Controller 是 Kafka 最核心的组件之一。一方面,它要为集群中的所有主题分区选举领导者副本;另一方面,它还承载着集群的全部元数据信息,并负责将这些元数据信息同步到其他 Broker 上
一、Controller 与 Broker 通信
Controller Request
在 Kafka 工程目录中,我们可以找到 AbstractControlRequest 类,这是 controller request 的基础类,在 2.7.2 版本中,有三个具体的实现类,也就是说,目前 Controller 在于 brokers 交互的时候,只有这三类场景:
UpdateMetadataRequest: 用于更新 broker 上的 Controller 元数据LeaderAndIsrRequest:用于更新 broker 上,leader 副本信息,以及 in-sync 副本信息StopReplicaRequest:用于告知 broker 停止某个副本对象,删除日志数据。主要的使用场景,是分区副本迁移和删除主题
下面是 AbstractControlRequest 类的代码:
public abstract class AbstractControlRequest extends AbstractRequest {
public static final long UNKNOWN_BROKER_EPOCH = -1L;
public static abstract class Builder<T extends AbstractRequest> extends AbstractRequest.Builder<T> {
// Controller 所在的 brokerId
protected final int controllerId;
// Kafka 通过 controllerEpoch 确保请求是来自最新的 Controller,
// 以防止旧的 Controller 发送的指令对集群产生不一致的影响
protected final int controllerEpoch;
// 目标 Broker 的版本信息。用于隔离 Zombie Broker,即一个非常老的 Broker 被选举成为 Controller
protected final long brokerEpoch;
......
}
......
}Controller Request 的发送
跟 Processor 和 KafkaRequestHandler 的交互模式类似,Controller 向 broker 发送消息的过程,也是通过 “生产者-消费者” 的模式实现的。
Controller 会为集群中的每个 Broker 都创建一个的 RequestSendThread 线程、一个消息队列 messageQueue、以及一个 httpClient(networkClient)。
Controller 事件处理线程负责向 Broker 对应 messageQueue 写入待发送的请求,而 RequestSendThread 线程会持续地从阻塞队列中获取待发送的请求,并执行真正的发送操作。
那么,这个 messageQueue 长什么样子呢:
val messageQueue = new LinkedBlockingQueue[QueueItem]其中的 QueueItem 的定义是:
case class QueueItem(apiKey: ApiKeys, request: AbstractControlRequest.Builder[_ <: AbstractControlRequest],
callback: AbstractResponse => Unit, enqueueTimeMs: Long)从构造方法的参数中,我们可以找到上文提到的 AbstractControlRequest
消费者:RequestSendThread
接下来,我们看一看 RequestSendThread 的源码,看看请求是如何发送出去的。
下面是它的定义:
class RequestSendThread(val controllerId: Int,
val controllerContext: ControllerContext,
val queue: BlockingQueue[QueueItem],
val networkClient: NetworkClient,
val brokerNode: Node,
val config: KafkaConfig,
val time: Time,
val requestRateAndQueueTimeMetrics: Timer,
val stateChangeLogger: StateChangeLogger,
name: String)
extends ShutdownableThread(name = name) {RequestSendThread 继承了 kafka 中定义的 ShutdownableThread 类,它的 run 方法中,循环调用了下面的 doWork() 方法,来不断的从队列中读取数据:
// 循环调用 doWork 方法
override def run(): Unit = {
isStarted = true
try {
while (isRunning)
doWork()
} catch {
case e: FatalExitError => ......
case e: Throwable => ......
} finally {
shutdownComplete.countDown()
}
}
override def doWork(): Unit = {
// 调用 shutdownInitiated.await(timeout, unit),看看线程是不是关闭了
def backoff(): Unit = pause(100, TimeUnit.MILLISECONDS)
// 从队列中取数据
val QueueItem(apiKey, requestBuilder, callback, enqueueTimeMs) = queue.take()
// 记录时间指标,防止 controller request 在队列中等待太久
requestRateAndQueueTimeMetrics.update(time.milliseconds() - enqueueTimeMs, TimeUnit.MILLISECONDS)
var clientResponse: ClientResponse = null
try {
var isSendSuccessful = false
while (isRunning && !isSendSuccessful) {
// if a broker goes down for a long time, then at some point the controller's zookeeper listener will trigger a
// removeBroker which will invoke shutdown() on this thread. At that point, we will stop retrying.
