上一节学习了一下 LogSegment 的相关知识,今天来看看 kafka 中 Log 对象的具体构造。不过在此之前,需要先了解一下面几个知识:
一、高水位 High Watermark
1. 高水位的含义
在 kafka 中,HW (High watermark 高水位)的作用主要有两个:
- 定义消息可见性,它被用来标识分区下哪些消息是可以被消费者消费的
- 帮助完成副本同步
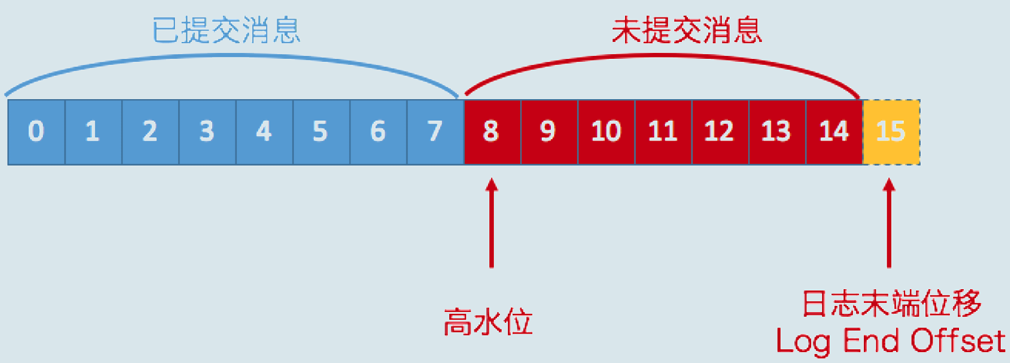
在分区高水位以下的消息被认为是已提交消息,反之就是未提交消息。而消费者只能消费已提交消息,或者说消费者只能消费高水位以下的消息,即上图中 offset 小于 8 的消息,而当前高水位是 8,就表示 8 和 8+ 的数据是不能被消费的。
需要注意的是,这是在不考虑事务的情况下的简单模型,因为事务会影响消费者所能看见的消息范围,而日志对事务型消费者的可见性,由 LSO(Log Stable Offset)的值来决定,这个不是我们今天讨论的主题,先略过不谈。
在上面的图中,还有一个 LEO(Log End Offset),它表示分区中下一条待写入消息的位移值。所以我们可以得到结论:介于高水位和 LEO 之间的消息属于未提交消息;这也就意味着:对于分区对应的 log 对象,它的高水位一定 ≤ LEO 值。
2. 高水位更新机制
Kafka 中,分区 partition 的所有的副本中(不论是 leader 还是 follower)都保存着各自的 HW 和 LEO 值。分区的高水位值就是 Leader 副本的高水位值,同时,leader 副本所在的 broker 上还保存了其他 follower 的 LEO。
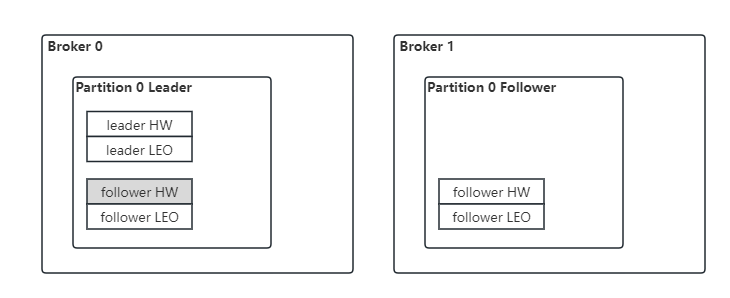
以下是他们的更新时机:
Broker 1 Follower LEO:当 Follower 从 Leader 拉取消息,写入本地磁盘之后,会更新其 LEO 值
Broker 1 Follower HW: 当 Follower 更新完 LEO 之后,会比较其 LEO 和 Leader 发过来的 leader HW,取较小的一个作为自己的 HW
Broker 0 Leader LEO:当 Leader 接收生产者的消息,写入本地磁盘之后,会更新其 LEO
Broker 0 Follower LEO:当 Follower 从 Leader 拉取消息时,会告诉 Leader 从哪个 offset 开始拉取,Leader 会用这个 offset 更新远程副本的 LEO
Broker 0 Leader HW:主要有两个更新时机,一个是 Leader 更新完 LEO 之后;另一个是更新完 Follower 的 LEO 之后。具体算法是:取 Leader 和所有与 Leader 保持同步的远程副本 LEO 的最小值
Broker 0 Follower HW: 不更新(上图中标注为灰色的部分)
下面,我们分别从 Leader 副本和 Follower 副本两个维度,来捋一捋高水位和 LEO 的更新机制。
对于 Leader 副本
处理生产者的请求逻辑如下:
- 写入消息到本地磁盘
- 更新 Leader 副本 LEO
- 更新分区高水位值
- 获取 Leader 副本所在 Broker 端保存的所有远程副本 LEO 值(LEO-1,LEO-2...LEO-n)
- 获取 Leader 副本高水位 currentHW
- 更新 currentHW = max(currentHW,min(LEO-1,LEO-2...LEO-n))
处理 Follower 副本拉取消息的逻辑如下:
- 使用 Follower 副本发送的请求中的位移值,更新远程副本的 LEO 值
- 更新分区高水位值(具体步骤与上文处理生产者请求的步骤相同)
- 获取 Leader 副本所在 Broker 端保存的所有远程副本 LEO 值(LEO-1,LEO-2...LEO-n)
- 获取 Leader 副本高水位 currentHW
- 更新 currentHW = max(currentHW,min(LEO-1,LEO-2...LEO-n))
这里其实存在着一个问题, Follower 拉取消息的时候,请求中的位移值(fetchOffset)是表示想要从 fetchOffset 开始拉取消息,所以,只有等再下一次拉取消息的时候,才能得到这一次拉取完消息之后的 LEO,他们之间有一个滞后性。这个滞后性,其实是很多“数据丢失”或“数据不一致”问题的根源。这个问题是通过一个叫 Leader Epoch 的东西解决的,我们会在下一节详细介绍它。
对于 Follower 副本
从 Leader 拉取消息的逻辑如下:
- 写入消息到本地磁盘
- 更新 LEO
- 更新高水位值
- 获取 Leader 发送的高水位值:currentHW
- 获取步骤 2 中更新过的 LEO 值:currentLEO
- 更新高水位为 min(currentHW, currentLEO)
二、Leader Epoch
从上文中,我们知道,Follower 副本的高水位更新需要一轮额外的拉取请求才能实现。而如果把上面那个例子扩展到多个 Follower 副本,情况可能更糟,也许需要多轮拉取请求。也就是说,Leader 副本高水位更新和 Follower 副本高水位更新在时间上是存在错配的。这种错配是很多“数据丢失”或“数据不一致”问题的根源。基于此,社区在 0.11 版本正式引入了 Leader Epoch 概念,来解决因高水位更新错配导致的各种不一致问题。
所谓 Leader Epoch,我们大致可以认为是 Leader 版本。它由两部分数据组成。
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。
- 起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移
举个例子来说明一下 Leader Epoch。假设现在有两个 Leader Epoch<0,0> 和 <1,120>,那么,第一个 Leader Epoch 表示版本号是 0,这个版本的 Leader 从位移 0 开始保存消息,一共保存了 120 条消息。之后,Leader 发生了变更,版本号增加到 1,新版本的起始位移是 120。
Kafka Broker 会在内存中为每个分区都缓存 Leader Epoch 数据,同时它还会定期地将这些信息持久化到一个 checkpoint 文件中。当 Leader 副本写入消息到磁盘时,Broker 会尝试更新这部分缓存。这样,每次有 Leader 变更时,新的 Leader 副本会查询这部分缓存,取出对应的 Leader Epoch 的起始位移,以避免数据丢失和不一致的情况。
从 LeaderEpochCheckpointFile 对象中的 Formatter 对象的源码中,我们可以看到具体写入和读取的 toLine 和 fromLine 方法:
object Formatter extends CheckpointFileFormatter[EpochEntry] {
// 写到 checkpoint 文件里的时候,就是用这个方法
override def toLine(entry: EpochEntry): String = s"${entry.epoch} ${entry.startOffset}"
// 从文件中读取一行数据,用这个方法构建 EpochEntry
override def fromLine(line: String): Option[EpochEntry] = {
WhiteSpacesPattern.split(line) match {
case Array(epoch, offset) =>
Some(EpochEntry(epoch.toInt, offset.toLong))
case _ => None
