上一篇文章我们学习了三部分内容:
- controller 与 broker 的通信机制
- controller 内部的事件处理机制
- controller 的选举过程
这一节,我们以删除 topic 作为切入点,来学习一下 kafka 中的 Partition State Machine 和 Replica State Machine
一、删除 topic
1、kafka-topics.sh 脚本
kafka 安装目录下会给我们提供一些脚本来管理 kafka,其中就有 topic 的管理工具 kafka-topics.sh,我们可以用下面的命令来删除 topic
kafka-topics.sh --bootstrap-server <kafka-server>:<port> --delete --topic <topic-name>
如果我们打开 kafka-topics.sh 脚本,会发现里面只有一行内容:
exec $(dirname $0)/kafka-run-class.sh kafka.admin.TopicCommand "$@"这行代码的意思是:它获取当前脚本 (kafka-topics.sh) 所在的路径,找到 kafka-run-class.sh,这个脚本会启动一个 JVM 进程,并调用 kafka.admin.TopicCommand 的 main 方法来执行 delete 操作,同时(通过$@)把所有的参数都传递给 main 方法。
接下来我们再看看 TopicCommand 的 main 方法:
object TopicCommand extends Logging {
// 原始命令中的参数都会作为 main 方法的入参
def main(args: Array[String]): Unit = {
// 解析命令行中传入的参数
val opts = new TopicCommandOptions(args)
// 校验参数合法性。如:
// 入参不能为空,必须是 createOpt, listOpt, alterOpt, describeOpt, deleteOpt 中的一种、
// 必须指明 --bootstrap-server 或者 --zookeeper 等
opts.checkArgs()
// 早期 topic 的管理请求是去更新 zk 上的数据,
// 后期 topic 的管理请求可以用 AdminClient 直接向 Controller 发请求
//
// 我理解,后期 kafka 在逐渐减少对 zk 的依赖,所以这里把管理请求交给
// controller 去处理,更符合整体架构的演进方向。
val topicService = if (opts.zkConnect.isDefined)
// 如果指明 --zookeeper ,则向 zk 发请求
ZookeeperTopicService(opts.zkConnect)
else {
// 如果指明的是 --bootstrap-server 则使用 AdminClient 向 Controller 发请求
AdminClientTopicService(opts.commandConfig, opts.bootstrapServer)
}
// 只支持下面五种操作
var exitCode = 0
try {
if (opts.hasCreateOption)
topicService.createTopic(opts)
else if (opts.hasAlterOption)
topicService.alterTopic(opts)
else if (opts.hasListOption)
topicService.listTopics(opts)
else if (opts.hasDescribeOption)
topicService.describeTopic(opts)
else if (opts.hasDeleteOption)
topicService.deleteTopic(opts)
} catch {
......
} finally {
topicService.close()
Exit.exit(exitCode)
}
......
}上面的 topicService.deleteTopic(opts) ,最终会使用 ApiKeys.DELETE_TOPICS 这个 apikey,将请求发送给集群的 controller 节点,,我们可以从 Kafka源码·四 - KafkaRequestHandler 这一节找到这个 apikey,以及对应的处理器:handleDeleteTopicsRequest(request) :
def handleDeleteTopicsRequest(request: RequestChannel.Request): Unit = {
......
