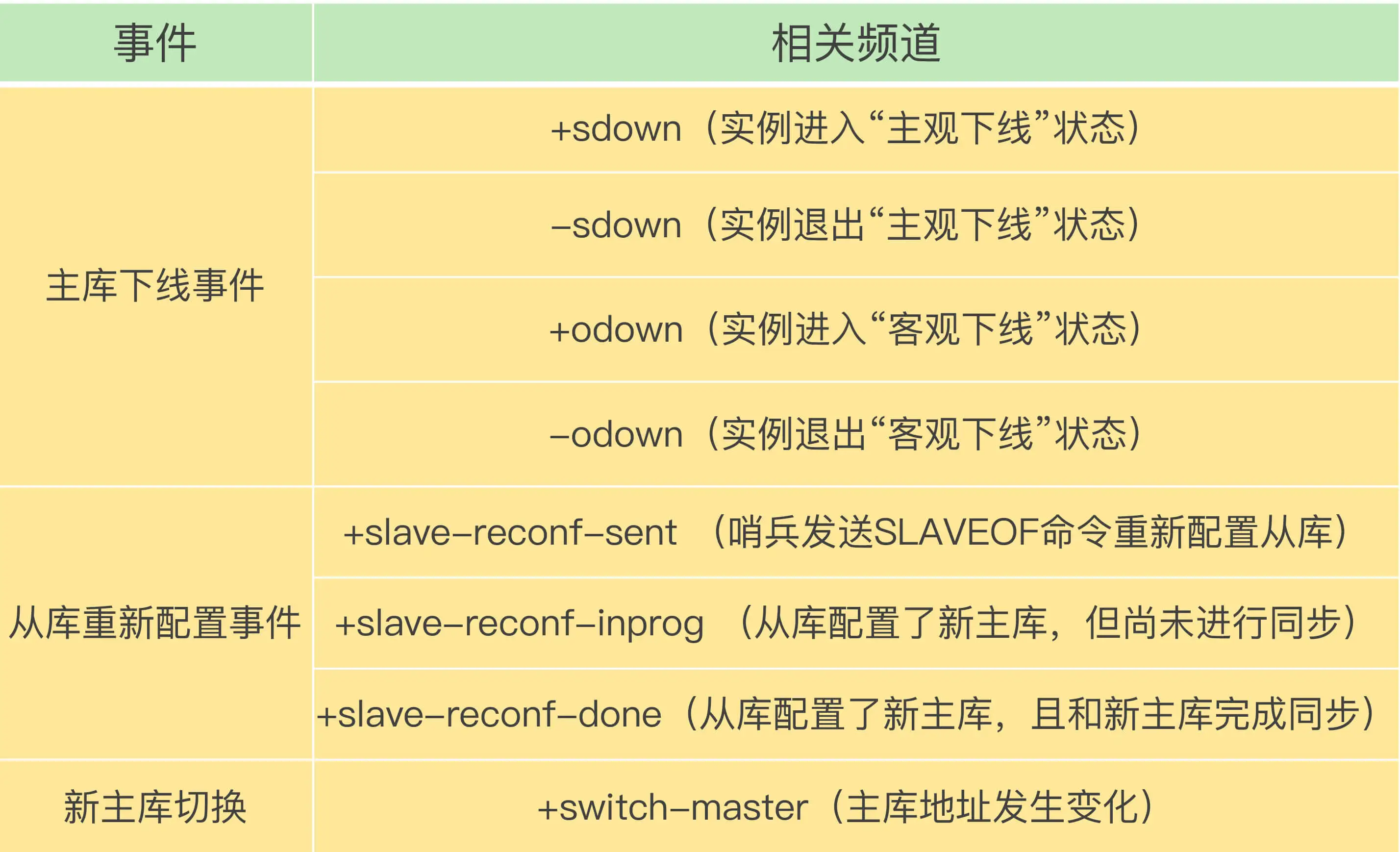
知道了这些频道之后,你就可以让客户端从哨兵这里订阅消息了。具体的操作步骤是,客户端读取哨兵的配置文件(sentinel.conf)后,可以获得哨兵的地址和端口,和哨兵建立网络连接。然后,我们可以在客户端执行订阅命令,来获取不同的事件消息.
举个例子,你可以执行如下命令,来订阅“所有实例进入客观下线状态的事件”
SUBSCRIBE +odown当哨兵把新主库选择出来后,客户端就会看到下面的 switch-master 事件。这个事件表示主库已经切换了,新主库的 IP 地址和端口信息已经有了。这个时候,客户端就可以用这里面的新主库地址和端口进行通信了。
switch-master <master name> <oldip> <oldport> <newip> <newport>到了这里,哨兵集群的监控、选主和通知三个任务就基本可以正常工作了。
不过,我们还需要考虑一个问题:主库故障以后,哨兵集群有多个实例,那怎么确定由哪个哨兵来进行实际的主从切换呢?
确定由哪个哨兵执行主从切换的过程,和主库“客观下线”的判断过程类似,也是一个“投票仲裁”的过程。
-
sentinel 会通过 is-master-down-by-addr 命令,定时与其他 sentinel 交换信息。
-
任何一个哨兵实例只要自身判断主库“主观下线”后,就会 check 交换获得的信息,如果有至少 quorum 个 sentinel 都认为 master 主观下线了,那就可以标记主库为“客观下线”。
-
此时,这个哨兵就可以再给其他哨兵发送命令(is-master-down-by-addr 命令,其中携带者自己的 runid,表示发起投票,并且自己投自己一票),表明希望由自己来执行主从切换,并让所有其他哨兵进行投票。这个投票过程称为“Leader 选举”。因为最终执行主从切换的哨兵称为 Leader,投票过程就是确定 Leader。
-
在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。以 3 个哨兵为例,假设此时的 quorum 设置为 2,那么,任何一个想成为 Leader 的哨兵只要拿到 2 张赞成票,就可以了。
源码
A. sentinelTimer
在我们熟悉的 serverCron 中,有一个处理 sentinel 事务的定时器,只有哨兵模式下的 redis 实例会运行这个定时器:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
······
/* Run the Sentinel timer if we are in sentinel mode. */
if (server.sentinel_mode) sentinelTimer();
······
}
sentinel 相关的核心工作都在这个定时器里运行:
void sentinelTimer(void) {
// 检查服务器时间异常
sentinelCheckTiltCondition();
// 监控、选主、通知等核心任务
sentinelHandleDictOfRedisInstances(sentinel.masters);
// fork 子进程执行脚本任务,比如通知 client、用户自定义脚本
sentinelRunPendingScripts();
// 收集终止的脚本任务,符合条件的进行重试
sentinelCollectTerminatedScripts();
// 干掉上面 fork 出来的超时的子进程
sentinelKillTimedoutScripts();
// 这里给循环的时间加了一个小的随机量,是为了防止所有的 sentinel 同时
// 发现自己 master 断连、同时发起投票、同时投给自己的情况出现。
// 实际情况下,这种情况极难出现,就算出现了,也只会导致本轮投票失败,
// 然后就会等到下一次循环再做投票。
server.hz = CONFIG_DEFAULT_HZ + rand() % CONFIG_DEFAULT_HZ;
}timer 的整体执行流程如下:

下面,我们依次来看 sentinelTimer 中的这几个方法
1. TILE mode(系统时钟异常)
/* This function checks if we need to enter the TILT mode.
*
* 由于 redis sentinel 机制极度依赖系统时间,所以 redis 提供了
* TILT 模式,目的是当 redis 探测到系统时间发生异常时
*(比如上次 timer 调用的时间比当前时间晚,或者早 2s 以上)
* 自动进入 protection mode。
* 在进入 TILE mode 之后,
* 1. sentinel 的监控功能正常运行,除此之外不再做其他事情
* 2. 对 SENTINEL is-master-down-by-addr 请求答复 负数,
* 表示自己处于异常状态,自己的应答不可信
* 当时间异常恢复 30s 之后,就会退出 TILT 模式
*
* 其他可以引起时间异常的情况:
* 1) The Sentinel process for some time is blocked, for every kind of
* random reason: the load is huge, the computer was frozen for some time
* in I/O or alike, the process was stopped by a signal. Everything.