// 如果 broker 挂了一段时间,那么 controller 的 zookeeper listener 会调用 removeBroker 方法,
// 这个方法会调用当前类的 shutdown() 方法,标记为线程关闭状态,此时,我们就终止重试。
try {
// 与 broker 的连接没有建立成功,尝试重连
if (!brokerReady()) {
// 等了一段时间,连接还是没有建立成功
isSendSuccessful = false
// 等待看看是不是当前线程正在关闭
// 内部调用的是 shutdownInitiated.await(timeout, unit),防止循环跑飞了
backoff()
}
else {
// 构建请求
val clientRequest = networkClient.newClientRequest(brokerNode.idString, requestBuilder,
time.milliseconds(), true)
// 发送请求
clientResponse = NetworkClientUtils.sendAndReceive(networkClient, clientRequest, time)
isSendSuccessful = true
}
} catch {
case e: Throwable =>
warn(s"Controller $controllerId epoch ${controllerContext.epoch} fails to send request $requestBuilder " +
s"to broker $brokerNode. Reconnecting to broker.", e)
networkClient.close(brokerNode.idString)
isSendSuccessful = false
backoff()
}
}
// 发送成功
if (clientResponse != null) {
// 确保响应的请求类型是 leaderAndIsr, stopReplica, updateMetadata
val requestHeader = clientResponse.requestHeader
val api = requestHeader.apiKey
if (api != ApiKeys.LEADER_AND_ISR && api != ApiKeys.STOP_REPLICA && api != ApiKeys.UPDATE_METADATA)
throw new KafkaException(s"Unexpected apiKey received: $apiKey")
val response = clientResponse.responseBody
// 回调
if (callback != null) {
callback(response)
}
}
} catch {
case e: Throwable =>
error(s"Controller $controllerId fails to send a request to broker $brokerNode", e)
// If there is any socket error (eg, socket timeout), the connection is no longer usable and needs to be recreated.
networkClient.close(brokerNode.idString)
}
}生产者:ControllerChannelManager
事实上,ControllerChannelManager 不光扮演了生产者的角色,还扮演了 RequestSendThread 线程的创建者角色,管理 Controller 与集群 Broker 之间的连接。
class ControllerChannelManager(controllerContext: ControllerContext,
config: KafkaConfig,
time: Time,
metrics: Metrics,
stateChangeLogger: StateChangeLogger,
threadNamePrefix: Option[String] = None) extends Logging with KafkaMetricsGroup {
// 保存着所有 broker 的信息
// key 是 BrokerId
// value 是 ControllerBrokerStateInfo,可以理解为一个容器类,保存着
// 1. broker node 信息:host、port 等
// 2. messageQueue
// 3. RequestSendThread
protected val brokerStateInfo = new HashMap[Int, ControllerBrokerStateInfo]
// 新增 borker
private def addNewBroker(broker: Broker): Unit = {
// 为每一个 broker 创建一个单独的消息队列
val messageQueue = new LinkedBlockingQueue[QueueItem]
debug(s"Controller ${config.brokerId} trying to connect to broker ${broker.id}")
......
// 单独为 controller request 创建 networkClient 和 KafkaChannel
val (networkClient, reconfigurableChannelBuilder) = {
val channelBuilder = ChannelBuilders.clientChannelBuilder(
......
controllerToBrokerSecurityProtocol,
config,
config.saslMechanismInterBrokerProtocol,
config.saslInterBrokerHandshakeRequestEnable,
......
)
val reconfigurableChannelBuilder = channelBuilder match {
// 如果 channelBuilder 实现了 Reconfigurable 接口,则表示支持在 kafka 运行过程中热更新
// 目前,plainText 协议不支持 reconfig,ssl 和 sasl 协议支持 reconfig
case reconfigurable: Reconfigurable =>
config.addReconfigurable(reconfigurable)
Some(reconfigurable)
case _ => None
}
val selector = new Selector(......)
val networkClient = new NetworkClient(......)
(networkClient, reconfigurableChannelBuilder)
}
......
// 用于统计请求频率,和消息在队列中等待的耗时
val requestRateAndQueueTimeMetrics = newTimer(
RequestRateAndQueueTimeMetricName, TimeUnit.MILLISECONDS, TimeUnit.SECONDS, brokerMetricTags(broker.id)
)
// 创建消费者线程
val requestThread = new RequestSendThread(config.brokerId, controllerContext, messageQueue, networkClient,
brokerNode, config, time, requestRateAndQueueTimeMetrics, stateChangeLogger, threadName)
requestThread.setDaemon(false)
// 将上面创建的所有 broker 相关的对象,塞到 ControllerBrokerStateInfo 中保存起来
brokerStateInfo.put(broker.id, ControllerBrokerStateInfo(networkClient, brokerNode, messageQueue,
requestThread, queueSizeGauge, requestRateAndQueueTimeMetrics, reconfigurableChannelBuilder))
}
// 发送请求
def sendRequest(brokerId: Int, request: AbstractControlRequest.Builder[_ <: AbstractControlRequest],
callback: AbstractResponse => Unit = null): Unit = {
brokerLock synchronized {
// 根据 brokerId 找到 broker
val stateInfoOpt = brokerStateInfo.get(brokerId)
stateInfoOpt match {
case Some(stateInfo) =>
// 找到对应的消息队列,插入消息,等待 RequestSendThread 线程拉取
stateInfo.messageQueue.put(QueueItem(request.apiKey, request, callback, time.milliseconds()))
case None =>
warn(s"Not sending request $request to broker $brokerId, since it is offline.")
}
}
}
......