val deleteTopicRequest = request.body[DeleteTopicsRequest]
val results = new DeletableTopicResultCollection(deleteTopicRequest.data.topicNames.size)
val toDelete = mutable.Set[String]()
if (!controller.isActive) {
// 只有 controller 才能履行删除职责,否则会返回 NOT_CONTROLLER 错误
deleteTopicRequest.data.topicNames.forEach { topic =>
results.add(new DeletableTopicResult()
.setName(topic)
.setErrorCode(Errors.NOT_CONTROLLER.code))
}
sendResponseCallback(results)
} else if (!config.deleteTopicEnable) {
// 配置文件中,如果配置了不允许删除 topic,则返回错误
val error = if (request.context.apiVersion < 3) Errors.INVALID_REQUEST else Errors.TOPIC_DELETION_DISABLED
deleteTopicRequest.data.topicNames.forEach { topic =>
results.add(new DeletableTopicResult()
.setName(topic)
.setErrorCode(error.code))
}
sendResponseCallback(results)
} else {
// 可以删除,开始删除
deleteTopicRequest.data.topicNames.forEach { topic =>
results.add(new DeletableTopicResult()
.setName(topic))
}
// 判断请求方是否有删除 topic 的权限
val authorizedTopics = filterByAuthorized(request.context, DELETE, TOPIC,
results.asScala)(_.name)
results.forEach { topic =>
if (!authorizedTopics.contains(topic.name))
topic.setErrorCode(Errors.TOPIC_AUTHORIZATION_FAILED.code)
else if (!metadataCache.contains(topic.name))
topic.setErrorCode(Errors.UNKNOWN_TOPIC_OR_PARTITION.code)
else
toDelete += topic.name
}
// 无删除权限,直接退出
if (toDelete.isEmpty)
sendResponseCallback(results)
else {
// 定义回调函数,用来响应 response
def handleDeleteTopicsResults(errors: Map[String, Errors]): Unit = {
errors.foreach {
case (topicName, error) =>
results.find(topicName)
.setErrorCode(error.code)
}
sendResponseCallback(results)
}
// 删除操作:
// 这里实际上是去给 zk 的 /admin/delete_topics/ 节点下新增一个节点,
// 节点名就是待删除的 topic name
// 后续 zk 监听器会监听到这个变动,然后再触发后续的删除操作,删除结束后,通过
// handleDeleteTopicsResults 来响应 response 给请求方
adminManager.deleteTopics(
deleteTopicRequest.data.timeoutMs,
toDelete,
controllerMutationQuota,
handleDeleteTopicsResults
)
}
}
}
在 Kafka源码·五 - Controller(一) 这一节中,我们知道,controller 选举成功的时候,会注册各种 zk 监听器,其中就包括用来监听待删除 topic 的 TopicDeletionHandler 监听器:
class TopicDeletionHandler(eventManager: ControllerEventManager) extends ZNodeChildChangeHandler {
// 监听 /admin/delete_topics/
override val path: String = TopicsZNode.path
// 监听到子节点变化之后,向队列中放入一个 TopicDeletion 事件
override def handleChildChange(): Unit = eventManager.put(TopicDeletion)
}同样,在这一篇文章中,我们可以看到 controller 是如何处理这个 TopicDeletion 事件的:
private def processTopicDeletion(): Unit = {
if (!isActive) return
// 查询 /admin/delete_topics/ 下的子节点 (节点名称就是待删除的 topic name)
var topicsToBeDeleted = zkClient.getTopicDeletions.toSet
debug(s"Delete topics listener fired for topics ${topicsToBeDeleted.mkString(",")} to be deleted")
// 如果 topic 不存在,则直接删除 /admin/delete_topics/ 下对应的节点即可
val nonExistentTopics = topicsToBeDeleted -- controllerContext.allTopics
if (nonExistentTopics.nonEmpty) {
warn(s"Ignoring request to delete non-existing topics ${nonExistentTopics.mkString(",")}")
zkClient.deleteTopicDeletions(nonExistentTopics.toSeq, controllerContext.epochZkVersion)
}
// 排除掉实际不存在的 topic
topicsToBeDeleted --= nonExistentTopics
if (config.deleteTopicEnable) {
if (topicsToBeDeleted.nonEmpty) {
info(s"Starting topic deletion for topics ${topicsToBeDeleted.mkString(",")}")
// mark topic ineligible for deletion if other state changes are in progress
// 如果此时 topic 有分区迁移的任务尚未完成,则标记为不满足删除条件(ineligible for deletion)
// 并记录到 ctx 中,后续删除的时候会跳过
topicsToBeDeleted.foreach { topic =>
val partitionReassignmentInProgress =
controllerContext.partitionsBeingReassigned.map(_.topic).contains(topic)
if (partitionReassignmentInProgress)
topicDeletionManager.markTopicIneligibleForDeletion(Set(topic),
reason = "topic reassignment in progress")
}