* 2) The system clock was altered significantly.
*
* During TILT time we still collect information, we just do not act.
*/
void sentinelCheckTiltCondition(void) {
mstime_t now = mstime();
mstime_t delta = now - sentinel.previous_time;
if (delta < 0 || delta > sentinel_tilt_trigger) {
sentinel.tilt = 1;
sentinel.tilt_start_time = mstime();
sentinelEvent(LL_WARNING,"+tilt",NULL,"#tilt mode entered");
}
sentinel.previous_time = mstime();
}2. 监控、选主、通知
再看sentinelHandleDictOfRedisInstances 这个核心方法之前,我们需要先了解哨兵是如何保存 master、slaves 以及其他哨兵的信息的
下面的 sentinelState 是 redis 哨兵的核心数据;有两个字段需要注意下:
一是current_epoch字段,它是一个从 0 开始的计数器,在投票过程中起着版本号的作用,每次发起投票前,sentinel 就会给它的值加一。sentinel 会定期互相发送 HELLO 命令交换信息,其中就包含着 current_epoch 信息,如果发现更大的值,就刷新到本地。所以,一个哨兵集群中的 current_epoch 值会逐渐地趋于一致。另外,对每一轮投票(每一个 epoch),sentinel 只会投一次票,如果哨兵发现投票请求中携带的 epoch 值和本地的 current_epoch 一样,就会把之前的投票结果发出去。
二是dict *masters字段,它是一个字典(哈希)结构,存储着所有的 master 的信息
/* Main state. */
struct sentinelState {
char myid[CONFIG_RUN_ID_SIZE+1]; /* This sentinel ID. */
uint64_t current_epoch; /* Current epoch. */
dict *masters; /* Dictionary of master sentinelRedisInstances.
Key is the instance name, value is the
sentinelRedisInstance structure pointer. */
int tilt; /* Are we in TILT mode? */
mstime_t tilt_start_time; /* TITL 模式开始的时间. */
mstime_t previous_time; /* 上一次 sentinel timer 运行的时间,用来判断 TITL 模式 */
list *scripts_queue; /* Queue of user scripts to execute. */
char *announce_ip; /* IP addr that is gossiped to other sentinels if not NULL. */
int announce_port; /* Port that is gossiped to other sentinels if non zero. */
······
} sentinel;对于一个 sentinel 实例来说,所有的 master、slave、sentinel,都是下面的结构体:
typedef struct sentinelRedisInstance {
int flags; /* See SRI_... defines */
char *name; /* Master name from the point of view of this sentinel. */
char *runid; /* Run ID of this instance, or unique ID if is a Sentinel.*/
uint64_t config_epoch; /* Configuration epoch. */
sentinelAddr *addr; /* Master host. */
instanceLink *link; /* Link to the instance, may be shared for Sentinels. */
mstime_t last_pub_time; /* Last time we sent hello via Pub/Sub. */
mstime_t last_hello_time; /* Only used if SRI_SENTINEL is set. Last time
we received a hello from this Sentinel
via Pub/Sub. */
mstime_t last_master_down_reply_time; /* Time of last reply to
SENTINEL is-master-down command. */
mstime_t s_down_since_time; /* Subjectively down since time. */
mstime_t o_down_since_time; /* Objectively down since time. */
mstime_t down_after_period; /* Consider it down after that period. */
mstime_t master_reboot_down_after_period; /* Consider master down after that period. */
mstime_t master_reboot_since_time; /* master reboot time since time. */
mstime_t info_refresh; /* Time at which we received INFO output from it. */
dict *renamed_commands; /* Commands renamed in this instance:
Sentinel will use the alternative commands
mapped on this table to send things like
SLAVEOF, CONFING, INFO, ... */
/* Role and the first time we observed it.
* This is useful in order to delay replacing what the instance reports
* with our own configuration. We need to always wait some time in order
* to give a chance to the leader to report the new configuration before
* we do silly things. */
int role_reported;
mstime_t role_reported_time;
mstime_t slave_conf_change_time; /* Last time slave master addr changed. */
/* Master specific. */
dict *sentinels; /* Other sentinels monitoring the same master. */
dict *slaves; /* Slaves for this master instance. */
unsigned int quorum;/* Number of sentinels that need to agree on failure. */
int parallel_syncs; /* How many slaves to reconfigure at same time. */
char *auth_pass; /* Password to use for AUTH against master & replica. */
char *auth_user; /* Username for ACLs AUTH against master & replica. */
/* Slave specific. */
mstime_t master_link_down_time; /* Slave replication link down time. */
int slave_priority; /* Slave priority according to its INFO output. */
int replica_announced; /* Replica announcing according to its INFO output. */
mstime_t slave_reconf_sent_time; /* Time at which we sent SLAVE OF <new> */
struct sentinelRedisInstance *master; /* Master instance if it's slave. */
char *slave_master_host; /* Master host as reported by INFO */
int slave_master_port; /* Master port as reported by INFO */
int slave_master_link_status; /* Master link status as reported by INFO */
unsigned long long slave_repl_offset; /* Slave replication offset. */
/* Failover */
char *leader; /* If this is a master instance, this is the runid of
the Sentinel that should perform the failover. If
this is a Sentinel, this is the runid of the Sentinel
that this Sentinel voted as leader. */
uint64_t leader_epoch; /* Epoch of the 'leader' field. */
uint64_t failover_epoch; /* Epoch of the currently started failover. */
int failover_state; /* See SENTINEL_FAILOVER_STATE_* defines. */
mstime_t failover_state_change_time;
mstime_t failover_start_time; /* Last failover attempt start time. */
mstime_t failover_timeout; /* Max time to refresh failover state. */
mstime_t failover_delay_logged; /* For what failover_start_time value we
logged the failover delay. */
struct sentinelRedisInstance *promoted_slave; /* Promoted slave instance. */
} sentinelRedisInstance;我们注意这两个字段:
dict *sentinels; /* Other sentinels monitoring the same master. */
dict *slaves; /* Slaves for this master instance. */也就是说,每个实例,还保存着它的所有 slave 和 sentinel 信息,他们也都是sentinelRedisInstance结构。
所以,我们就可以知道,哨兵是通过下面的结构,保存着所有的实例信息的:

有了这样的 map 结构(其实是 redis 的 dict),从 SentinelState 出发,就可以遍历到所有的 master、slave、sentinel 节点了,这就是哨兵可以监视集群中所有实例的原因了。
现在,我们再回到 sentinelTimer 的sentinelHandleDictOfRedisInstances 方法来,它的主要功能,就是遍历上面的 map:
/* Perform scheduled operations for all the instances in the dictionary.
* Recursively call the function against dictionaries of slaves. */
void sentinelHandleDictOfRedisInstances(dict *instances) {
dictIterator *di;
dictEntry *de;
sentinelRedisInstance *switch_to_promoted = NULL;
/* 这里迭代的作用就很清晰了,递归的遍历 master 的所有 salve、sentinel
* 对每个节点(sentinelRedisInstance)调用 sentinelHandleRedisInstance 方法*/
di = dictGetIterator(instances);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
sentinelHandleRedisInstance(ri);
if (ri->flags & SRI_MASTER) {
sentinelHandleDictOfRedisInstances(ri->slaves);
sentinelHandleDictOfRedisInstances(ri->sentinels);
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
switch_to_promoted = ri;
}
}
}
// 如果发现有主从切换运行结束,在这里更新上面提到的全局的字典树
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
dictReleaseIterator(di);
}对每个 sentinel redis instance 都会执行下面的操作:
/* Perform scheduled operations for the specified Redis instance. */
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
/* ========== MONITORING HALF ============ */
// 如果命令连接(command)或订阅连接(pub/sub)中断,尝试重新连接
sentinelReconnectInstance(ri);
// 定时发送 ping、info、hello 命令,(异步地)处理返回值,更新连接信息
sentinelSendPeriodicCommands(ri);
/* ============== ACTING HALF ============= */
/* TILT 模式下,不执行后续的代码,直接 return */
if (sentinel.tilt) {
if (mstime()-sentinel.tilt_start_time < sentinel_tilt_period) return;
sentinel.tilt = 0;
sentinelEvent(LL_WARNING,"-tilt",NULL,"#tilt mode exited");
}
/* 判断实例是否主观下线 */
sentinelCheckSubjectivelyDown(ri);
/* 如果 slave 挂了就挂了,不会对集群的业务造成影响,
* 等待后续 timer 重连就可以了。
* 针对 master 节点,就要判断是否客观下线了 */
if (ri->flags & SRI_MASTER) {
// 判断 master 是否客观下线
sentinelCheckObjectivelyDown(ri);
// 对客观下线(SRI_O_DOWN,Sentinel Redis Instance Objectively Down)
// 状态的 master 执行故障转移(failover)
// 发起新一轮投票:给全局的故障转移计数器 current_epoch+1
if (sentinelStartFailoverIfNeeded(ri))
// master 已经客观下线,向其他哨兵发起投票,尝试切换 master。
// 如果某个哨兵的的票数达到了:
// 1. quronum
// 2. 2n+1
// 就由他主持切换过程。否则就轮空,下次 timer 再重新投票。
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
// 切换 master 的核心流程:根据 failover_state 标志位的状态,执行任务,比如:
// 挑选新 master、slave 升主、其他 slave 连接新 master......