}
二、Controller 管理内部事件
Controller Event
和 control request 类似,kafka 对于 controller 所负责的事件,也定义了 ControllerEvent 类,以及一批和 contorller 职责相关的实现类:
sealed trait ControllerEvent {
// preempt() is not executed by `ControllerEventThread` but by the main thread.
// 抢占队列之前的事件进行优先处理
def preempt(): Unit
def state: ControllerState
}
case object ControllerChange extends ControllerEvent {
override def state: ControllerState = ControllerState.ControllerChange
override def preempt(): Unit = {}
}
case object ShutdownEventThread extends ControllerEvent {
override def state: ControllerState = ControllerState.ControllerShutdown
override def preempt(): Unit = {}
}
case object BrokerChange extends ControllerEvent {
override def state: ControllerState = ControllerState.BrokerChange
override def preempt(): Unit = {}
}
case class PartitionModifications(topic: String) extends ControllerEvent {
override def state: ControllerState = ControllerState.TopicChange
override def preempt(): Unit = {}
}
......
其中 ControllerState 的源码如下:
sealed abstract class ControllerState {
def value: Byte
def rateAndTimeMetricName: Option[String] =
if (hasRateAndTimeMetric) Some(s"${toString}RateAndTimeMs") else None
protected def hasRateAndTimeMetric: Boolean = true
}
object ControllerState {
// Note: `rateAndTimeMetricName` is based on the case object name by default. Changing a name is a breaking change
// unless `rateAndTimeMetricName` is overridden.
// 注意上面的 rateAndTimeMetricName 方法,这个指标名称,其实是取得是类名
case object Idle extends ControllerState {
def value = 0
override protected def hasRateAndTimeMetric: Boolean = false
}
case object ControllerChange extends ControllerState {
def value = 1
}
case object BrokerChange extends ControllerState {
def value = 2
override def rateAndTimeMetricName = Some("LeaderElectionRateAndTimeMs")
}
case object IsrChange extends ControllerState {
def value = 9
}
case object LogDirChange extends ControllerState {
def value = 11
}
case object UncleanLeaderElectionEnable extends ControllerState {
def value = 13
}
......
}
截止 2.7.2 版本,一共定义了 27 个 Controller Event 和 17 个 Controller State,也就是说,一个 state 可能对应多个 Event,例如:
| ControllerEvent | ControllerState |
|---|---|
| TopicChange | TopicChange |
| PartitionModifications | |
| ControllerChange | ControllerChange |
| Reelect | |
| RegisterBrokerAndReelect | |
| Expire | |
| Startup |
Controller Event 的处理
和上文的 Control Request 类似,Controller Event 的处理,也是通过 “生产者-消费者” 的模式实现的。
Controller 会创建一个 ControllerEventThread 线程,来分发处理各种不同的 event。
当 Controller 产生了某种事件时,会向 eventQueue 写入事件一个 event,而 ControllerEventThread 线程会持续地从阻塞队列中获取事件,然后找到对应的处理器去处理。
那么,这个 eventQueue 长什么样子呢:
private val queue = new LinkedBlockingQueue[QueuedEvent]其中的 QueuedEvent 的定义如下,其中的 process 方法,其实就是调用传入的 Processor 来处理当前的 event
class QueuedEvent(val event: ControllerEvent,
val enqueueTimeMs: Long) {
// 标记事件的状态
val processingStarted = new CountDownLatch(1)
val spent = new AtomicBoolean(false)
def process(processor: ControllerEventProcessor): Unit = {
if (spent.getAndSet(true))
return
processingStarted.countDown()
processor.process(event)
}
def preempt(processor: ControllerEventProcessor): Unit = {
if (spent.getAndSet(true))
return
processor.preempt(event)
}
def awaitProcessing(): Unit = {
processingStarted.await()
}
}
消费者:ControllerEventThread
接下来,我们看一看 ControllerEventThread 的源码,是如何从队列中取出 event,并分发请求的:
class ControllerEventThread(name: String) extends ShutdownableThread(name = name, isInterruptible = false) {
override def doWork(): Unit = {
val dequeued = pollFromEventQueue()
dequeued.event match {
case ShutdownEventThread => // The shutting down of the thread has been initiated at this point. Ignore this event.