// 先添加到 controller ctx 的 topicsToBeDeleted map 中,
// 然后调用 TopicDeletionManager.resumeDeletions() 激活删除任务
topicDeletionManager.enqueueTopicsForDeletion(topicsToBeDeleted)
}
} else {
// 如果没有启用 “删除 topic” 功能,则清空 /admin/delete_topics 下的内容
info(s"Removing $topicsToBeDeleted since delete topic is disabled")
zkClient.deleteTopicDeletions(topicsToBeDeleted.toSeq, controllerContext.epochZkVersion)
}
}2、TopicDeletionManager 类的定义及初始化
TopicDeletionManager 顾名思义就是负责删除 topic 的,下面是它的定义:
class TopicDeletionManager(config: KafkaConfig,
controllerContext: ControllerContext,
// 副本状态机;要删除 topic 就得先删除 partition,要删除 paitition,就得先删除 replica
// 同时就要更新这个状态机。
replicaStateMachine: ReplicaStateMachine,
// 分区状态机
partitionStateMachine: PartitionStateMachine,
// 与 zk 交互的客户端,用于删除 zk 上指定的资源
client: DeletionClient) extends Logging {
// 是否允许删除 topic
val isDeleteTopicEnabled: Boolean = config.deleteTopicEnable
// 每个 broker 都会创建 controller 对象,但只有选举成功成为新 controller 的时候,才会履行职责。
// TopicDeletionManager 在 controller 创建的时候被创建并注入;
//
// 而在当前 broker 成为新 controller 的时候,才会调用这个 init 方法,
// 查找是否有因为选举而被挂起的删除任务,并将其重新放入任务队列
//
// initialTopicsToBeDeleted:
// 选举成功之后,controller 查询 /admin/delete_topics 下的 topic_name 列表,获取所有待删除的 topic
// initialTopicsIneligibleForDeletion:
// 上述 topic 列表中,有 topic 正在执行 partition reassignment 或者
// 持有 topic 某个 replica 的 broker 宕机了
//
def init(initialTopicsToBeDeleted: Set[String], initialTopicsIneligibleForDeletion: Set[String]): Unit = {
info(s"Initializing manager with initial deletions: $initialTopicsToBeDeleted, " +
s"initial ineligible deletions: $initialTopicsIneligibleForDeletion")
if (isDeleteTopicEnabled) {
// append 到 ctx 的 topicsToBeDeleted 列表中
controllerContext.queueTopicDeletion(initialTopicsToBeDeleted)
// 确保 append 到 topicsIneligibleForDeletion 中的 topic 是
// 应该删除 但 不能立刻删除 的
controllerContext.topicsIneligibleForDeletion ++= initialTopicsIneligibleForDeletion & controllerContext.topicsToBeDeleted
} else {
// if delete topic is disabled clean the topic entries under /admin/delete_topics
// 如果没有开启删除 topic 功能,则删除 /admin/delete_topics/{topic} 下的内容
client.deleteTopicDeletions(initialTopicsToBeDeleted.toSeq, controllerContext.epochZkVersion)
}
}
// 在上一篇文章的 onControllerFailover() 方法中,新 controller 选举成功时,
// 会先调用上面的 init 方法,将待删除 topic 放入 topicsToBeDeleted 队列中
// 然后再调用这个方法激活删除操作
def tryTopicDeletion(): Unit = {
if (isDeleteTopicEnabled) {
resumeDeletions()
}
}
......
}
继续看 resumeDeletions() 是如何实现的:
private def resumeDeletions(): Unit = {
// 拷贝一份待删除 topic 列表
val topicsQueuedForDeletion = Set.empty[String] ++ controllerContext.topicsToBeDeleted
val topicsEligibleForRetry = mutable.Set.empty[String]
val topicsEligibleForDeletion = mutable.Set.empty[String]
if (topicsQueuedForDeletion.nonEmpty)
info(s"Handling deletion for topics ${topicsQueuedForDeletion.mkString(",")}")
// 逐个检查 topic 及其 replica 所处的状态,
// 判断 是否可以删除,是否需要重试
topicsQueuedForDeletion.foreach { topic =>
// 如果所有的 replica 都被标记为 删除成功,就认为 topic 删除完成
if (controllerContext.areAllReplicasInState(topic, ReplicaDeletionSuccessful)) {
// 所有的 replica 都已经流转到 ReplicaDeletionSuccessful 状态了,
// 这时候再将 replica 全部设置为 NonExistentReplica
// 然后就可以删除 zk 上该 topic 相关的所有节点了,以及 ctx 中 topic 相关的所有数据
completeDeleteTopic(topic)
info(s"Deletion of topic $topic successfully completed")
} else if (!controllerContext.isAnyReplicaInState(topic, ReplicaDeletionStarted)) {
// 相当于 controllerContext.noReplicaInState(topic, ReplicaDeletionStarted))
// if you come here, then no replica is in TopicDeletionStarted and all replicas are not in
// TopicDeletionSuccessful. That means, that either given topic haven't initiated deletion
// or there is at least one failed replica (which means topic deletion should be retried).