}
}
}三、Log 类源码
先来看看 Log 方法的签名:
/**
* An append-only log for storing messages.
*
* The log is a sequence of LogSegments, each with a base offset denoting the first message in the segment.
*
* log 由多个 LogSegments 构成;每个 segment 都有一个 base offset 参数,代表 segment 中第一条消息
*
* New log segments are created according to a configurable policy that controls the size in bytes or time interval
* for a given segment.
*
* 系统会根据配置文件中预设的策略(比如当前 segment 大小、固定的时间间隔等),创建新的 segment
*
* @param _dir The directory in which log segments are created.
* @param config The log configuration settings
* @param logStartOffset The earliest offset allowed to be exposed to kafka client.
* The logStartOffset can be updated by :
* - user's DeleteRecordsRequest
* - broker's log retention
* - broker's log truncation
* The logStartOffset is used to decide the following:
* - Log deletion. LogSegment whose nextOffset <= log's logStartOffset can be deleted.
* It may trigger log rolling if the active segment is deleted.
* - Earliest offset of the log in response to ListOffsetRequest. To avoid OffsetOutOfRange exception after user seeks to earliest offset,
* we make sure that logStartOffset <= log's highWatermark
* Other activities such as log cleaning are not affected by logStartOffset.
*
* 日志中第一条日志的 offset,这是一个 volatile 类型的变量,存在被多个线程更新的可能,可能得来源有:
* 1. 用户删除消息
* 2. broker 日志保留机制(kafka 支持根据时间、日志大小、offset 设置日志保留策略)
* 3. broker 日志截断
*
* logStartOffset 的作用是:
* - 删除日志。nextOffset <= Log.logStartOffset 的 segment 都可以删掉
* - 作为 ListOffsetRequest 请求中的 Earliest offset 值返回。为了避免用户在向前追溯日志的时候触发 OffsetOutOfRange exception,
* kafka 会确保 logStartOffset <= highWatermark
*
*
* @param recoveryPoint The offset at which to begin recovery--i.e. the first offset which has not been flushed to disk
* @param scheduler The thread pool scheduler used for background actions
* @param brokerTopicStats Container for Broker Topic Yammer Metrics
* @param time The time instance used for checking the clock
* @param maxProducerIdExpirationMs The maximum amount of time to wait before a producer id is considered expired
* @param producerIdExpirationCheckIntervalMs How often to check for producer ids which need to be expired
*/
@threadsafe
class Log(@volatile private var _dir: File,
@volatile var config: LogConfig,
@volatile var logStartOffset: Long,
@volatile var recoveryPoint: Long,
scheduler: Scheduler,
brokerTopicStats: BrokerTopicStats,
val time: Time,
val maxProducerIdExpirationMs: Int,
val producerIdExpirationCheckIntervalMs: Int,
val topicPartition: TopicPartition, // 对应的分区
val producerStateManager: ProducerStateManager,
logDirFailureChannel: LogDirFailureChannel) extends Logging with KafkaMetricsGroup {
/* A lock that guards all modifications to the log */
/* 所有的 modify 操作都用这个 lock.synchronized 加锁 */
private val lock = new Object
// 封装着下一条待插入消息的位移信息,包括:
// 1. 它的 offset
// 2. 所处的 segment 的 baseOffset
// 3. 所处的 segment 的日志文件的物理位置
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
/* Keep track of the current high watermark in order to ensure that segments containing offsets at or above it are
* not eligible for deletion. This means that the active segment is only eligible for deletion if the high watermark
* equals the log end offset (which may never happen for a partition under consistent load). This is needed to
* prevent the log start offset (which is exposed in fetch responses) from getting ahead of the high watermark.