sentinelFailoverStateMachine(ri);
// 和其他 sentinel 交换信息,为下一轮任务(主要是判断客观下线)收集数据
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS);
}
}1. 断线重连
void sentinelReconnectInstance(sentinelRedisInstance *ri) {
if (ri->link->disconnected == 0) return;
······
/* Commands connection. */
if (link->cc == NULL) {
······
link->cc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,server.bind_source_addr);
······
if (!link->cc) {
······
} else {
link->pending_commands = 0;
link->cc_conn_time = mstime();
link->cc->data = link;
// 绑定到 ae 事件循环,后续就可以处理连接的数据了
redisAeAttach(server.el,link->cc);
// 如果连接失败,清理连接的 Context
redisAsyncSetConnectCallback(link->cc,
sentinelLinkEstablishedCallback);
// 如果连接断开,清理连接的 Context
redisAsyncSetDisconnectCallback(link->cc,
sentinelDisconnectCallback);
sentinelSendAuthIfNeeded(ri,link->cc);
// 使用 CLIENT SETNAME sentinel-<first_8_chars_of_runid>-<connection_type> 命令
// 为连接设置名称 (connection_type 取 "cmd"(命令连接) 或 "pubsub"(订阅连接))
sentinelSetClientName(ri,link->cc,"cmd");
// 重连之后,再 ping 一次,用来刷新 act_ping_time
sentinelSendPing(ri);
}
}
/* Pub / Sub */
if ((ri->flags & (SRI_MASTER|SRI_SLAVE)) && link->pc == NULL) {
link->pc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,server.bind_source_addr);
······
if (!link->pc) {
······
} else {
int retval;
link->pc_conn_time = mstime();
link->pc->data = link;
redisAeAttach(server.el,link->pc);
redisAsyncSetConnectCallback(link->pc,
sentinelLinkEstablishedCallback);
redisAsyncSetDisconnectCallback(link->pc,
sentinelDisconnectCallback);
sentinelSendAuthIfNeeded(ri,link->pc);
sentinelSetClientName(ri,link->pc,"pubsub");
/* 订阅 master 的 "Hello" channel,用来获取其他 sentinel 的信息 */
retval = redisAsyncCommand(link->pc,
sentinelReceiveHelloMessages, ri, "%s %s",
sentinelInstanceMapCommand(ri,"SUBSCRIBE"),
SENTINEL_HELLO_CHANNEL);
if (retval != C_OK) {
/* If we can't subscribe, the Pub/Sub connection is useless
* and we can simply disconnect it and try again. */
instanceLinkCloseConnection(link,link->pc);
return;
}
}
}
/* 当命令连接和订阅连接都 ok 的时候,才会清理 disconnected 标志位
* (对于 sentinel 实例,只验证命令连接) */
if (link->cc && (ri->flags & SRI_SENTINEL || link->pc))
link->disconnected = 0;
}2. 执行定时命令
这里的命令有三类:
PING
计算与其他 sentinel、master、slave 最后 ping-pong 的成功时间,为主观下线提供判断依据。
INFO
向 master 和 slave 发送 info 命令,为判断主观下线收集信息、读取新加入集群的 slave 地址、读取 salve 的优先级、复制 offset、管理主->从切换、从->主切换 等等;由于 info 命令拿到的数据比较多,所以执行的操作也比较多,具体内容可以全局搜索 sentinelRefreshInstanceInfo 方法看到。
HELLO
向 sentinel:hello channel 发布消息,主要包括 1.自身的信息:用于组建 sentinel 集群 2.master的信息
/* Send periodic PING, INFO, and PUBLISH to the Hello channel to
* the specified master or slave instance. */
void sentinelSendPeriodicCommands(sentinelRedisInstance *ri) {
mstime_t now = mstime();
mstime_t info_period, ping_period;
int retval;
······
/* 对于已经 O_DOWN 的 master,我们提高向它的 slaves 发送 INFO 命令的频率
* (从 SENTINEL_INFO_PERIOD = 10s/次 到 1s/次)
* 因为它们之中可能会有新的 master 诞生. */
if ((ri->flags & SRI_SLAVE) &&
((ri->master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS)) ||
(ri->master_link_down_time != 0)))
{
info_period = 1000;
} else {
info_period = sentinel_info_period;
}
/* 如果配置文件中 'down-after-milliseconds' 的值大于 1s,
* 那我们就每秒 ping 一次;如果小于 1s,那么每 down-after-milliseconds
* ping 一次 */
ping_period = ri->down_after_period;
if (ping_period > sentinel_ping_period) ping_period = sentinel_ping_period;
/* 向 masters 和 slaves 发送 INFO 命令 */
if ((ri->flags & SRI_SENTINEL) == 0 &&
(ri->info_refresh == 0 ||
(now - ri->info_refresh) > info_period))
{
retval = redisAsyncCommand(ri->link->cc,
sentinelInfoReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri,"INFO"));
if (retval == C_OK) ri->link->pending_commands++;
}
/* 向所有类型的实例发送 PING 命令
* 主要是为了更新 last_ping_time 信息,判断是否长时间失联 */
if ((now - ri->link->last_pong_time) > ping_period &&
(now - ri->link->last_ping_time) > ping_period/2) {
sentinelSendPing(ri);
}
/* 向所有类型的实例,PUBLISH hello 信息,信息内容包括
* 1. master 的信息:master_name,master_ip,master_port,master_config_epoch
* 2. 自身的信息:sentinel_ip,sentinel_port,sentinel_runid,current_epoch
*/
if ((now - ri->last_pub_time) > sentinel_publish_period) {
sentinelSendHello(ri);
}
}a. ping 命令
如果 ping 成功了,就更新 act_ping_time,这是判断主观下线的重要依据之一
int sentinelSendPing(sentinelRedisInstance *ri) {
int retval = redisAsyncCommand(ri->link->cc,
sentinelPingReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri,"PING"));
if (retval == C_OK) {
ri->link->pending_commands++;
ri->link->last_ping_time = mstime();
/* We update the active ping time only if we received the pong for
* the previous ping, otherwise we are technically waiting since the
* first ping that did not receive a reply. */
if (ri->link->act_ping_time == 0)
ri->link->act_ping_time = ri->link->last_ping_time;
return 1;
} else {
return 0;
}
}b. info 命令
既然向其他实例发送了 info 命令,就会有对应的 handler 来处理,也就是上面代码中的sentinelInfoReplyCallback。哨兵拿到了 info 命令返回的实例的信息之后,最重要的是刷新一下本地的信息,也就是上面提到的 sentinel redis instance 字典,这里更新的信息,为主观下线等后续步骤提供了依据:
/* Process the INFO output from masters. */
void sentinelRefreshInstanceInfo(sentinelRedisInstance *ri, const char *info) {
......