case controllerEvent =>
_state = controllerEvent.state
// 统计 event 在队列中等待的时间
eventQueueTimeHist.update(time.milliseconds() - dequeued.enqueueTimeMs)
try {
// 调用 processor 去处理 event
def process(): Unit = dequeued.process(processor)
rateAndTimeMetrics.get(state) match {
case Some(timer) => timer.time { process() }
case None => process()
}
} catch {
case e: Throwable => error(s"Uncaught error processing event $controllerEvent", e)
}
_state = ControllerState.Idle
}
}
}
private def pollFromEventQueue(): QueuedEvent = {
// 这个直方图指标是用于记录 event 在队列里的等待时间的;
// 如果队列中长时间没有数据,那么直方图中已有的数据已不再反映当前的队列状态,
// 所以这种情况下要清空直方图,重新统计。
val count = eventQueueTimeHist.count()
if (count != 0) {
val event = queue.poll(eventQueueTimeTimeoutMs, TimeUnit.MILLISECONDS)
if (event == null) {
eventQueueTimeHist.clear()
queue.take()
} else {
event
}
} else {
queue.take()
}
}
那么 processor 是怎么处理的呢,其实很简单,就是根据不同的 event,调用不同的处理逻辑:
override def process(event: ControllerEvent): Unit = {
try {
event match {
case event: MockEvent =>
// Used only in test cases
event.process()
case ShutdownEventThread =>
error("Received a ShutdownEventThread event. This type of event is supposed to be handle by ControllerEventThread")
case AutoPreferredReplicaLeaderElection =>
processAutoPreferredReplicaLeaderElection()
case ReplicaLeaderElection(partitions, electionType, electionTrigger, callback) =>
processReplicaLeaderElection(partitions, electionType, electionTrigger, callback)
case UncleanLeaderElectionEnable =>
processUncleanLeaderElectionEnable()
case TopicUncleanLeaderElectionEnable(topic) =>
processTopicUncleanLeaderElectionEnable(topic)
case ControlledShutdown(id, brokerEpoch, callback) =>
processControlledShutdown(id, brokerEpoch, callback)
case LeaderAndIsrResponseReceived(response, brokerId) =>
processLeaderAndIsrResponseReceived(response, brokerId)
case UpdateMetadataResponseReceived(response, brokerId) =>
processUpdateMetadataResponseReceived(response, brokerId)
case TopicDeletionStopReplicaResponseReceived(replicaId, requestError, partitionErrors) =>
processTopicDeletionStopReplicaResponseReceived(replicaId, requestError, partitionErrors)
case BrokerChange =>
processBrokerChange()
case BrokerModifications(brokerId) =>
processBrokerModification(brokerId)
case ControllerChange =>
processControllerChange()
case Reelect =>
processReelect()
case RegisterBrokerAndReelect =>
processRegisterBrokerAndReelect()
case Expire =>
processExpire()
case TopicChange =>
processTopicChange()
case LogDirEventNotification =>
processLogDirEventNotification()
case PartitionModifications(topic) =>
processPartitionModifications(topic)
case TopicDeletion =>
processTopicDeletion()
case ApiPartitionReassignment(reassignments, callback) =>
processApiPartitionReassignment(reassignments, callback)
case ZkPartitionReassignment =>
processZkPartitionReassignment()
case ListPartitionReassignments(partitions, callback) =>
processListPartitionReassignments(partitions, callback)
case UpdateFeatures(request, callback) =>
processFeatureUpdates(request, callback)
case PartitionReassignmentIsrChange(partition) =>
processPartitionReassignmentIsrChange(partition)
case IsrChangeNotification =>
processIsrChangeNotification()
case AlterIsrReceived(brokerId, brokerEpoch, isrsToAlter, callback) =>
processAlterIsr(brokerId, brokerEpoch, isrsToAlter, callback)
case Startup =>
processStartup()
}
} catch {
case e: ControllerMovedException =>
info(s"Controller moved to another broker when processing $event.", e)
maybeResign()
case e: Throwable =>
error(s"Error processing event $event", e)
} finally {
updateMetrics()
}
}
生产者:ControllerEventManager
KafkaController 在初始化的时候,会创建 ControllerEventManager:
private[controller] val eventManager = new ControllerEventManager(config.brokerId, this, time,
controllerContext.stats.rateAndTimeMetrics)ControllerEventManager 中我们可以看到 event 队列和入队的 put 方法:
class ControllerEventManager(controllerId: Int,
processor: ControllerEventProcessor,
time: Time,
rateAndTimeMetrics: Map[ControllerState, KafkaTimer],
eventQueueTimeTimeoutMs: Long = 300000) extends KafkaMetricsGroup {
// controller event 队列
private val queue = new LinkedBlockingQueue[QueuedEvent]
// controller event 线程
private[controller] var thread = new ControllerEventThread(ControllerEventThreadName)
// 一旦 kafka 的工作流程中,触发了 ControllerEvent,就会创建一个 event 对象
// 等待 Processor 线程去处理
def put(event: ControllerEvent): QueuedEvent = inLock(putLock) {
val queuedEvent = new QueuedEvent(event, time.milliseconds())
queue.put(queuedEvent)
queuedEvent
}到这里,我们可以发现 ControllerChannelManager 和 ControllerEventManager 的工作模式是相当相似的,他们都是通过 “生产者-消费者” 这样的思路,来分发并处理数据的。
三、Controller 选举
监听器:Controller 还活着吗?