*/
// 持有 current HW 信息,kafka 会确保 offset ≥ HW 的 segment 的数据不被删除
//(即确保不会删除包含未提交消息的 segment)
// 这意味着只有当一个 active segment 的 HW 等于 LEO 的时候,才允许删除数据
//(通常在一个 active segment 中,持续有数据写入,HW 总是在追 LEO,永远也达不成删除的条件)
// 这个机制是必要的,可以防止 log start offset 超过 HW,从而使消费者跳过一部分数据
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)
/* the actual segments of the log */
// Log 中所有的 segment 对象,都放在这个 concurrent map 中
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
// 保存着一组 leaderEpoch 对象,即:谁从哪个 offset 开始,变成 leader 的
@volatile var leaderEpochCache: Option[LeaderEpochFileCache] = None
}
Log 类的初始化
了解了 Log 中这几个核心属性之后,再来看一下 Log 类的初始化逻辑:
locally {
// create the log directory if it doesnt exist
// 创建目录
Files.createDirectories(dir.toPath)
// 初始化上面的 leaderEpochCache 变量,包括:
// 1. 从文件(leader-epoch-checkpoint)中读出 EpochEntry(epoch, startOffset),
// 保存成一个 treeMap,Map 的 key 是 epoch,value 是 EpochEntry
// 2. topic\partition 信息
initializeLeaderEpochCache()
// 从磁盘上加载 segment 文件,生成 LogSegment 对象 ,
// 放入到上面的 segments map(ConcurrentNavigableMap)中,并返回 nextOffset
val nextOffset = loadSegments()
/* Calculate the offset of the next message */
// 构建下一条带插入消息的 offset 元数据
nextOffsetMetadata = LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)
// 丢弃掉 leader epoch 中的 offset 大于等于 nextOffset 的数据,保证数据合法
leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))
/**
* logStartOffset 的来源:log 目录下的 log-start-offset-checkpoint 文件,
* kafka 在启动加载 log 的时候,会将文件里的内容转化为 <partition,Long> 的 map,
* 文件的结构如下:
* -----checkpoint file begin------
* 0 <- OffsetCheckpointFile.currentVersion
* 2 <- following entries size
* tp1 par1 1 <- the format is: TOPIC PARTITION OFFSET
* tp1 par2 2
* -----checkpoint file end----------
*/
// 保证数据合法性,取 log-start-offset-checkpoint 文件和 segment 实际数据中,更大的那一个
updateLogStartOffset(math.max(logStartOffset, segments.firstEntry.getValue.baseOffset))
// The earliest leader epoch may not be flushed during a hard failure. Recover it here.
// 保证数据合法性,清理掉无用的 leaderEpoch entry(即 offset < logStartOffset 的所有 entry),
// 然后更正最早一条,将 entry 的 offset 设置为 logStartOffset
leaderEpochCache.foreach(_.truncateFromStart(logStartOffset))
// Any segment loading or recovery code must not use producerStateManager, so that we can build the full state here
// from scratch.
// 加载 segment 或者 recovery 都不允许使用 producerStateManager。下面会重新构建 Producer State
if (!producerStateManager.isEmpty)
throw new IllegalStateException("Producer state must be empty during log initialization")
// hasCleanShutdownFile: 如果有这个文件,说明 broker 是正常关闭的。
// ProducerStateManager:它维护了一个从生产者 id 到其最近追加条目(如 epoch、sequence number、last offset 等)元数据的 map
// 只要生产者 id 仍包含在此映射中,相应的生产者就可以继续写入数据。
// 除非生产者很久不写日志,或者写入的所有消息都被删除(retention policy=delete),这个 id 就会过期。
// 这个东西暂时不涉及主线功能,这里暂时不深究了.
loadProducerState(logEndOffset, reloadFromCleanShutdown = hasCleanShutdownFile)
}接下来,我们来看一看里面的几个关键步骤
初始化 LeaderEpochCache
private def initializeLeaderEpochCache(): Unit = lock synchronized {
// 声明一个 leaderEpochFile 对象(leader-epoch-checkpoint 文件)
val leaderEpochFile = LeaderEpochCheckpointFile.newFile(dir)
// 从文件中读出 EpochEntry(epoch, startOffset),保存成一个 treeMap,Map 的 key 是 epoch,value 是 EpochEntry
def newLeaderEpochFileCache(): LeaderEpochFileCache = {
// LogDirFailureChannel 是 Kafka 用于管理和处理日志目录的故障。在 broker 执行磁盘 I/O 操作的时候,
// 如果遇到 I/O 异常(如 IOException),会把出现问题的日志目录名称添加到 LogDirFailureChannel 中,
// 标记为离线状态,一旦某个日志目录被标记为离线状态,相关线程就收到通知,去处理这个异常。
// 离线的日志目录会一直保持离线状态 ,直到 Kafka 代理被重启为止
val checkpointFile = new LeaderEpochCheckpointFile(leaderEpochFile, logDirFailureChannel)
new LeaderEpochFileCache(topicPartition, () => logEndOffset, checkpointFile)
}
// 这里的 record version 和 magic 以及 message format version 是同一个东西,表示 kafka 的数据的版本
if (recordVersion.precedes(RecordVersion.V2)) {
// 早期版本,直接删除 leader-epoch-checkpoint 文件
val currentCache = if (leaderEpochFile.exists())
Some(newLeaderEpochFileCache())
else
None
if (currentCache.exists(_.nonEmpty))
warn(s"Deleting non-empty leader epoch cache due to incompatible message format $recordVersion")
Files.deleteIfExists(leaderEpochFile.toPath)
leaderEpochCache = None
} else {
leaderEpochCache = Some(newLeaderEpochFileCache())
}
}Load segments
private def loadSegments(): Long = {
// first do a pass through the files in the log directory and remove any temporary files
// and find any interrupted swap operations
// 清理 .delete 文件: 需要被删除的 log 文件和 index 文件
// 清理 .cleaned 文件: 在log compaction 过程中宕机,文件中的数据状态未知,需要删除掉
// 清理所有的无法使用的 .swap 文件: KAFKA-6264
// 返回可用的 .swap 文件: 即在 log compaction 结束后,替换原文件时宕机而遗留下的文件,只需要再做一次替换操作就可以了
val swapFiles = removeTempFilesAndCollectSwapFiles()
// Now do a second pass and load all the log and index files.
// We might encounter legacy log segments with offset overflow (KAFKA-6264). We need to split such segments. When
// this happens, restart loading segment files from scratch.
// 加载日志文件和索引文件
// 可能会遇到带有偏移量溢出的旧版日志段(KAFKA-6264)。需要将这些日志段拆分出来。当这种情况发生时,从头开始重新加载日志段文件。
retryOnOffsetOverflow {
// In case we encounter a segment with offset overflow, the retry logic will split it after which we need to retry
// loading of segments. In that case, we also need to close all segments that could have been left open in previous
// call to loadSegmentFiles().
// 如果遇到带有偏移量溢出的日志段,会抛出 LogSegmentOffsetOverflowException,重试逻辑将会将其拆分。然后我们需要重试加载这些日志段。
// 在这种情况下,还需要关闭在之前调用 loadSegmentFiles() 时可能已打开的所有日志段。
logSegments.foreach(_.close())
segments.clear()
loadSegmentFiles()
}
// Finally, complete any interrupted swap operations. To be crash-safe,
// log files that are replaced by the swap segment should be renamed to .deleted
// before the swap file is restored as the new segment file.