//
// 到这里,
// 所有的 replica 都不在 ReplicaDeletionStarted 状态,
// 并且存在 replica 不在 ReplicaDeletionSuccessful 状态,
// 有两种可能,
// 一是这个 topic 可能还没有初始化删除任务,
// 二是有部分 replica 删除失败了,处于 Ineligible to delete 状态,
// 这时候就需要重试删除任务
if (controllerContext.isAnyReplicaInState(topic, ReplicaDeletionIneligible)) {
topicsEligibleForRetry += topic
}
}
// Add topic to the eligible set if it is eligible for deletion.
//
// 下列条件都满足时,可以删除 topic
// 1. topicsToBeDeleted 中包含 topic
// 2. replica 都不处于 ReplicaDeletionStarted 状态(started 表示已经处于删除进程中了)
// 3. topicsIneligibleForDeletion 中不包含 topic
if (isTopicEligibleForDeletion(topic)) {
info(s"Deletion of topic $topic (re)started")
topicsEligibleForDeletion += topic
}
}
// 将 ReplicaDeletionIneligible 状态的 replica,设置为 OfflineReplica
// 以备后续删除
if (topicsEligibleForRetry.nonEmpty) {
retryDeletionForIneligibleReplicas(topicsEligibleForRetry)
}
// 执行 topic deletion
if (topicsEligibleForDeletion.nonEmpty) {
onTopicDeletion(topicsEligibleForDeletion)
}
}主要都还是一些状态的校验,最后一段的 onTopicDeletion(topicsEligibleForDeletion) 才是更新 Partition State Machine 的地方
二、分区状态机
在上一篇文章中,我们了解到当 controller 选举成功之后,就会调用 stateMachine 的 startup 方法,来启动状态机
private def onControllerFailover(): Unit = {
......
replicaStateMachine.startup()
partitionStateMachine.startup()
......
}1、PartitionStateMachine.startup()
下面是 PartitionStateMachine 类的定义以及 startup 方法:
abstract class PartitionStateMachine(controllerContext: ControllerContext) extends Logging {
/**
* Invoked on successful controller election.
*/
def startup(): Unit = {
// 为 ctx 中所有的 partition 都指定初始状态
info("Initializing partition state")
initializePartitionState()
// 让处于 NewPartition 和 OfflinePartition 状态的分区流转起来
info("Triggering online partition state changes")
triggerOnlinePartitionStateChange()
debug(s"Started partition state machine with initial state -> ${controllerContext.partitionStates}")
}
/**
* 启动 partition state machine 的时候,为 zk 上所有的分区设置初始状态
*/
private def initializePartitionState(): Unit = {
// 为 ctx 中所有的 partition 都指定初始状态
for (topicPartition <- controllerContext.allPartitions) {
// check if leader and isr path exists for partition. If not, then it is in NEW state
//
// Controller 为 partition 选出了 leader 之后,会先将 LeaderAndIsr 信息保存在
// zk 的 /brokers/topics/[topic]/partitions/[partition]/state 路径上
// 再将 LeaderAndIsr 信息保存到 ctx 的 partitionLeadershipInfo 中
//
// 这里去 ctx 的 partitionLeadershipInfo 中查找 partition 的 leader
// 如果没找到,说明这个 partition 处于 NewPartition 状态
controllerContext.partitionLeadershipInfo(topicPartition) match {
case Some(currentLeaderIsrAndEpoch) =>
// else, check if the leader for partition is alive. If yes, it is in Online state, else it is in Offline state
// 如果 broker 存活,则将 partition 置为 OnlinePartition 状态,否则置为 OfflinePartition
if (controllerContext.isReplicaOnline(currentLeaderIsrAndEpoch.leaderAndIsr.leader, topicPartition))
controllerContext.putPartitionState(topicPartition, OnlinePartition)
else
controllerContext.putPartitionState(topicPartition, OfflinePartition)
case None =>
controllerContext.putPartitionState(topicPartition, NewPartition)
}
}
}
def triggerOnlinePartitionStateChange(): Unit = {
val partitions = controllerContext.partitionsInStates(Set(OfflinePartition, NewPartition))
triggerOnlineStateChangeForPartitions(partitions)
}