/* Process line by line. */
lines = sdssplitlen(info,strlen(info),"\r\n",2,&numlines);
for (j = 0; j < numlines; j++) {
sentinelRedisInstance *slave;
sds l = lines[j];
/* 读 run_id:<40 hex chars>*/
if (sdslen(l) >= 47 && !memcmp(l,"run_id:",7)) {
······
}
/* 读 slave 的 ip:port,并把它更新到 sentinel redis instance 字典里 */
if ((ri->flags & SRI_MASTER) &&
sdslen(l) >= 7 &&
!memcmp(l,"slave",5) && isdigit(l[5]))
{······}
/* 读取和 master 失联的时间 */
if (sdslen(l) >= 32 &&
!memcmp(l,"master_link_down_since_seconds",30))
{······}
/* 读取角色信息 role:<role> */
if (sdslen(l) >= 11 && !memcmp(l,"role:master",11)) role = SRI_MASTER;
else if (sdslen(l) >= 10 && !memcmp(l,"role:slave",10)) role = SRI_SLAVE;
/* slave 节点要额外读取同步信息、优先级等信息 */
if (role == SRI_SLAVE) {
/* master_host:<host> */
/* master_port:<port> */
/* master_link_status:<status> */
/* slave_priority:<priority> */
/* slave_repl_offset:<offset> */
/* replica_announced:<announcement> */
}
}
······
/* ---------------------------- Acting half -----------------------------
* Some things will not happen if sentinel.tilt is true, but some will
* still be processed. */
/* Remember new role and when the role changed.
* (被别的 sentinel 切成了 master)*/
if (role != ri->role_reported) {
ri->role_reported_time = mstime();
ri->role_reported = role;
if (role == SRI_SLAVE) ri->slave_conf_change_time = mstime();
}
/* None of the following conditions are processed when in tilt mode, so
* return asap. */
if (sentinel.tilt) return;
······
/* 处理 master -> slave 切换. */
if ((ri->flags & SRI_MASTER) && role == SRI_SLAVE) {
/* Nothing to do, but masters claiming to be slaves are
* considered to be unreachable by Sentinel, so eventually
* a failover will be triggered. */
}
/* 处理 slave -> master 切换 */
if ((ri->flags & SRI_SLAVE) && role == SRI_MASTER) {
/* 如果 slave 收到了升主通知,完成升主之后,sentinel 就会在这里拿到信息
* 更改当前节点的状态,准备让集群中其他的 slave 认它做 master
* (这里只更改状态,具体操作可以全局搜索 SENTINEL_FAILOVER_STATE_RECONF_SLAVES 字段)*/
if ((ri->flags & SRI_PROMOTED) &&
(ri->master->flags & SRI_FAILOVER_IN_PROGRESS) &&
(ri->master->failover_state ==
SENTINEL_FAILOVER_STATE_WAIT_PROMOTION))
{ ······
ri->master->failover_state = SENTINEL_FAILOVER_STATE_RECONF_SLAVES;
······
// 设置一个任务用来通知 client 修改配置,并把任务塞进队列中
sentinelCallClientReconfScript(ri->master,SENTINEL_LEADER,
"start",ri->master->addr,ri->addr);
// 重置 last_pub_time 字段,在下一次 cron 中,
// 会向旧 master 下面的其他 sentinel\slave 节点
// PUBLISH HELLO 信息:
// 1. 新 master 的信息:master_name,master_ip,master_port,master_config_epoch
// (其他 sentinel 如果发现 master 发生改变,就会去连接新 master,参考方法:sentinelProcessHelloMessage)
// 2. 自身的信息:sentinel_ip,sentinel_port,sentinel_runid,current_epoch
sentinelForceHelloUpdateForMaster(ri->master);
} else {
/* 集群切换了新的 master 之后,原来的 master 如果又能连接上了,
* 这个时候它仍然认为自己是 master,而在 sentinelResetMasterAndChangeAddress,
* 方法中,我们(sentinel)已经把它当做了 slave。
* 所以为了防止集群脑裂,这里 sentinel 会让旧 master 作为 slave 去连接新的 master
**/
mstime_t wait_time = sentinel_publish_period*4;
if (!(ri->flags & SRI_PROMOTED) &&
sentinelMasterLooksSane(ri->master) &&
sentinelRedisInstanceNoDownFor(ri,wait_time) &&
mstime() - ri->role_reported_time > wait_time)
{
int retval = sentinelSendSlaveOf(ri,ri->master->addr);
}
}
}
/* Handle slaves replicating to a different master address. */
if ((ri->flags & SRI_SLAVE) &&
role == SRI_SLAVE &&
(ri->slave_master_port != ri->master->addr->port ||
!sentinelAddrEqualsHostname(ri->master->addr, ri->slave_master_host)))
{
mstime_t wait_time = ri->master->failover_timeout;
/* Make sure the master is sane before reconfiguring this instance
* into a slave. */
if (sentinelMasterLooksSane(ri->master) &&
sentinelRedisInstanceNoDownFor(ri,wait_time) &&
mstime() - ri->slave_conf_change_time > wait_time)
{
int retval = sentinelSendSlaveOf(ri,ri->master->addr);
if (retval == C_OK)
sentinelEvent(LL_NOTICE,"+fix-slave-config",ri,"%@");
}
}
/* Detect if the slave that is in the process of being reconfigured
* changed state. */
if ((ri->flags & SRI_SLAVE) && role == SRI_SLAVE &&
(ri->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG)))
{
/* SRI_RECONF_SENT -> SRI_RECONF_INPROG. */
if ((ri->flags & SRI_RECONF_SENT) &&
ri->slave_master_host &&
sentinelAddrEqualsHostname(ri->master->promoted_slave->addr,
ri->slave_master_host) &&
ri->slave_master_port == ri->master->promoted_slave->addr->port)
{
ri->flags &= ~SRI_RECONF_SENT;
ri->flags |= SRI_RECONF_INPROG;
sentinelEvent(LL_NOTICE,"+slave-reconf-inprog",ri,"%@");
}
/* SRI_RECONF_INPROG -> SRI_RECONF_DONE */
if ((ri->flags & SRI_RECONF_INPROG) &&
ri->slave_master_link_status == SENTINEL_MASTER_LINK_STATUS_UP)
{
ri->flags &= ~SRI_RECONF_INPROG;
ri->flags |= SRI_RECONF_DONE;
sentinelEvent(LL_NOTICE,"+slave-reconf-done",ri,"%@");
}
}
}c. hello
在 pub/sub 中广播之后,回调函数中只是更新了ri->last_pub_time信息,我们就不展开看了。
我们来读一读其他实例收到 hello 之后的处理流程:
/* Process a hello message received via Pub/Sub in master or slave instance,
* or sent directly to this sentinel via the (fake) PUBLISH command of Sentinel.