// 最后,完成被中断的交换操作。
// 为了保证在崩溃情况下的数据安全, 被 swap segment 替换的日志文件应在 swap 文件恢复为新的 segment 文件之前重命名为 .deleted。
completeSwapOperations(swapFiles)
if (!dir.getAbsolutePath.endsWith(Log.DeleteDirSuffix)) {
// 如果日志目录存在,则执行 recoverLog
val nextOffset = retryOnOffsetOverflow {
// 根据 log 文件重建所有的 index 文件,并砍掉 log 和 index 末尾的无效 Bytes
recoverLog()
}
// reset the index size of the currently active log segment to allow more entries
activeSegment.resizeIndexes(config.maxIndexSize)
nextOffset
} else {
// 如果没有可用的目录,则创建一个空的日志文件
if (logSegments.isEmpty) {
addSegment(LogSegment.open(dir = dir,
baseOffset = 0,
config,
time = time,
fileAlreadyExists = false,
initFileSize = this.initFileSize,
preallocate = false))
}
0
}
}再看看核心的 loadSegmentFiles() 方法:
private def loadSegmentFiles(): Unit = {
// load segments in ascending order because transactional data from one segment may depend on the
// segments that come before it
// 因为事务型的数据可能和数据的时间关系有关,因此这里需要按时间顺序加载 segment 数据
for (file <- dir.listFiles.sortBy(_.getName) if file.isFile) {
if (isIndexFile(file)) {
// if it is an index file, make sure it has a corresponding .log file
// 确保索引文件有对应的(同名的,或者说同 offset 的) log 文件
val offset = offsetFromFile(file) // 读文件名,即就是当前日志的 base offset
val logFile = Log.logFile(dir, offset)
if (!logFile.exists) {
warn(s"Found an orphaned index file ${file.getAbsolutePath}, with no corresponding log file.")
Files.deleteIfExists(file.toPath)
}
} else if (isLogFile(file)) {
// if it's a log file, load the corresponding log segment
// 读文件名,确定 baseOffset
val baseOffset = offsetFromFile(file)
val timeIndexFileNewlyCreated = !Log.timeIndexFile(dir, baseOffset).exists()
// 创建 LogSegment 对象
val segment = LogSegment.open(dir = dir,
baseOffset = baseOffset,
config,
time = time,
fileAlreadyExists = true)
try segment.sanityCheck(timeIndexFileNewlyCreated)
catch {
case _: NoSuchFileException =>
error(s"Could not find offset index file corresponding to log file ${segment.log.file.getAbsolutePath}, " +
"recovering segment and rebuilding index files...")
recoverSegment(segment)
case e: CorruptIndexException =>
warn(s"Found a corrupted index file corresponding to log file ${segment.log.file.getAbsolutePath} due " +
s"to ${e.getMessage}}, recovering segment and rebuilding index files...")
recoverSegment(segment)
}
// 将 LogSegment 对象添加到 segment map 中
addSegment(segment)
}
}
}然后是 completeSwapOperations() 方法:
private def completeSwapOperations(swapFiles: Set[File]): Unit = {
for (swapFile <- swapFiles) {
val logFile = new File(CoreUtils.replaceSuffix(swapFile.getPath, SwapFileSuffix, ""))
val baseOffset = offsetFromFile(logFile)
// 从磁盘中加载 swap segment
val swapSegment = LogSegment.open(swapFile.getParentFile,
baseOffset = baseOffset,
config,
time = time,
fileSuffix = SwapFileSuffix)
info(s"Found log file ${swapFile.getPath} from interrupted swap operation, repairing.")
// 以 FileChannelRecordBatch 维度遍历 segment 文件,重建所有的 index 文件,并砍掉 log 和 index 末尾的无效 Bytes
recoverSegment(swapSegment)
// We create swap files for two cases:
// (1) Log cleaning where multiple segments are merged into one, and
// (2) Log splitting where one segment is split into multiple.
//
// 两种情况下会创建 swap 文件:
// 1. log clean(log compaction)的时候,将多个 segment 合并成一个的时候
// 2. log splitting(segment 中的数据超过 Int.MAX 条)的时候,将一个 segment 拆分成多个 segment
//
// Both of these mean that the resultant swap segments be composed of the original set, i.e. the swap segment
// must fall within the range of existing segment(s). If we cannot find such a segment, it means the deletion
// of that segment was successful. In such an event, we should simply rename the .swap to .log without having to
// do a replace with an existing segment.
//
// 如果找不到原始的 log 文件,也就不需要 replace 了,直接重命名就可以了
val oldSegments = logSegments(swapSegment.baseOffset, swapSegment.readNextOffset).filter { segment =>
segment.readNextOffset > swapSegment.baseOffset
}
replaceSegments(Seq(swapSegment), oldSegments.toSeq, isRecoveredSwapFile = true)
}
}至此,segmets 文件,就全部加载到 kafka 中了。
删除 segments
源码中对于删除 segment 有一个总的入口,从下面方法的实现可以清楚的看到哪些场景下会执行删除操作
/**
* If topic deletion is enabled, delete any log segments that have either expired due to time based retention
* or because the log size is > retentionSize.
*
* 如果配置文件里的 clean policy 是 delete,则删除超过生存期限的日志,以及日志大小超限的日志
*
* Whether or not deletion is enabled, delete any log segments that are before the log start offset
*
* 不论 clean policy 是什么,offset 小于 log start offset 的日志全部删除
*/
def deleteOldSegments(): Int = {
if (config.delete) {
// Breach: 违反\违背
deleteRetentionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() + deleteLogStartOffsetBreachedSegments()
} else {
deleteLogStartOffsetBreachedSegments()
}
}这三个方法的实现也非常简单:
private def deleteRetentionMsBreachedSegments(): Int = {
if (config.retentionMs < 0) return 0
val startMs = time.milliseconds
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]): Boolean = {
startMs - segment.largestTimestamp > config.retentionMs
}
deleteOldSegments(shouldDelete, RetentionMsBreach)
}
private def deleteRetentionSizeBreachedSegments(): Int = {
if (config.retentionSize < 0 || size < config.retentionSize) return 0
var diff = size - config.retentionSize
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]): Boolean = {
if (diff - segment.size >= 0) {
diff -= segment.size
true
} else {
false
}
}
deleteOldSegments(shouldDelete, RetentionSizeBreach)
}
private def deleteLogStartOffsetBreachedSegments(): Int = {
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]): Boolean = {
nextSegmentOpt.exists(_.baseOffset <= logStartOffset)
}
deleteOldSegments(shouldDelete, StartOffsetBreach)
}全部都调用了 deleteOldSegments 方法:从前向后,遍历所有的 segments,使用传入的 predicate(即shouldDelete) 方法,找出可以删除的 segments,然后再将它们删除掉
private def deleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean,
reason: SegmentDeletionReason): Int = {
lock synchronized {
val deletable = deletableSegments(predicate)
if (deletable.nonEmpty)
deleteSegments(deletable, reason)
else
0
}
}下面是遍历所有的 segment 的 deletableSegments 方法:
/**
* Find segments starting from the oldest until the user-supplied predicate is false or the segment
* containing the current high watermark is reached. We do not delete segments with offsets at or beyond
* the high watermark to ensure that the log start offset can never exceed it. If the high watermark
* has not yet been initialized, no segments are eligible for deletion.