在 Kafka 集群中,某段时间内只能有一台 Broker 被选举为 Controller,而 Controller 的选举过程则依赖与 ZooKeeper,每个 Broker 都会监听 zk 上的 /controller 节点随时准备竞争 Controller 角色。
下面这张图就是 /controller 节点上保存的信息,里面最重要的就是 brokerId,这个 broker 就是当前集群中的 Controller:

在源码的 KafkaController 类中,定义了一系列的 ZooKeeper 监听器,用来监听 ZooKeeper 中各个节点的变化:
class KafkaController(val config: KafkaConfig,
zkClient: KafkaZkClient, // 与 zk 交互的客户端
time: Time,
metrics: Metrics,
initialBrokerInfo: BrokerInfo,
initialBrokerEpoch: Long, // 用于隔离老Controller发送的请求
tokenManager: DelegationTokenManager,
brokerFeatures: BrokerFeatures,
featureCache: FinalizedFeatureCache,
threadNamePrefix: Option[String] = None)
extends ControllerEventProcessor with Logging with KafkaMetricsGroup {
// 上文提到的 ControllerChannelManager
var controllerChannelManager = new ControllerChannelManager(controllerContext, config, time, metrics,
stateChangeLogger, threadNamePrefix)
// 上文提到的 ControllerEventManager
private[controller] val eventManager = new ControllerEventManager(config.brokerId, this, time,
controllerContext.stats.rateAndTimeMetrics)
// 监听 /controller 节点变更的。包括节点创建、删除以及数据变更
private val controllerChangeHandler = new ControllerChangeHandler(eventManager)
// 监听 /brokers/ids 下内容的变更,即 Broker 的数量变化
private val brokerChangeHandler = new BrokerChangeHandler(eventManager)
// 监听 /brokers/ids/{id} 的变更,即 Broker 的信息变更,比如配置信息变化
private val brokerModificationsHandlers: mutable.Map[Int, BrokerModificationsHandler] = mutable.Map.empty
// 监控 /brokers/topics 变化,即主题数量变更
private val topicChangeHandler = new TopicChangeHandler(eventManager)
// 监听主题删除节点 /admin/delete_topics 的子节点数量变更
private val topicDeletionHandler = new TopicDeletionHandler(eventManager)
// 监控 /brokers/topics/{topic} 变化,即主题分区数据变更,比如新增加了副本、分区更换了 Leader
private val partitionModificationsHandlers: mutable.Map[String, PartitionModificationsHandler] = mutable.Map.empty
// 监听 /admin/reassign_partitions 变化,即分区副本重分配任务。一旦发现新提交的任务,就为目标分区执行副本重分配
private val partitionReassignmentHandler = new PartitionReassignmentHandler(eventManager)
// 监听 /admin/preferred_replica_election 变化,即是否有 Preferred Leader 选举任务
private val preferredReplicaElectionHandler = new PreferredReplicaElectionHandler(eventManager)
// 监听 /isr_change_notification 变化,即ISR 副本集合变更。一旦触发,就需要获取ISR 发生变更的分区列表,
// 然后更新 Controller 端对应的 Leader 和 ISR 缓存元数据
private val isrChangeNotificationHandler = new IsrChangeNotificationHandler(eventManager)
// 监听 /log_dir_event_notification 变化,即日志路径变更。一旦被触发,需要获取受影响的 Broker 列表,
// 然后处理这些 Broker 上失效的日志路径
private val logDirEventNotificationHandler = new LogDirEventNotificationHandler(eventManager)
......
}在上面的代码中,我们可以找到监听 zk 上 /controller 节点的监听器 ControllerChangeHandler。
那么,这个监听器是何时启动的呢?在 Controller 类的启动方法中,我们可以发现他触发了一个 Startup 事件
注意,在每个 broker 上,都会运行一个 Controller 类实例,来保存元数据并以备竞选,所以都会执行下面的 startup 方法
def startup() = {
......
eventManager.put(Startup)
eventManager.start()
}而跟随着 processor 的 process 方法,我们可以看到这个 Startup 事件是如何处理的:
private def processStartup(): Unit = {
// 调用 zkClient 注册监听器,监听 /controller 节点是否存在
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
// 触发选举操作
elect()
}到这一步,监听器就已经开始工作了
监听器:Controller 无了!
如果监听器发觉 zk 的 /Controller 节点上的内容不存在了,就会调用上面注册的 ControllerChangeHandler 来处理;ControllerChangeHandler 实现了 ZNodeChangeHandler 接口,见名知意,其实就是 zk node change handler,表示监听了 zk 上节点的变动:
trait ZNodeChangeHandler {
val path: String
// 节点创建
def handleCreation(): Unit = {}
// 节点删除
def handleDeletion(): Unit = {}
// 节点数据变更
def handleDataChange(): Unit = {}
}
class ControllerChangeHandler(eventManager: ControllerEventManager) extends ZNodeChangeHandler {
// 对应 zk 上的 path,这里其实就是 "/controller"
override val path: String = ControllerZNode.path
override def handleCreation(): Unit = eventManager.put(ControllerChange)
override def handleDeletion(): Unit = eventManager.put(Reelect)
override def handleDataChange(): Unit = eventManager.put(ControllerChange)
}其中有三个方法,都是调用传入的 ControllerEventManager 的 put 方法,这个方法我们上面已经介绍过了,就是向 eventQueue 中新增一条数据,等待 ControllerEventThread 去消费并分发 event。
在上文提到的 ControllerEventThread 线程的 process 方法中,我们可以找到这两个事件的处理器 processControllerChange() 和 processReelect()
override def process(event: ControllerEvent): Unit = {
try {
event match {
......
case ControllerChange =>
processControllerChange()
case Reelect =>
processReelect()
......