*
* 如果 message 中没有 master name,这条信息就会被无视 */
void sentinelProcessHelloMessage(char *hello, int hello_len) {
/* Format is composed of 8 tokens:
* 0=ip,1=port,2=runid,3=current_epoch,4=master_name,
* 5=master_ip,6=master_port,7=master_config_epoch. */
int numtokens, port, removed, master_port;
uint64_t current_epoch, master_config_epoch;
char **token = sdssplitlen(hello, hello_len, ",", 1, &numtokens);
sentinelRedisInstance *si, *master;
// 如果这 8 个 field 不齐全,直接退出
if (numtokens == 8) {
/* 拿到 master */
master = sentinelGetMasterByName(token[4]);
if (!master) goto cleanup; /* Unknown master, skip the message. */
/* 首先,判断我们是否已经知道这个 sentinel */
port = atoi(token[1]);
master_port = atoi(token[6]);
si = getSentinelRedisInstanceByAddrAndRunID(
master->sentinels,token[0],port,token[2]);
current_epoch = strtoull(token[3],NULL,10);
master_config_epoch = strtoull(token[7],NULL,10);
if (!si) {
/* 如果是一个新来的 sentinel(新的ip:port),就把他加入 master->sentinels 中 */
······
/* Add the new sentinel. */
si = createSentinelRedisInstance(token[2],SRI_SENTINEL,
token[0],port,master->quorum,master);
······
}
/* 更新 failover 序列号:current_epoch */
if (current_epoch > sentinel.current_epoch) {
sentinel.current_epoch = current_epoch;
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+new-epoch",master,"%llu",
(unsigned long long) sentinel.current_epoch);
}
/* 如果 master 地址变了,就去连接新的 master */
if (si && master->config_epoch < master_config_epoch) {
master->config_epoch = master_config_epoch;
if (master_port != master->addr->port ||
!sentinelAddrEqualsHostname(master->addr, token[5]))
{
sentinelAddr *old_addr;
sentinelEvent(LL_WARNING,"+config-update-from",si,"%@");
sentinelEvent(LL_WARNING,"+switch-master",
master,"%s %s %d %s %d",
master->name,
announceSentinelAddr(master->addr), master->addr->port,
token[5], master_port);
old_addr = dupSentinelAddr(master->addr);
sentinelResetMasterAndChangeAddress(master, token[5], master_port);
sentinelCallClientReconfScript(master,
SENTINEL_OBSERVER,"start",
old_addr,master->addr);
releaseSentinelAddr(old_addr);
}
}
/* Update the state of the Sentinel. */
if (si) si->last_hello_time = mstime();
}
}3. 判断实例是否主观下线
所有的 sentinel redis instance 都会执行这个方法
void sentinelCheckSubjectivelyDown(sentinelRedisInstance *ri) {
mstime_t elapsed = 0;
// act_ping_time:上一次 pending ping(没有得到回复)的时间
if (ri->link->act_ping_time)
elapsed = mstime() - ri->link->act_ping_time;
// disconnected:大于零表示需要重连 cc or pc
// cc:redisAsyncContext *cc; 上面粗体字提到的命令连接(commands)
// pc: redisAsyncContext *pc; 上面粗体字提到的发布订阅连接(Pub/Sub)
else if (ri->link->disconnected)
elapsed = mstime() - ri->link->last_avail_time;
/* 检测到了异常状态,看看是否要重新连接
*
* 1) 检查命令连接(commands) */
if (ri->link->cc &&
(mstime() - ri->link->cc_conn_time) >
sentinel_min_link_reconnect_period &&
ri->link->act_ping_time != 0 && /* There is a pending ping... */
/* The pending ping is delayed, and we did not receive
* error replies as well. */
(mstime() - ri->link->act_ping_time) > (ri->down_after_period/2) &&
(mstime() - ri->link->last_pong_time) > (ri->down_after_period/2))
{
// 这里只释放连接的 context: *cc,*pc
instanceLinkCloseConnection(ri->link,ri->link->cc);
}
/* 2) 检查发布订阅(Pub/Sub)连接 */
if (ri->link->pc &&
(mstime() - ri->link->pc_conn_time) >
sentinel_min_link_reconnect_period &&
(mstime() - ri->link->pc_last_activity) > (sentinel_publish_period*3))
{
// 这里只释放连接的 context: *cc,*pc
instanceLinkCloseConnection(ri->link,ri->link->pc);
}
/* 更新 SDOWN flag. 下面几种情况说明 instance 处于 SDOWN 状态:
*
* 1) It is not replying.
* 2) 我们认为它是 master,但是他自己上报自己是个 slave,并且持续了一段时间
*/
if (elapsed > ri->down_after_period ||
(ri->flags & SRI_MASTER &&
ri->role_reported == SRI_SLAVE &&
mstime() - ri->role_reported_time >
(ri->down_after_period+sentinel_info_period*2)) ||
(ri->flags & SRI_MASTER_REBOOT &&
mstime()-ri->master_reboot_since_time > ri->master_reboot_down_after_period))
{
/* 主观下线 */
if ((ri->flags & SRI_S_DOWN) == 0) {
// +sdown -- The specified instance is now in Subjectively Down state.
sentinelEvent(LL_WARNING,"+sdown",ri,"%@");
ri->s_down_since_time = mstime();
ri->flags |= SRI_S_DOWN;
}
} else {
if (ri->flags & SRI_S_DOWN) {
// 实例已经不再处于主观下线状态了 subjectively up
// -sdown -- The specified instance is no longer in Subjectively Down state.
sentinelEvent(LL_WARNING,"-sdown",ri,"%@");
ri->flags &= ~(SRI_S_DOWN|SRI_SCRIPT_KILL_SENT);
}
}
}4. 判断 master 是否客观下线
由于:
- 在上次 cron 的最后,当前 sentinel 和各个 sentinel交换了与其他节点的连接状态信息:
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS) - 在本次 cron 开始,校验了和各个 sentinel 的连接状态,并将断连的 sentinel 的连接的 context 信息清空(
sentinelReconnectInstance(ri))
所以,在这里直接读取没有被清空 contetx 的 sentinel 的信息就能知道该 sentinel 是否和 master 断开连接;统计所有的 sentinel 就能判断 master 是否已经主观下线。
/* 以配置的 quorum 作为阈值,判断 master 是否客观下线 */
void sentinelCheckObjectivelyDown(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
unsigned int quorum = 0, odown = 0;
// 如果已经判定主观下线,就开始计数
if (master->flags & SRI_S_DOWN) {
quorum = 1; /* 先把自己算上 */
/* 遍历其他 sentinel 计数 */
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
// 其他哨兵认为它已经主观下线
if (ri->flags & SRI_MASTER_DOWN) quorum++;
}
dictReleaseIterator(di);
// 认为 master 主观下线的哨兵数量>配置的阈值,说明实例客观下线
if (quorum >= master->quorum) odown = 1;
}
/* 设置 flag,记录时间 */
if (odown) {
if ((master->flags & SRI_O_DOWN) == 0) {
sentinelEvent(LL_WARNING,"+odown",master,"%@ #quorum %d/%d",
quorum, master->quorum);
master->flags |= SRI_O_DOWN;
master->o_down_since_time = mstime();
}
} else {
if (master->flags & SRI_O_DOWN) {
sentinelEvent(LL_WARNING,"-odown",master,"%@");
master->flags &= ~SRI_O_DOWN;
}
}
}
5. 发起投票,选举 leader
/* 如果我们认为某个实例已经 down 了,就发起投票:
* 给其他 sentinel 发送 SENTINEL IS-MASTER-DOWN-BY-ADDR
* 票数达到 quorum 值的话,发起故障转移(failover),重新选主 */
void sentinelAskMasterStateToOtherSentinels(sentinelRedisInstance *master, int flags) {
dictIterator *di;
dictEntry *de;
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
mstime_t elapsed = mstime() - ri->last_master_down_reply_time;
char port[32];
int retval;
/* If the master state from other sentinel is too old, we clear it. */
if (elapsed > sentinel_ask_period*5) {
ri->flags &= ~SRI_MASTER_DOWN;
sdsfree(ri->leader);
// 这里将会用来存储执行 failover 的 sentinel 的 runid
ri->leader = NULL;
}
// 如果只是主观下线,而不是客观下线,不切换 master
if ((master->flags & SRI_S_DOWN) == 0) continue;
// 如果某个 sentinel 连接异常,跳过不作处理
if (ri->link->disconnected) continue;
······
/* Ask: 注意,这里是异步地发送命令:
* SENTINEL is-master-down-by-addr
* 回调函数是 sentinelReceiveIsMasterDownReply
*/
ll2string(port,sizeof(port),master->addr->port);
retval = redisAsyncCommand(ri->link->cc,
sentinelReceiveIsMasterDownReply, ri,
"%s is-master-down-by-addr %s %s %llu %s",
sentinelInstanceMapCommand(ri,"SENTINEL"),
announceSentinelAddr(master->addr), port,
sentinel.current_epoch,
// 自己在先前的程序中,判断有 failover 即将运行或者正在运行,投票给自己,没有的话,不投票
(master->failover_state > SENTINEL_FAILOVER_STATE_NONE) ?
sentinel.myid : "*");
if (retval == C_OK) ri->link->pending_commands++;
}
dictReleaseIterator(di);
}1. 其他 sentinel 收到请求
void sentinelCommand(client *c) {
······
if (!strcasecmp(c->argv[1]->ptr,"is-master-down-by-addr")) {
/* SENTINEL IS-MASTER-DOWN-BY-ADDR <ip> <port> <current-epoch> <runid>
* current-epoch:每个 sentinel 每个 epoch 只能投一次票 */
sentinelRedisInstance *ri;
long long req_epoch;
uint64_t leader_epoch = 0;
char *leader = NULL;
long port;
int isdown = 0;
······
ri = getSentinelRedisInstanceByAddrAndRunID(sentinel.masters,
c->argv[2]->ptr,port,NULL);
/* It exists? Is actually a master? Is subjectively down? It's down.