*
* 从最早的 segment 开始遍历,直到传入的 predicate = false 或者达到了包含 high watermark 的 segment。
* 为了确保 log start offset ≤ high watermark,我们不会删除包含 high watermark 的 segment。
* 如果 hw 未初始化,则不会删除任何 segment。
*
* A final segment that is empty will never be returned (since we would just end up re-creating it).
*
* @param predicate A function that takes in a candidate log segment and the next higher segment
* (if there is one) and returns true iff it is deletable
* @return the segments ready to be deleted
*/
private def deletableSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean): Iterable[LogSegment] = {
if (segments.isEmpty) {
Seq.empty
} else {
val deletable = ArrayBuffer.empty[LogSegment]
var segmentEntry = segments.firstEntry
while (segmentEntry != null) {
val segment = segmentEntry.getValue
val nextSegmentEntry = segments.higherEntry(segmentEntry.getKey)
val (nextSegment, upperBoundOffset, isLastSegmentAndEmpty) = if (nextSegmentEntry != null)
(nextSegmentEntry.getValue, nextSegmentEntry.getValue.baseOffset, false)
else
(null, logEndOffset, segment.size == 0)
if (highWatermark >= upperBoundOffset && predicate(segment, Option(nextSegment)) && !isLastSegmentAndEmpty) {
deletable += segment
segmentEntry = nextSegmentEntry
} else {
segmentEntry = null
}
}
deletable
}
}然后再执行删除操作:
private def deleteSegments(deletable: Iterable[LogSegment], reason: SegmentDeletionReason): Int = {
maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {
val numToDelete = deletable.size
if (numToDelete > 0) {
// we must always have at least one segment, so if we are going to delete all the segments, create a new one first
if (segments.size == numToDelete)
roll()
lock synchronized {
checkIfMemoryMappedBufferClosed()
// 删除 segment:
// 首先调用 segments.remove() 方法,从 segments map 中删除对应的 segment,
// 然后给 segment 对应的 log|offsetIndex|timeIndex|txnIndex 文件加上后缀 .deleted
// 然后调用 scheduler 异步删除这些文件
// scheduler.schedule("delete-file", () => deleteSegments(), delay = config.fileDeleteDelayMs)
removeAndDeleteSegments(deletable, asyncDelete = true, reason)
// 如果上一步删除了日志,则 LogStartOffset 有可能发生改变
// 当 newLogStartOffset > oldLogStartOffset 的时候才会更新
// 此时,
// 如果 newLogStartOffset > highWatermark,则同时更新 hw
// 由于 logStartOffset 发生了变化,此时还需要同步更新 leaderEpochCache 中的内容
// (参考上文的 truncateFromStart 方法)
maybeIncrementLogStartOffset(segments.firstEntry.getValue.baseOffset, SegmentDeletion)
}
}
numToDelete
}
}向 log 中增加消息
/**
* Append this message set to the active segment of the log, rolling over to a fresh segment if necessary.
*
* 将数据 append 到 active segment 中,如果 segment 中的数据满了,就滚动创建一个新的 segment
*
* This method will generally be responsible for assigning offsets to the messages,
* however if the assignOffsets=false flag is passed we will only check that the existing offsets are valid.
*
* @param records The log records to append
* @param origin Declares the origin of the append which affects required validations
* @param interBrokerProtocolVersion Inter-broker message protocol version
* @param assignOffsets Should the log assign offsets to this message set or blindly apply what it is given
* @param leaderEpoch The partition's leader epoch which will be applied to messages when offsets are assigned on the leader
* @param ignoreRecordSize true to skip validation of record size.
* @throws KafkaStorageException If the append fails due to an I/O error.
* @throws OffsetsOutOfOrderException If out of order offsets found in 'records'
* @throws UnexpectedAppendOffsetException If the first or last offset in append is less than next offset
* @return Information about the appended messages including the first and last offset.
*/
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
assignOffsets: Boolean,
leaderEpoch: Int,
ignoreRecordSize: Boolean): LogAppendInfo = {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
// 校验 CRC、消息大小是否超限。构建 LogAppendInfo,里面保存着这批 records
// 的 firstOffset, lastOffset, maxTimestamp, offsetOfMaxTimestamp, codec
// 等信息
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize)
// return if we have no valid messages or if this is a duplicate of the last appended entry
// records 中的数据为空,直接退出
if (appendInfo.shallowCount == 0)
return appendInfo
// trim any invalid bytes or partial messages before appending it to the on-disk log
// 第一步校验的时候,如果某一个 batch 格式异常,会直接报错退出,
// 所以 invalid bytes 只有可能出现在最后一个 batch 的后面
// 这里比较 records.sizeInBytes 和 appendInfo.validBytes,
// 尝试删除末尾的 invalid bytes(如果有的话)
var validRecords = trimInvalidBytes(records, appendInfo)
// they are valid, insert them in the log
lock synchronized {
checkIfMemoryMappedBufferClosed()
// leader 副本调用 append 方法追加数据的时候,assignOffsets = true,会给消息分配一个 offset
// follower 副本调用 append 方法追加数据的时候,assignOffsets = false,会使用消息体中自带的 offset
if (assignOffsets) {
// 分配 offset,其实就是 LogEndOffset
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = Some(offset.value)
// 更新 offset,并且做进一步的验证,包括:
// 1. 启用了 compaction的 topic 的消息,必须包含 key
// 2. 当 magic >= 1 时,如果内部的消息是压缩过的,他们的 offset 必须是从 0 开始递增的
// 3. 当 magic >= 1 时,校验或修正时间戳
// 4. DefaultRecordBatch 中声明的 records 数量必须与实际数量一致
// 如果消息的版本与 topic 中配置的不一样,这个方法还会将消息转换为 topic 的配置的 message format 版本
// 为了兼容低版本的数据,这个方法里写了巨多关于格式校验和格式转换的处理代码,我们就不细看了
val now = time.milliseconds
val validateAndOffsetAssignResult = try {
LogValidator.validateMessagesAndAssignOffsets(validRecords,
topicPartition,
offset,
time,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.recordVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
leaderEpoch,
origin,
interBrokerProtocolVersion,
brokerTopicStats)
} catch {
case e: IOException =>
throw new KafkaException(s"Error validating messages while appending to log $name", e)
}
// 拿到了校验结果,补全 appendInfo 信息
validRecords = validateAndOffsetAssignResult.validatedRecords
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
appendInfo.lastOffset = offset.value - 1
appendInfo.recordConversionStats = validateAndOffsetAssignResult.recordConversionStats
if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME)
appendInfo.logAppendTime = now
// re-validate message sizes if there's a possibility that they have changed (due to re-compression or message
// format conversion)
// 上一步验证过程中,可能会做重新压缩或者格式转换,所以再次校验一下消息大小
if (!ignoreRecordSize && validateAndOffsetAssignResult.messageSizeMaybeChanged) {
for (batch <- validRecords.batches.asScala) {
if (batch.sizeInBytes > config.maxMessageSize) {
// we record the original message set size instead of the trimmed size
// to be consistent with pre-compression bytesRejectedRate recording
brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException(s"Message batch size is ${batch.sizeInBytes} bytes in append to" +
s"partition $topicPartition which exceeds the maximum configured size of ${config.maxMessageSize}.")