}
} catch {
case e: ControllerMovedException =>
// 这个异常表示竞争选举失败。如果当前节点是老 controller 的话,就要执行卸任操作
info(s"Controller moved to another broker when processing $event.", e)
maybeResign()
case e: Throwable =>
error(s"Error processing event $event", e)
} finally {
updateMetrics()
}
}
......
private def processReelect(): Unit = {
maybeResign()
elect()
}
private def processControllerChange(): Unit = {
maybeResign()
}
对于 Creating 和 DataChange 事件,向事件队列中 put 的都是 ControllerChange 事件,这时候就会尝试执行卸任操作:如果是 Controller 节点,就会清理资源并注销掉跟 Controller 职责相关的监听器;如果是非 Controller 节点,就什么也不做。
而对于 Deletion 事件,则表示 Controller 空缺了,这时候要先做卸任操作(非 Controller 节点什么都不做),然后再去选举
旧 Controller 卸任
maybeResign() 方法就是卸任操作,如果是旧 controller 就要清理相关资源,否则就什么都不用做:
// 更新 ControllerId,如果是当前节点失去了 controller 身份,则清理资源
private def maybeResign(): Unit = {
// 从 KafkaController 对象中拿到 activeControllerId,判断当前节点是否是 Controller
// (判断 activeControllerId == config.brokerId)
val wasActiveBeforeChange = isActive
// 向 zkClient 中注册 handler
//
// 1. 向 zkClient 的 zNodeChangeHandlers map 中增加一项;
// key 是要监听的 path (/controller),value 就是 handler,
// 即就是:告诉 zkClient 要监听 handler.path 的变动, 当有变化时,调用 handler 来处理
// 2. 判断 path 是否存在,如果存在,返回 true,否则返回 false(这里其实没有用到返回值)
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
// 从 zk 查询 /controller 的数据,更新 controllerId
activeControllerId = zkClient.getControllerId.getOrElse(-1)
// 之前是 Controller,但是现在失去 controller 权限,就需要清理资源
if (wasActiveBeforeChange && !isActive) {
// 1. 不再监听 zk 上 controller 相关的 path
// 2. 清理 KafkaController 中的上下文数据
// 3. 停止管理分区、副本的状态
onControllerResignation()
}
}
选举
从上面的介绍中,我们可以知道,elect() 方法有两个触发途径,一是 KafkaServer 启动的时候,会启动 KafkaController,然后会先注册监听器,然后触发选举;二是监听器发现 zk 的 /Controller 节点为空,就会触发 Reelect 事件。
选举的源代码如下:
private def elect(): Unit = {
// 查询 controllerId
activeControllerId = zkClient.getControllerId.getOrElse(-1)
/*
* We can get here during the initial startup and the handleDeleted ZK callback. Because of the potential race condition,
* it's possible that the controller has already been elected when we get here. This check will prevent the following
* createEphemeralPath method from getting into an infinite loop if this broker is already the controller.
*/
// 有两种情况代码会走到这里,1是初始化时,2是 zk 上的 /Controller 被删除时
// 多 broker 的情况下,程序走到这里的时候,controller 可能已经选出来了,就直接退出。
if (activeControllerId != -1) {
debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")
return
}
try {
// 尝试创建 /controller 节点,并写入当前节点的 brokerId
//
// 因为代码没有加锁,所以可能同时有多个 broker 在执行这个方法,
// 但是只有一个节点可以写入成功(zk 提供的原子操作),
// 写入成功的 broker 变为 controller,
// 其他 broker 写入失败会抛出 ControllerMovedException 并结束选举流程
//
// 1. 如果 /controller_epoch 不存在,则创建这个节点,将 epoch 初始化为 0
// 2. 用 zk 提供的原子操作,
// 尝试将 brokerId 写入 /controller, 并将 epoch+1 写入 /controller_epoch
// 3. 如果写入的过程中,发现 controllerId != brokerId 或者 epoch 不对,
// 则说明选举失败,抛出异常终止选举
// 如果写入成功,则说明选举成功
//
val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)
controllerContext.epoch = epoch
controllerContext.epochZkVersion = epochZkVersion
activeControllerId = config.brokerId
info(s"${config.brokerId} successfully elected as the controller. Epoch incremented to ${controllerContext.epoch} " +