* Note: 如果 哨兵处于 tilt 模式下,永远答复:没有主观下线 */
if (!sentinel.tilt && ri && (ri->flags & SRI_S_DOWN) &&
(ri->flags & SRI_MASTER))
isdown = 1;
/* 投票 */
if (ri && ri->flags & SRI_MASTER && strcasecmp(c->argv[5]->ptr,"*")) {
leader = sentinelVoteLeader(ri,(uint64_t)req_epoch,
c->argv[5]->ptr,
&leader_epoch);
}
······
// 是否下线
addReply(c, isdown ? shared.cone : shared.czero);
// 当前哨兵是否选出了 leader
addReplyBulkCString(c, leader ? leader : "*");
// 本次投票的序列号
addReplyLongLong(c, (long long)leader_epoch);
if (leader) sdsfree(leader);
}
······
}2. 当前 sentinel 收到答复
就是上面异步发送SENTINEL is-master-down-by-addr的时候注册的回调函数 sentinelReceiveIsMasterDownReply
void sentinelReceiveIsMasterDownReply(redisAsyncContext *c, void *reply, void *privdata) {
sentinelRedisInstance *ri = privdata;
······
if (r->type == REDIS_REPLY_ARRAY && r->elements == 3 &&
r->element[0]->type == REDIS_REPLY_INTEGER &&
r->element[1]->type == REDIS_REPLY_STRING &&
r->element[2]->type == REDIS_REPLY_INTEGER)
{
······
if (strcmp(r->element[1]->str,"*")) {
/* If the runid in the reply is not "*" the Sentinel actually
* replied with a vote. */
sdsfree(ri->leader);
if ((long long)ri->leader_epoch != r->element[2]->integer)
serverLog(LL_WARNING,
"%s voted for %s %llu", ri->name,
r->element[1]->str,
(unsigned long long) r->element[2]->integer);
// 表示这个 sentinel 投票,leader 中存储的就是被投票对象的 runid
// 最后唱票的时候,就是统计这里的数据
ri->leader = sdsnew(r->element[1]->str);
ri->leader_epoch = r->element[2]->integer;
}
}
}6. failover
故障转移的流程比较清晰,针对下面的几个状态,依次执行不同的任务:

void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
serverAssert(ri->flags & SRI_MASTER);
if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return;
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
// 选举 leader
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE:
// 选出新的 master
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE:
// 让新选出的 slave 变成 master(“slaveof no one”命令)
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
// 等待 slave 升主完成
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
// 让其他 slave 连接新的 master(“slaveof newip newport”命令)
sentinelFailoverReconfNextSlave(ri);
break;
}
}a. sentinel 选举 leader(准备切换 master)
void sentinelFailoverWaitStart(sentinelRedisInstance *ri) {
char *leader;
int isleader;
// 遍历所有 sentinel,统计是否成功选出了主节点。原则是:
// 1. 2N+1
// 2. quorum
leader = sentinelGetLeader(ri, ri->failover_epoch);
isleader = leader && strcasecmp(leader,sentinel.myid) == 0;
sdsfree(leader);
/* (上面根本没有选出 leader || 如果自身不是 master)
* && 不是强制切换 master,就可以直接退出了 */
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
mstime_t election_timeout = sentinel_election_timeout;
if (election_timeout > ri->failover_timeout)
election_timeout = ri->failover_timeout;
/* Abort the failover if I'm not the leader after some time. */
if (mstime() - ri->failover_start_time > election_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-not-elected",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
······
// 更新状态,表示准备从 slaves 中选新的 master 了
// 下次 cron 的时候,会根据 failover_state 走到选 slave 的流程
ri->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_WARNING,"+failover-state-select-slave",ri,"%@");
}这里我们再看一下当前哨兵唱票获取 leader 的代码:
/* Scan all the Sentinels attached to this master to check if there
* is a leader for the specified epoch.
*
* To be a leader for a given epoch, we should have the majority of
* the Sentinels we know (ever seen since the last SENTINEL RESET) that
* reported the same instance as leader for the same epoch. */
char *sentinelGetLeader(sentinelRedisInstance *master, uint64_t epoch) {
dict *counters;
dictIterator *di;
dictEntry *de;
unsigned int voters = 0, voters_quorum;
char *myvote;
char *winner = NULL;
uint64_t leader_epoch;
uint64_t max_votes = 0;
serverAssert(master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS));
counters = dictCreate(&leaderVotesDictType);
// 总票数 = 所有 sentinel 节点的数量
voters = dictSize(master->sentinels)+1; /* All the other sentinels and me.*/
// 统计其他 sentinels 的投票
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->leader != NULL && ri->leader_epoch == sentinel.current_epoch)
sentinelLeaderIncr(counters,ri->leader);
}
dictReleaseIterator(di);
/* 检查是否有 sentinel 节点胜出(winner),条件是:
* 1) 50% + 1
* 2) 票数 >= master->quorum votes. */
di = dictGetIterator(counters);
while((de = dictNext(di)) != NULL) {
uint64_t votes = dictGetUnsignedIntegerVal(de);
if (votes > max_votes) {
max_votes = votes;
// 这里拿到的是 sentinel 的 runid
winner = dictGetKey(de);
}
}
dictReleaseIterator(di);
/* 轮到自己投票了,两种方案:
* 1. 跟着大多数 sentinel 投
* 2. 当前没有任何 sentinel 投票,就投自己 */
if (winner)
myvote = sentinelVoteLeader(master,epoch,winner,&leader_epoch);
else
myvote = sentinelVoteLeader(master,epoch,sentinel.myid,&leader_epoch);
// 给统计结果加上自己的一票
if (myvote && leader_epoch == epoch) {
uint64_t votes = sentinelLeaderIncr(counters,myvote);
if (votes > max_votes) {
max_votes = votes;
winner = myvote;
}
}
voters_quorum = voters/2+1;
if (winner && (max_votes < voters_quorum || max_votes < master->quorum))
winner = NULL;
winner = winner ? sdsnew(winner) : NULL;
sdsfree(myvote);
dictRelease(counters);
return winner;
}具体投票的代码是:
// 如果投票的序列号没有变,则返回之前的投票结果
// 如果投票的序列号发生改变,则投票给方法入参所代表的的节点:req_runid
char *sentinelVoteLeader(sentinelRedisInstance *master, uint64_t req_epoch, char *req_runid, uint64_t *leader_epoch) {
// 如果对方的投票序列号更大,则刷新本地序列号
if (req_epoch > sentinel.current_epoch) {
sentinel.current_epoch = req_epoch;
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+new-epoch",master,"%llu",
(unsigned long long) sentinel.current_epoch);
}
// 如果投票的序列号发生改变,则投票给方法入参所代表的的节点:req_runid
if (master->leader_epoch < req_epoch && sentinel.current_epoch <= req_epoch)
{
sdsfree(master->leader);
master->leader = sdsnew(req_runid);
master->leader_epoch = sentinel.current_epoch;
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+vote-for-leader",master,"%s %llu",
master->leader, (unsigned long long) master->leader_epoch);
/* 如果投票给了别人,就刷新一下本地的 failover_start_time
* 这样做的目的是,为了强制推迟本机的 failover 流程
*(此时已经有哨兵在主导 failover 了) */
if (strcasecmp(master->leader,sentinel.myid))
master->failover_start_time = mstime()+rand()%SENTINEL_MAX_DESYNC;
}
*leader_epoch = master->leader_epoch;
return master->leader ? sdsnew(master->leader) : NULL;
}b. leader 选择 slave 升主
void sentinelFailoverSelectSlave(sentinelRedisInstance *ri) {
sentinelRedisInstance *slave = sentinelSelectSlave(ri);
if (slave == NULL) {
// 如果所有的 slave 都不太行,就终止本次 failover
sentinelEvent(LL_WARNING,"-failover-abort-no-good-slave",ri,"%@");
sentinelAbortFailover(ri);
} else {
sentinelEvent(LL_WARNING,"+selected-slave",slave,"%@");
slave->flags |= SRI_PROMOTED;
ri->promoted_slave = slave;
// 选出了一个 slave 准备升主
ri->failover_state = SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_NOTICE,"+failover-state-send-slaveof-noone",
slave, "%@");
}
}再进一步看看在 slave 中选新的 master 的逻辑:
sentinelRedisInstance *sentinelSelectSlave(sentinelRedisInstance *master) {