}
}
}
} else {
// we are taking the offsets we are given
// 采信消息体中的 offset(通常是 follower 副本拉取数据,然后调用 append 方法的场景)
// 拒绝非递增的消息序列
if (!appendInfo.offsetsMonotonic)
throw new OffsetsOutOfOrderException(s"Out of order offsets found in append to $topicPartition: " +
records.records.asScala.map(_.offset))
if (appendInfo.firstOrLastOffsetOfFirstBatch < nextOffsetMetadata.messageOffset) {
// we may still be able to recover if the log is empty
// one example: fetching from log start offset on the leader which is not batch aligned,
// which may happen as a result of AdminClient#deleteRecords()
//
// 异常情况: 待插入消息的 offset 小于 Log End Offset
//
// 一个已知的场景是:通过 AdminClient#deleteRecords() 删除了一部分消息,
// 导致从 Leader 节点获取日志起始 offset 时,该 offset 可能未对齐到批次的边界
//
// 通常来说是没得救的,但是在下面的情况下,还是能救的回来:
// logEndOffset == log.logStartOffset && firstOffset < logEndOffset && appendInfo.lastOffset >= logEndOffset
// 即:日志为空,并且,LogStartOffset 落在了待插入数据的中间的时候;
//
// 在 append 方法的最外层,会 catch 这个异常,然后对日志从 firstOffset 位置做一次 truncateFullyAndStartAt()
// 然后重复做一次 append
//
// 之所以要在最外层处理,是因为需要先删除当前 segment,然后创建一个新的 segment,并以 firstOffset 作为其 baseOffset
val firstOffset = appendInfo.firstOffset match {
case Some(offset) => offset
case None => records.batches.asScala.head.baseOffset()
}
val firstOrLast = if (appendInfo.firstOffset.isDefined) "First offset" else "Last offset of the first batch"
throw new UnexpectedAppendOffsetException(
s"Unexpected offset in append to $topicPartition. $firstOrLast " +
s"${appendInfo.firstOrLastOffsetOfFirstBatch} is less than the next offset ${nextOffsetMetadata.messageOffset}. " +
s"First 10 offsets in append: ${records.records.asScala.take(10).map(_.offset)}, last offset in" +
s" append: ${appendInfo.lastOffset}. Log start offset = $logStartOffset",
firstOffset, appendInfo.lastOffset)
}
}
// update the epoch cache with the epoch stamped onto the message by the leader
// 更新 leaderEpochCache(如果需要的话)
validRecords.batches.forEach { batch =>
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) {
// 比较入参和 epochCache 中的 item,如果有冲突,根据具体情况,
// 可能会直接追加一个 item,也有可能截掉一部分 item 然后再追加,
// 当然也有可能不做任何操作
maybeAssignEpochStartOffset(batch.partitionLeaderEpoch, batch.baseOffset)
} else {
// In partial upgrade scenarios, we may get a temporary regression to the message format. In
// order to ensure the safety of leader election, we clear the epoch cache so that we revert
// to truncation by high watermark after the next leader election.
// 在分步升级的场景下,可能会出现消息格式降级。为了确保选举的正确性,
// 会清理 epoch cache,以便在下一次选举之后,重新从高水位开始截断。
// 这是因为V2及以上版本中,使用 partitionLeaderEpoch 来明确的指示 epoch 信息,
// 而旧版本的消息中不包含 partitionLeaderEpoch,它是以 hw 作为主要的截断依据。
// 如果不清除缓存,可能会导致领导者选举后无法正确回滚到合适的偏移量。
// 清除缓存后,系统会回退到基于高水位标记的日志截断(truncation by high watermark)机制,
// 以确保系统的安全性
leaderEpochCache.filter(_.nonEmpty).foreach { cache =>
warn(s"Clearing leader epoch cache after unexpected append with message format v${batch.magic}")
cache.clearAndFlush()
}
}
}
// check messages set size may be exceed config.segmentSize
if (validRecords.sizeInBytes > config.segmentSize) {
throw new RecordBatchTooLargeException(s"Message batch size is ${validRecords.sizeInBytes} bytes in append " +
s"to partition $topicPartition, which exceeds the maximum configured segment size of ${config.segmentSize}.")
}
// 如果当前 segment 已经满了,就轮转生成一个新的 segment
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
// now that we have valid records, offsets assigned, and timestamps updated, we need to
// validate the idempotent/transactional state of the producers and collect some metadata
// 验证事务状态
val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState(
logOffsetMetadata, validRecords, origin)
maybeDuplicate.foreach { duplicate =>
appendInfo.firstOffset = Some(duplicate.firstOffset)
appendInfo.lastOffset = duplicate.lastOffset
appendInfo.logAppendTime = duplicate.timestamp
appendInfo.logStartOffset = logStartOffset
return appendInfo
}
// 实际写入消息,可以在上一篇文章查看具体实现
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// Increment the log end offset. We do this immediately after the append because a
// write to the transaction index below may fail and we want to ensure that the offsets
// of future appends still grow monotonically. The resulting transaction index inconsistency
// will be cleaned up after the log directory is recovered. Note that the end offset of the
// ProducerStateManager will not be updated and the last stable offset will not advance
// if the append to the transaction index fails.