s"and epoch zk version is now ${controllerContext.epochZkVersion}")
onControllerFailover()
} catch {
case e: ControllerMovedException =>
// 如果出现了这个异常,说明当前节点竞选失败 (尝试写 /controller 失败)
// 启动辞职流程
maybeResign()
if (activeControllerId != -1)
debug(s"Broker $activeControllerId was elected as controller instead of broker ${config.brokerId}", e)
else
warn("A controller has been elected but just resigned, this will result in another round of election", e)
case t: Throwable =>
error(s"Error while electing or becoming controller on broker ${config.brokerId}. " +
s"Trigger controller movement immediately", t)
// 如果当前节点不是 controller,直接结束
// 如果当前节点是 controller,则
// 1. 将 activeControllerId 设置为 -1
// 2. 调用 onControllerResignation 清理资源
// 3. 删除 /controller 节点
triggerControllerMove()
}
}
核心:抢占式选举
上面这段代码的核心是 registerControllerAndIncrementControllerEpoch 方法。
在看代码之前,我们先看一下 zk 的 stat 命令:
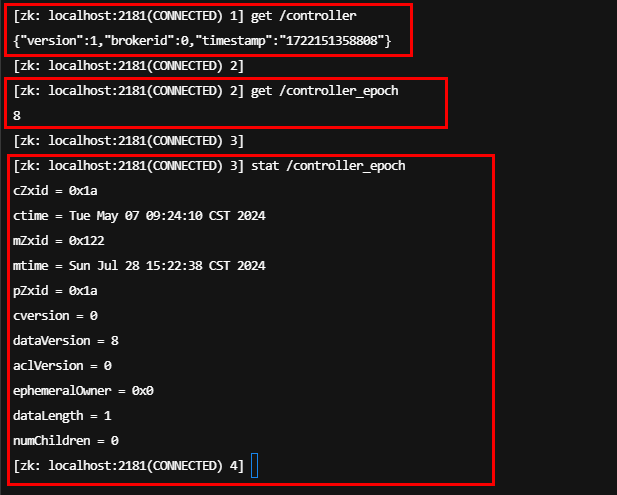
每更新一次 /controller_epoch 的数据,dataVersion 都会增加 1。
/**
* Registers a given broker in zookeeper as the controller and increments controller epoch.
* @param controllerId the id of the broker that is to be registered as the controller.
* @return the (updated controller epoch, epoch zkVersion) tuple
* @throws ControllerMovedException if fail to create /controller or fail to increment controller epoch.
*/
def registerControllerAndIncrementControllerEpoch(controllerId: Int): (Int, Int) = {
val timestamp = time.milliseconds()
// Read /controller_epoch to get the current controller epoch and zkVersion,
// create /controller_epoch with initial value if not exists
//
// 从 /controller_epoch 读数据
val (curEpoch, curEpochZkVersion) = getControllerEpoch
.map(e => (e._1, e._2.getVersion))
// 如果节点不存在,则创建节点,
// 如果创建成功,就会将 epoch 初始化为 0
// 如果创建失败,提示节点已存在,则说明有人抢先了,再读一次数据并返回
.getOrElse(maybeCreateControllerEpochZNode())
// Create /controller and update /controller_epoch atomically
// 版本号+1
val newControllerEpoch = curEpoch + 1
// 当前 zk 的数据版本作为基准
val expectedControllerEpochZkVersion = curEpochZkVersion
debug(s"Try to create ${ControllerZNode.path} and increment controller epoch to $newControllerEpoch with expected controller epoch zkVersion $expectedControllerEpochZkVersion")
def checkControllerAndEpoch(): (Int, Int) = {
val curControllerId = getControllerId.getOrElse(throw new ControllerMovedException(
s"The ephemeral node at ${ControllerZNode.path} went away while checking whether the controller election succeeds. " +
s"Aborting controller startup procedure"))
// 如果 /controller 节点里的 id 就是当前节点的 broker id
// 则说明当前节点时 controller
if (controllerId == curControllerId) {
// 查询 controller epoch
val (epoch, stat) = getControllerEpoch.getOrElse(
throw new IllegalStateException(s"${ControllerEpochZNode.path} existed before but goes away while trying to read it"))
// If the epoch is the same as newControllerEpoch, it is safe to infer that the returned epoch zkVersion
// is associated with the current broker during controller election because we already knew that the zk
// transaction succeeds based on the controller znode verification. Other rounds of controller
// election will result in larger epoch number written in zk.