private def triggerOnlineStateChangeForPartitions(partitions: collection.Set[TopicPartition]): Unit = {
// try to move all partitions in NewPartition or OfflinePartition state to OnlinePartition state except partitions
// that belong to topics to be deleted
//
// 除了待删除 topic 的 partition,将其他所有处于 NewPartition 或 OfflinePartition
// 状态的 partition 置为 OnlinePartition 状态
val partitionsToTrigger = partitions.filter { partition =>
!controllerContext.isTopicQueuedUpForDeletion(partition.topic)
}.toSeq
handleStateChanges(partitionsToTrigger, OnlinePartition, Some(OfflinePartitionLeaderElectionStrategy(false)))
}注意这里最后一段代码中,有一个 OfflinePartitionLeaderElectionStrategy,它属于分区选举策略的一种,不同的场景下,策略会有所不同,这里先简单看一下,后文再做详细探讨:
sealed trait PartitionLeaderElectionStrategy
// 因为 Leader 副本下线而引发的分区 Leader 选举
final case class OfflinePartitionLeaderElectionStrategy(allowUnclean: Boolean) extends PartitionLeaderElectionStrategy
// 因为执行分区副本重分配操作而引发的分区 Leader 选举
final case object ReassignPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// 因为执行 Preferred 副本 Leader选举而引发的分区 Leader 选举
final case object PreferredReplicaPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// 因为正常关闭 Broker 而引发的分区 Leader 选举
final case object ControlledShutdownPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
2、状态机流转
从 PartitionStateMachine 类的签名中可以看到,它是一个抽象类,它有两个子类,一个叫 MockPartitionStateMachine,看名字就知道是测试用的。另一个就是真正干活的 ZkPartitionStateMachine,我们这里直接去看它是如何实现 handleStateChanges() 方法的:
class ZkPartitionStateMachine(config: KafkaConfig,
stateChangeLogger: StateChangeLogger,
controllerContext: ControllerContext,
zkClient: KafkaZkClient,
controllerBrokerRequestBatch: ControllerBrokerRequestBatch)
extends PartitionStateMachine(controllerContext) {
private val controllerId = config.brokerId
this.logIdent = s"[PartitionStateMachine controllerId=$controllerId] "
/**
* 尝试将分区的状态设置为 targetState, 如果过程中需要重新为分区选举 leader,则
* 使用传入的 partitionLeaderElectionStrategyOpt 策略
*/
override def handleStateChanges(
partitions: Seq[TopicPartition],
targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy]
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]] = {
if (partitions.nonEmpty) {
try {
// 确保缓存中没有未发送的请求,如果有的话会抛出异常
controllerBrokerRequestBatch.newBatch()
// 执行状态转换
// 状态转换过程中,如果有以下三类请求需要发送,
// 1. LeaderAndIsr
// 2. UpdateMetadata
// 3. StopReplica
// 会先暂存起来,然后通过下文的 sendRequestsToBrokers 方法发送给其他 broker
val result = doHandleStateChanges(
partitions,
targetState,
partitionLeaderElectionStrategyOpt
)
// 将上文暂存的请求发送给 broker
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
result
} catch {
case e: ControllerMovedException =>
// 不再是 controller 了,无权更新状态机
error(s"Controller moved to another broker when moving some partitions to $targetState state", e)
throw e
case e: Throwable =>
......
}
} else {
Map.empty
}
}
源码中,为 PartitionState 定义了四种状态,并限制了流转过程中的 previous state:
sealed trait PartitionState {
......
def validPreviousStates: Set[PartitionState]
}
case object NewPartition extends PartitionState {
......
val validPreviousStates: Set[PartitionState] = Set(NonExistentPartition)
}
case object OnlinePartition extends PartitionState {
......
val validPreviousStates: Set[PartitionState] = Set(NewPartition, OnlinePartition, OfflinePartition)
}
case object OfflinePartition extends PartitionState {
......