// 更新 logEndOffset。因为 transaction index 的写入可能失败,而我们又要保证未来写入消息的 offset 递增,
// 所以在写入消息之后立即更新 LEO。因此产生的 transaction index 不一致将会在日志目录 recovered 的时候被解决。
// 注意,如果transaction index写入失败时,ProducerStateManager 的 end offset 不会被更新,
// last stable offset 也不会前进。
updateLogEndOffset(appendInfo.lastOffset + 1)
// update the producer state
// 更新事务状态
for (producerAppendInfo <- updatedProducers.values) {
producerStateManager.update(producerAppendInfo)
}
// update the transaction index with the true last stable offset. The last offset visible
// to consumers using READ_COMMITTED will be limited by this value and the high watermark.
for (completedTxn <- completedTxns) {
val lastStableOffset = producerStateManager.lastStableOffset(completedTxn)
segment.updateTxnIndex(completedTxn, lastStableOffset)
producerStateManager.completeTxn(completedTxn)
}
// always update the last producer id map offset so that the snapshot reflects the current offset
// even if there isn't any idempotent data being written
// 不太懂,以后再看
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
// update the first unstable offset (which is used to compute LSO)
maybeIncrementFirstUnstableOffset()
trace(s"Appended message set with last offset: ${appendInfo.lastOffset}, " +
s"first offset: ${appendInfo.firstOffset}, " +
s"next offset: ${nextOffsetMetadata.messageOffset}, " +
s"and messages: $validRecords")
if (unflushedMessages >= config.flushInterval)
flush()
appendInfo
}
}
}从 log 读取消息
/**
* Read messages from the log.
*
* @param startOffset The offset to begin reading at
* @param maxLength The maximum number of bytes to read
* @param isolation The fetch isolation, which controls the maximum offset we are allowed to read
* @param minOneMessage If this is true, the first message will be returned even if it exceeds `maxLength` (if one exists)
* @throws OffsetOutOfRangeException If startOffset is beyond the log end offset or before the log start offset
* @return The fetch data information including fetch starting offset metadata and messages read.
*/
def read(startOffset: Long,
maxLength: Int,
isolation: FetchIsolation,
minOneMessage: Boolean): FetchDataInfo = {
maybeHandleIOException(s"Exception while reading from $topicPartition in dir ${dir.getParent}") {
trace(s"Reading maximum $maxLength bytes at offset $startOffset from log with " +
s"total length $size bytes")
val includeAbortedTxns = isolation == FetchTxnCommitted
// Because we don't use the lock for reading, the synchronization is a little bit tricky.
// We create the local variables to avoid race conditions with updates to the log.
// 读操作都没有加锁,所以这里也不打算取巧加锁。而是创建一个本地变量,
// 用来保存最后一条消息的 offset,防止读到脏数据。
val endOffsetMetadata = nextOffsetMetadata
val endOffset = endOffsetMetadata.messageOffset
// private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
// 在 segment map 中,找到 startOffset 所在的那一个 segment,从这个 segment 开始查找
var segmentEntry = segments.floorEntry(startOffset)
// return error on attempt to read beyond the log end offset or read below log start offset
if (startOffset > endOffset || segmentEntry == null || startOffset < logStartOffset)
throw new OffsetOutOfRangeException(s"Received request for offset $startOffset for partition $topicPartition, " +
s"but we only have log segments in the range $logStartOffset to $endOffset.")
val maxOffsetMetadata = isolation match {
// 表示查询所有日志
case FetchLogEnd => endOffsetMetadata
// 表示查询所有 hw 以下的日志,即 consumer 可见的日志
case FetchHighWatermark => fetchHighWatermarkMetadata
// 表示查询所有已提交的事务(LSO)的日志
case FetchTxnCommitted => fetchLastStableOffsetMetadata
}
if (startOffset == maxOffsetMetadata.messageOffset) {
return emptyFetchDataInfo(maxOffsetMetadata, includeAbortedTxns)
} else if (startOffset > maxOffsetMetadata.messageOffset) {
val startOffsetMetadata = convertToOffsetMetadataOrThrow(startOffset)
return emptyFetchDataInfo(startOffsetMetadata, includeAbortedTxns)
}
// Do the read on the segment with a base offset less than the target offset
// but if that segment doesn't contain any messages with an offset greater than that
// continue to read from successive segments until we get some messages or we reach the end of the log
//
// 从 baseOffset 小于 startOffset 的 segment 开始遍历后续的所有 segment,查找消息
while (segmentEntry != null) {
val segment = segmentEntry.getValue
val maxPosition = {
// Use the max offset position if it is on this segment; otherwise, the segment size is the limit.
// 1. 如果 maxOffsetMetadata 和我们要找的 offset 在同一个 segment, 就以它的 position 为查找的限制
// 2. 如果 maxOffsetMetadata 和我们要找的 offset 不在同一个 segment,
// 则说明 maxOffsetMetadata 在后续的 segment 中,那么就以当前 segment 的 size 为查找的限制
if (maxOffsetMetadata.segmentBaseOffset == segment.baseOffset) {
maxOffsetMetadata.relativePositionInSegment
} else {
segment.size
}
}
// 这里的 read 方法,我们上一篇文章已经看过了,这里不再赘述
val fetchInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)
if (fetchInfo == null) {
// 没找到的话,就继续遍历下一个 segment
segmentEntry = segments.higherEntry(segmentEntry.getKey)
} else {
// 找到了就返回
return if (includeAbortedTxns)
addAbortedTransactions(startOffset, segmentEntry, fetchInfo)
else
fetchInfo
}
}
// okay we are beyond the end of the last segment with no data fetched although the start offset is in range,
// this can happen when all messages with offset larger than start offsets have been deleted.
// In this case, we will return the empty set with log end offset metadata
//
// 走到这里说明尽管 start offset 是在 max offset 的范围内,但是我们遍历完所有的 segment 也没有找到消息。
// 这种情况是因为所有 offset 大于 start offset 的消息都被删除了。
// 这时候,返回下一条待插入消息的 metaData(不包含 records)
FetchDataInfo(nextOffsetMetadata, MemoryRecords.EMPTY)
}
}
四、High Watermark 相关源码
从上文中,我们已经看到了 HW 的定义:
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)那 LogOffsetMetadata 又是什么呢?我们来看看它的定义:
/*
* A log offset structure, including:
* 1. the message offset
* 2. the base message offset of the located segment
* 3. the physical position on the located segment
*/
// 封装着消息的位移信息,包括:
// 1. 它的 offset
// 2. 所处的 segment 的 baseOffset
// 3. 所处的 segment 的日志文件的物理位置
case class LogOffsetMetadata(messageOffset: Long,
segmentBaseOffset: Long = Log.UnknownOffset,
relativePositionInSegment: Int = LogOffsetMetadata.UnknownFilePosition) {
......