sentinelRedisInstance **instance =
zmalloc(sizeof(instance[0])*dictSize(master->slaves));
sentinelRedisInstance *selected = NULL;
int instances = 0;
dictIterator *di;
dictEntry *de;
mstime_t max_master_down_time = 0;
if (master->flags & SRI_S_DOWN)
max_master_down_time += mstime() - master->s_down_since_time;
max_master_down_time += master->down_after_period * 10;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
mstime_t info_validity_time;
// 筛选掉状态不好的 slave,比如 disconnected 的、ODOWN/SDOWN 的、
// 和 master 断连过久的
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
······
instance[instances++] = slave;
}
if (instances) {
qsort(instance,instances,sizeof(sentinelRedisInstance*),
// 注意这个筛选器,核心逻辑在这里
compareSlavesForPromotion);
selected = instance[0];
}
zfree(instance);
return selected;
}compareSlavesForPromotion:
/* Helper for sentinelSelectSlave(). This is used by qsort() in order to
* sort suitable slaves in a "better first" order, to take the first of
* the list. */
int compareSlavesForPromotion(const void *a, const void *b) {
sentinelRedisInstance **sa = (sentinelRedisInstance **)a,
**sb = (sentinelRedisInstance **)b;
char *sa_runid, *sb_runid;
// 配置文件里的优先级参数
if ((*sa)->slave_priority != (*sb)->slave_priority)
return (*sa)->slave_priority - (*sb)->slave_priority;
/* 默认情况下,优先级都一样,这里选择数据更完整的 salve */
if ((*sa)->slave_repl_offset > (*sb)->slave_repl_offset) {
return -1; /* a < b */
} else if ((*sa)->slave_repl_offset < (*sb)->slave_repl_offset) {
return 1; /* a > b */
}
/* 数据都很完整,就比较 runid,runid 更小,说明存活的更久
* 说明可靠性更高 */
sa_runid = (*sa)->runid;
sb_runid = (*sb)->runid;
if (sa_runid == NULL && sb_runid == NULL) return 0;
else if (sa_runid == NULL) return 1; /* a > b */
else if (sb_runid == NULL) return -1; /* a < b */
return strcasecmp(sa_runid, sb_runid);
}c. 通知选出的 slave:你可以当 master 了
发送slaveof no one命令给 slave,表示不需要再做 slave 了
void sentinelFailoverSendSlaveOfNoOne(sentinelRedisInstance *ri) {
int retval;
/* 如果选出的 slave 连接异常了,就不断在 cron 循环里重试,
* 如果重试多次直到超时了,就放弃此次故障转移,清理掉 failover_state
* 但是此时 master 还是客观下线的,所以会重新走 sentinel 选举,挑选
* slave 的过程 。*/
if (ri->promoted_slave->link->disconnected) {
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
/* 发送 SLAVEOF NO ONE 把 slave 转换为 master.
* 这里其实并不关心对方的回复,因为我们在后续 cron 中会通过 info 命令
* 拿到每个节点的信息 */
retval = sentinelSendSlaveOf(ri->promoted_slave,NULL);
if (retval != C_OK) return;
sentinelEvent(LL_NOTICE, "+failover-state-wait-promotion",
ri->promoted_slave,"%@");
//
ri->failover_state = SENTINEL_FAILOVER_STATE_WAIT_PROMOTION;
ri->failover_state_change_time = mstime();
}d. 等待 slave 升主完成
这一步只是单纯地等待,上文提到过 cron 中会定时发送 info 命令给各个节点,拿到每个节点的身份信息;除非等待超时,这时候就放弃此次故障转移。
/* We actually wait for promotion indirectly checking with INFO when the
* slave turns into a master. */
void sentinelFailoverWaitPromotion(sentinelRedisInstance *ri) {
/* Just handle the timeout. Switching to the next state is handled
* by the function parsing the INFO command of the promoted slave. */
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
}e. 通知 slaves 迎接新王登基
给其他 slaves 发送SLAVE OF命令,连接新的 master
/* Send SLAVE OF <new master address> to all the remaining slaves that
* still don't appear to have the configuration updated. */
// 这个方法,通过 parallel_syncs 参数,限制了同时处理的 slave 的数量
// 它的默认值是 1,表示同一时间,只能有一个 slave 在和新 master 同步数据;
// 这样做的主要原因是:防止在所有的 slave 同时不可用的情况下,同时和 master 同步数据。
void sentinelFailoverReconfNextSlave(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
int in_progress = 0;
// 统计正在和新 master 同步数据的 slave 的数量
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (slave->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG))
in_progress++;
}
dictReleaseIterator(di);
di = dictGetIterator(master->slaves);
while(in_progress < master->parallel_syncs &&
(de = dictNext(di)) != NULL)
{
sentinelRedisInstance *slave = dictGetVal(de);
int retval;
/* 跳过刚刚升主的 slave,和已经重新配置了的 slave */
if (slave->flags & (SRI_PROMOTED|SRI_RECONF_DONE)) continue;
/* If too much time elapsed without the slave moving forward to
* the next state, consider it reconfigured even if it is not.
* Sentinels will detect the slave as misconfigured and fix its
* configuration later. */
if ((slave->flags & SRI_RECONF_SENT) &&
(mstime() - slave->slave_reconf_sent_time) >
sentinel_slave_reconf_timeout)
{
sentinelEvent(LL_NOTICE,"-slave-reconf-sent-timeout",slave,"%@");
slave->flags &= ~SRI_RECONF_SENT;
slave->flags |= SRI_RECONF_DONE;
}
/* 遇到已经发送过 slave of 命令的、正在同步数据的、断开连接的 slave,
* 直接跳过 */
if (slave->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG)) continue;
if (slave->link->disconnected) continue;
/* 发送 SLAVEOF <new master> 命令 */
retval = sentinelSendSlaveOf(slave,master->promoted_slave->addr);
if (retval == C_OK) {
// 标记状态为已发送
slave->flags |= SRI_RECONF_SENT;
slave->slave_reconf_sent_time = mstime();
sentinelEvent(LL_NOTICE,"+slave-reconf-sent",slave,"%@");
in_progress++;
}
}
dictReleaseIterator(di);
/* 如果故障转移的整体操作时间超过了 failover_timeout,
* 尝试给仍未同步成功的 slave 再发一次 slave of 命令
* */
sentinelFailoverDetectEnd(master);
}7. 更新其他 sentinel 的信息
定期(sentinel_ask_period)发送 is-master-down-by-addr 给其他 sentinel,获取对方的信息,为下一轮的客观下线判断提供依据。
这里调用的方法和 选举 leader 是同一个,只不过参数不同罢了。
如果集群状态一切正常,每个 cron 都会在这一步刷新其他 sentinel 的信息。
8. 调整 SentinelRedisInstance 字典树
每遍历完一个 master 之后,都会有下面的判断:
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);你可以全局搜索来查看它的具体位置。这段代码的作用是,当 failover 完成的时候,需要调整这个 master 所在的字典树(集群中已经产生了新的 master),在根节点中录入新 master 的地址,然后把所有的 slaves 添加到 master->slaves 中,具体的实现如下:
int sentinelResetMasterAndChangeAddress(sentinelRedisInstance *master, char *hostname, int port) {
sentinelAddr *oldaddr, *newaddr;
sentinelAddr **slaves = NULL;
int numslaves = 0, j;
dictIterator *di;
dictEntry *de;
newaddr = createSentinelAddr(hostname,port,0);
if (newaddr == NULL) return C_ERR;
slaves = zmalloc(sizeof(sentinelAddr*)*(dictSize(master->slaves) + 1));
/* 把旧 master 的所有 slave 都找出来 */
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (sentinelAddrIsEqual(slave->addr,newaddr)) continue;
slaves[numslaves++] = dupSentinelAddr(slave->addr);
}
dictReleaseIterator(di);
/* 把旧的 master 也找出来,后续要把它添回到新 master 的 slave 树中 */
if (!sentinelAddrIsEqual(newaddr,master->addr)) {
slaves[numslaves++] = dupSentinelAddr(master->addr);
}
/* 这里不是生成一个新的 master 节点,而是
* 替换掉旧 master 节点中的数据 */
sentinelResetMaster(master,SENTINEL_RESET_NO_SENTINELS);
oldaddr = master->addr;
master->addr = newaddr;
master->o_down_since_time = 0;
master->s_down_since_time = 0;
/* 把 slave 节点都添回到新 master 中 */
for (j = 0; j < numslaves; j++) {
sentinelRedisInstance *slave;
slave = createSentinelRedisInstance(NULL,SRI_SLAVE,slaves[j]->hostname,
slaves[j]->port, master->quorum, master);
releaseSentinelAddr(slaves[j]);
if (slave) sentinelEvent(LL_NOTICE,"+slave",slave,"%@");
}
zfree(slaves);
······
sentinelFlushConfig();
return C_OK;
}至此,故障转移的流程就结束了。
3. 执行挂起的脚本任务
这一步的工作,是执行脚本队列中的脚本。那么,这些脚本是干什么的?他们是什么时候添加到哪里的队列呢?