//
// epoch 也对得上,可以断定返回的 epoch zkVersion 是和当前 broker 相关联的
// 因为之前通过验证 controller 节点(controller znode)已经确认 ZooKeeper 的事务成功了
// 如果有其他 broker 成为 controller(新的选举轮次),它们在 ZooKeeper 中写入的 epoch 一定会比当前的更大
//
// id 对得上,epoch 也对得上,说明选举成功
if (epoch == newControllerEpoch)
return (newControllerEpoch, stat.getVersion)
}
throw new ControllerMovedException("Controller moved to another broker. Aborting controller startup procedure")
}
def tryCreateControllerZNodeAndIncrementEpoch(): (Int, Int) = {
val response = retryRequestUntilConnected(
MultiRequest(Seq(
// 先尝试去创建 /controller 节点,并写入当前 brokerId
CreateOp(ControllerZNode.path, ControllerZNode.encode(controllerId, timestamp), defaultAcls(ControllerZNode.path), CreateMode.EPHEMERAL),
// 然后去更新 /controller_epoch 的值
SetDataOp(ControllerEpochZNode.path, ControllerEpochZNode.encode(newControllerEpoch), expectedControllerEpochZkVersion)))
)
// 对于 multi-request,这里返回的是第一个请求的结果
response.resultCode match {
// 创建 /controller 请求执行失败,说明节点已存在,这里去读取并验证节点里的数据,
// 如果 epoch 和 version 都正确,则说明写入成功了,直接返回
// 如果没有对上,说明当前节点选举失败了,会直接抛出异常,终止逻辑
case Code.NODEEXISTS | Code.BADVERSION => checkControllerAndEpoch()
// 创建请求执行成功
case Code.OK =>
// 找到 set 请求的执行结果
val setDataResult = response.zkOpResults(1).rawOpResult.asInstanceOf[SetDataResult]
// 返回新的 epoch 和 version
(newControllerEpoch, setDataResult.getStat.getVersion)
case code => throw KeeperException.create(code)
}
}
tryCreateControllerZNodeAndIncrementEpoch()
}
抢占成功,初始化
在 eletc() 方法最后一行,选举成功之后,Controller 节点会调用 onControllerFailover 方法,初始化资源,并开始承担作为 Controller 的各种职责:
/**
* This callback is invoked by the zookeeper leader elector on electing the current broker as the new controller.
* It does the following things on the become-controller state change -
* 1. Initializes the controller's context object that holds cache objects for current topics, live brokers and
* leaders for all existing partitions.
* 2. Starts the controller's channel manager
* 3. Starts the replica state machine
* 4. Starts the partition state machine
* If it encounters any unexpected exception/error while becoming controller, it resigns as the current controller.
* This ensures another controller election will be triggered and there will always be an actively serving controller
*
* 这个方法是 broker 选举成功,成为 controller 的时候调用的
* 主要工作是:
* 1. 初始化 controller 的 context 对象,这个对象保存了 topics/live brokers/partition leader 等信息
* 2. 启动用于与其他 broker 交互的 ControllerChannelManager
* 3. 启动 replica 状态机
* 3. 启动 partition 状态机
* 如果过程中发生了未知的异常,就会辞职并重新选举一个 controller,
* 保证总有一个 controller 可用
*/
private def onControllerFailover(): Unit = {
// 2.7 版本引入的新特性,旨在支持集群中功能的版本化管理。
// 这种机制允许 Kafka 在集群层面和单个 broker 层面管理功能的支持范围,
// 并在需要时进行动态调整。它通过 ZooKeeper 存储和管理功能的版本化信息。
maybeSetupFeatureVersioning()
info("Registering handlers")
// before reading source of truth from zookeeper, register the listeners to get broker/topic callbacks
// 注册监听子节点变化的 handler
val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,
isrChangeNotificationHandler)
childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)
// 注册监听节点变化的 handler
val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)
nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)
// 新 controller 诞生,抛弃旧 controller 发出的通知
info("Deleting log dir event notifications")
zkClient.deleteLogDirEventNotifications(controllerContext.epochZkVersion)
info("Deleting isr change notifications")
zkClient.deleteIsrChangeNotifications(controllerContext.epochZkVersion)
// 初始化 controller context 对象,
// 设置集群 context 信息,启动 controllerChannelManager
info("Initializing controller context")
initializeControllerContext()
// 初始化 topicDelete 状态机
info("Fetching topic deletions in progress")
val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()
info("Initializing topic deletion manager")
topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
// We need to send UpdateMetadataRequest after the controller context is initialized and before the state machines
// are started. The is because brokers need to receive the list of live brokers from UpdateMetadataRequest before
// they can process the LeaderAndIsrRequests that are generated by replicaStateMachine.startup() and
// partitionStateMachine.startup().
//
// 先初始化 controller context,再更新 Metadata,然后在启动副本状态机和分区状态机
// 这样其他 brokers 才能知道哪些 brokers 存在,并响应副本状态机和分区状态机的请求。
info("Sending update metadata request")
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set.empty)
replicaStateMachine.startup()
partitionStateMachine.startup()
info(s"Ready to serve as the new controller with epoch $epoch")
// 完成因为选举而挂起的 分区调整(平衡)任务
initializePartitionReassignments()
// 完成因为选举而挂起的 删除 topic 任务
topicDeletionManager.tryTopicDeletion()
// 完成因为选举而挂起的 切换分区 leader 任务
val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()
onReplicaElection(pendingPreferredReplicaElections, ElectionType.PREFERRED, ZkTriggered)
// 启动 scheduler 线程池
info("Starting the controller scheduler")
kafkaScheduler.startup()
if (config.autoLeaderRebalanceEnable) {
scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)
}
if (config.tokenAuthEnabled) {
info("starting the token expiry check scheduler")
tokenCleanScheduler.startup()
tokenCleanScheduler.schedule(name = "delete-expired-tokens",
fun = () => tokenManager.expireTokens(),
period = config.delegationTokenExpiryCheckIntervalMs,
unit = TimeUnit.MILLISECONDS)
}
}