// 通过比较 segmentBaseOffset 可以判断两个 LogOffsetMetadata 是否处于同一个 segment
def onSameSegment(that: LogOffsetMetadata): Boolean = {
if (messageOffsetOnly)
throw new KafkaException(s"$this cannot compare its segment info with $that since it only has message offset info")
this.segmentBaseOffset == that.segmentBaseOffset
}
// 计算两个 LogOffsetMetadata 的 offset 差值
def offsetDiff(that: LogOffsetMetadata): Long = {
this.messageOffset - that.messageOffset
}
// compute the number of bytes between this offset to the given offset
// if they are on the same segment and this offset precedes the given offset
// 如果两个对象处于同一个 segment,计算他们对应的消息之间差了多少 bytes
def positionDiff(that: LogOffsetMetadata): Int = {
if(!onSameSegment(that))
throw new KafkaException(s"$this cannot compare its segment position with $that since they are not on the same segment")
if(messageOffsetOnly)
throw new KafkaException(s"$this cannot compare its segment position with $that since it only has message offset info")
this.relativePositionInSegment - that.relativePositionInSegment
}
......
override def toString = s"(offset=$messageOffset segment=[$segmentBaseOffset:$relativePositionInSegment])"
}ok 这里,我们现在了解了 highWatermarkMetadata 对象的基本结构,下来看一看 HW 是如何更新的
获取 HW
// LogOffsetMetadata 中可能只包含一个 absolute offset,而不包含 segmentBaseOffset 和 relativePositionInSegment,
// 这时候需要去 Log 中查找出该 offset 对应的 segmentBaseOffset 和 relativePositionInSegment
// 然后重新封装成 LogOffsetMetadata 并返回
private def fetchHighWatermarkMetadata: LogOffsetMetadata = {
checkIfMemoryMappedBufferClosed()
val offsetMetadata = highWatermarkMetadata
// 如果只包含一个 absolute offset,则需要补全其他信息
if (offsetMetadata.messageOffsetOnly) {
lock.synchronized {
// 遍历 segment 文件,找到对应的消息,补全 LogOffsetMetadata 中的 segmentBaseOffset 和 relativePositionInSegment
val fullOffset = convertToOffsetMetadataOrThrow(highWatermark)
// 上一步补全了 LogOffsetMetadata 的信息,这一步更新到 hw 中
updateHighWatermarkMetadata(fullOffset)
fullOffset
}
} else {
offsetMetadata
}
}其中的 convertToOffsetMetadataOrThrow 方法,其实就是调用了 Log 对象的 read 方法,从指定的 offset 读出该条信息的 metadata
private def convertToOffsetMetadataOrThrow(offset: Long): LogOffsetMetadata = {
val fetchDataInfo = read(offset,
maxLength = 1,
isolation = FetchLogEnd,
minOneMessage = false)
fetchDataInfo.fetchOffsetMetadata
}更新 HW
更新 high watermark 的方法一,主要用在 Follower 副本从 Leader 副本获取到消息后更新高水位值。一旦拿到新的消息,就必须要更新高水位值:
/**
* Update high watermark with offset metadata. The new high watermark will be lower
* bounded by the log start offset and upper bounded by the log end offset.
*
* 更新 high watermark。注意不能 < logStartOffset,也不能 ≥ logEndOffset
*
* @param highWatermarkMetadata the suggested high watermark with offset metadata
* @return the updated high watermark offset
*/
def updateHighWatermark(highWatermarkMetadata: LogOffsetMetadata): Long = {
val endOffsetMetadata = logEndOffsetMetadata
val newHighWatermarkMetadata = if (highWatermarkMetadata.messageOffset < logStartOffset) {
LogOffsetMetadata(logStartOffset)
} else if (highWatermarkMetadata.messageOffset >= endOffsetMetadata.messageOffset) {
endOffsetMetadata
} else {
highWatermarkMetadata
}
updateHighWatermarkMetadata(newHighWatermarkMetadata)
newHighWatermarkMetadata.messageOffset
}更新 high watermark 的方法二,主要是用来更新 Leader 副本的高水位值。需要注意的是,Leader 副本高水位值的更新是有条件的,某些情况下会更新高水位值,某些情况下可能不会(比如正在等待其他 Follower 的同步进度):
/**
* Update the high watermark to a new value if and only if it is larger than the old value. It is
* an error to update to a value which is larger than the log end offset.
*
* This method is intended to be used by the leader to update the high watermark after follower
* fetch offsets have been updated.
*
* 这个方法主要是用于 leader 副本更新了 follower 副本的 fetch offset 更新之后
* (也就是 follower 副本拉取了数据之后)
*
* @return the old high watermark, if updated by the new value
*/
def maybeIncrementHighWatermark(newHighWatermark: LogOffsetMetadata): Option[LogOffsetMetadata] = {
if (newHighWatermark.messageOffset > logEndOffset)
throw new IllegalArgumentException(s"High watermark $newHighWatermark update exceeds current " +
s"log end offset $logEndOffsetMetadata")
lock.synchronized {
// LogOffsetMetadata 中可能只包含一个 absolute offset,而不包含 segmentBaseOffset 和 relativePositionInSegment,
// 这时候需要去 Log 中查找出该 offset 对应的 segmentBaseOffset 和 relativePositionInSegment
// 然后重新封装成 LogOffsetMetadata 并返回
val oldHighWatermark = fetchHighWatermarkMetadata
// Ensure that the high watermark increases monotonically. We also update the high watermark when the new
// offset metadata is on a newer segment, which occurs whenever the log is rolled to a new segment.
// 确保 hw 是单调递增的
// 当 log 轮转的时候,offset metadata 移到新的 segment,也会更新 hw
if (oldHighWatermark.messageOffset < newHighWatermark.messageOffset ||
(oldHighWatermark.messageOffset == newHighWatermark.messageOffset && oldHighWatermark.onOlderSegment(newHighWatermark))) {
updateHighWatermarkMetadata(newHighWatermark)
Some(oldHighWatermark)
} else {
None
}
}
}