1. 队列在哪里?
队列就在 redis 哨兵的核心结构 sentinelState 里,你可以全局搜索list *scripts_queue找到它。
2. 什么时候往队列里添加元素?
场景1:
slave 切换成为了 master 之后,会发送通知给负责的 sentinel,sentinel 就会将一个脚本放进队列里,用途就是通知连接旧 master 的客户端(client),该去连接新的 master 了。
具体的实现这里就不读了,可以全局搜索sentinelCallClientReconfScript查看它是在哪里执行的。
场景2:
Sentinel Redis Instance 中,有一个 notification_script 脚本参数,它是 redis 为我们提供的定制化接口,我们可以通过下面的命令设置一个自定义脚本(也可以直接在 sentinel.conf 中配置)
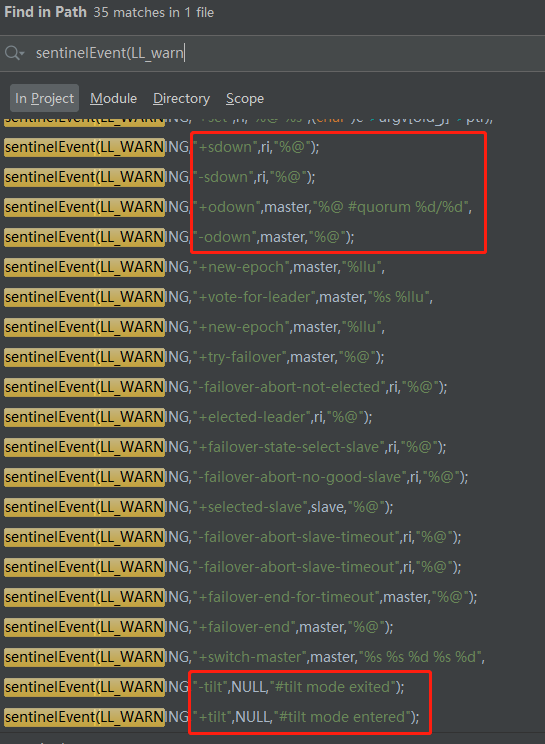
sentinel notification-script mastername /script/send_email.py当哨兵集群在发生 LL_WARNGING 级别的事件的时候,会调用 sentinelEvent() 函数,把这个脚本放进队列里。一个最简单地应用就是:发生 LL_WARNING 级别的事件时,发邮件\发短信通知运维人员。
在 redis 源码中,搜索一下 LL_WARNGING,我们可以发现,tilt、odown、sdown、failover....这些都是集群发生重要事件的场景:
现在,我们再回到主线,看看执行脚本的源码:
/* Run pending scripts if we are not already at max number of running
* scripts. */
void sentinelRunPendingScripts(void) {
listNode *ln;
listIter li;
mstime_t now = mstime();
/* 先进先出队列,以添加进队列的顺序运行任务
* 注意1:这里是 fork 子进程去处理,所以会有
* SENTINEL_SCRIPT_MAX_RUNNING 的数量限制,防止开销过大 */
listRewind(sentinel.scripts_queue,&li);
while (sentinel.running_scripts < SENTINEL_SCRIPT_MAX_RUNNING &&
(ln = listNext(&li)) != NULL)
{
sentinelScriptJob *sj = ln->value;
pid_t pid;
/* 跳过运行中的任务. */
if (sj->flags & SENTINEL_SCRIPT_RUNNING) continue;
······
sj->flags |= SENTINEL_SCRIPT_RUNNING;
sj->start_time = mstime();
sj->retry_num++;
pid = fork();
if (pid == -1) {
/* fork 失败,记录一个特殊的错误码 99, 用以和其他类型的错误区分 */
sentinelEvent(LL_WARNING,"-script-error",NULL,
"%s %d %d", sj->argv[0], 99, 0);
sj->flags &= ~SENTINEL_SCRIPT_RUNNING;
sj->pid = 0;
} else if (pid == 0) {
/* Child */
tlsCleanup();
execve(sj->argv[0],sj->argv,environ);
/* If we are here an error occurred. */
_exit(2); /* Don't retry execution. */
} else {
sentinel.running_scripts++;
sj->pid = pid;
sentinelEvent(LL_DEBUG,"+script-child",NULL,"%ld",(long)pid);
}
}
}4. 收集脚本任务执行情况
/* 只有运行成功的任务,才会被从队列中移除;执行失败的任务(脚本没能返回1),
* 会被塞回队列中重新运行,直到运行成功或者达到 max retry time 为止. */
void sentinelCollectTerminatedScripts(void) {
int statloc;
pid_t pid;
while ((pid = waitpid(-1, &statloc, WNOHANG)) > 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
listNode *ln;
sentinelScriptJob *sj;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
sentinelEvent(LL_DEBUG,"-script-child",NULL,"%ld %d %d",
(long)pid, exitcode, bysignal);
ln = sentinelGetScriptListNodeByPid(pid);
if (ln == NULL) {
serverLog(LL_WARNING,"waitpid() returned a pid (%ld) we can't find in our scripts execution queue!", (long)pid);
continue;
}
sj = ln->value;
/* 如果没有正常退出,则塞回队列 */
if ((bysignal || exitcode == 1) &&
sj->retry_num != SENTINEL_SCRIPT_MAX_RETRY)
{
sj->flags &= ~SENTINEL_SCRIPT_RUNNING;
sj->pid = 0;
sj->start_time = mstime() +
sentinelScriptRetryDelay(sj->retry_num);
} else {
······
// 从队列中移除
listDelNode(sentinel.scripts_queue,ln);
sentinelReleaseScriptJob(sj);
}
sentinel.running_scripts--;
}
}5. kill 掉超时的脚本进程
void sentinelKillTimedoutScripts(void) {
listNode *ln;
listIter li;
mstime_t now = mstime();
listRewind(sentinel.scripts_queue,&li);
while ((ln = listNext(&li)) != NULL) {
sentinelScriptJob *sj = ln->value;
if (sj->flags & SENTINEL_SCRIPT_RUNNING &&
(now - sj->start_time) > sentinel_script_max_runtime)
{
sentinelEvent(LL_WARNING,"-script-timeout",NULL,"%s %ld",
sj->argv[0], (long)sj->pid);
kill(sj->pid,SIGKILL);
}
}
}
三、后记
本来会以为哨兵、哨兵集群会很复杂,没想到 redis 的实现居然这么简洁、易懂,一个定时 timer 居然就能解决大多数的问题,三天基本上就把这块的代码读的差不多了。
尤其是看到哨兵部分,大部分代码都是这个 antirez 的人提交的,更是五体投地