val validPreviousStates: Set[PartitionState] = Set(NewPartition, OnlinePartition, OfflinePartition)
}
case object NonExistentPartition extends PartitionState {
......
val validPreviousStates: Set[PartitionState] = Set(OfflinePartition)
}他们之间的流转关系如下图所示:
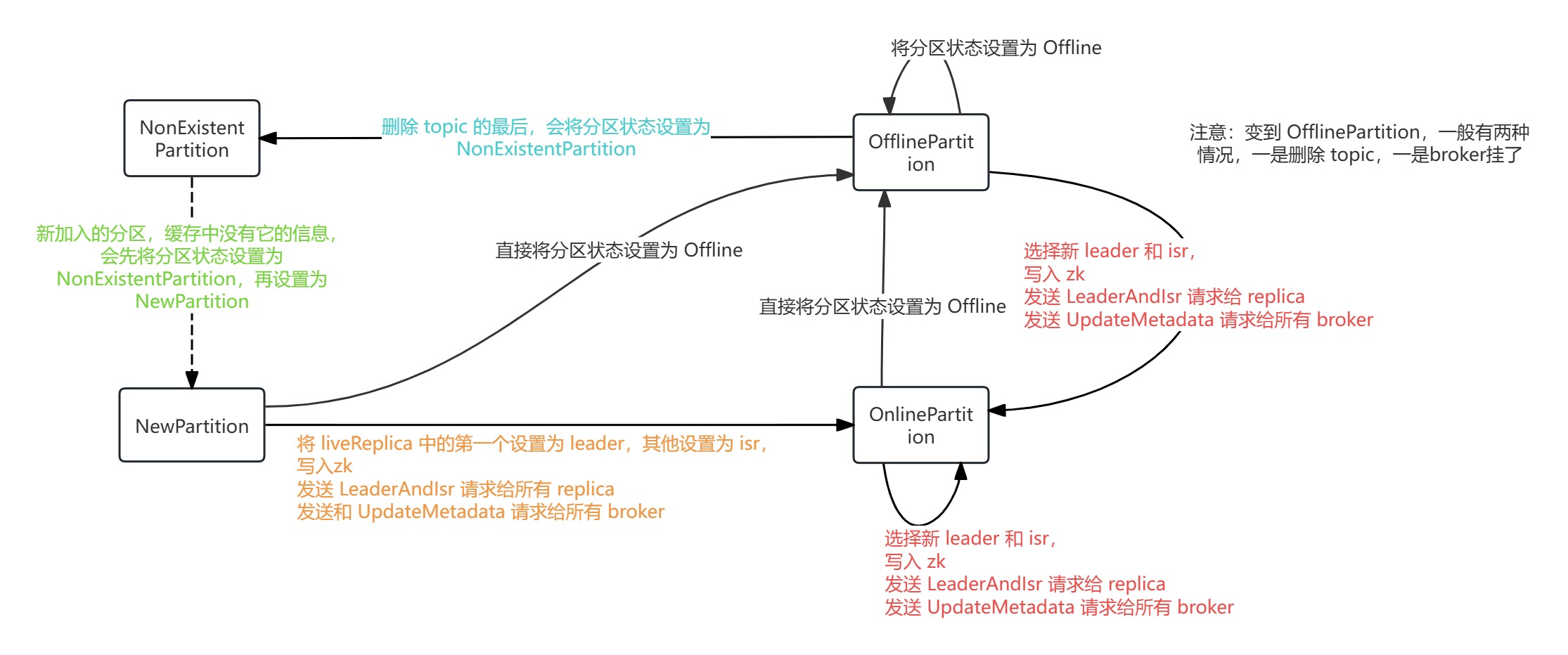
参照这张图,我们再来看 doHandleStateChanges() 的具体实现:
private def doHandleStateChanges(
partitions: Seq[TopicPartition],
targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy]
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]] = {
val stateChangeLog = stateChangeLogger.withControllerEpoch(controllerContext.epoch)
val traceEnabled = stateChangeLog.isTraceEnabled
// 新分区的状态初始化为 NonExistentPartition
partitions.foreach(partition => controllerContext.putPartitionStateIfNotExists(partition, NonExistentPartition))
// 状态机之间有严格的流转关系,这里过略掉非法的状态流转
val (validPartitions, invalidPartitions) = controllerContext.checkValidPartitionStateChange(partitions, targetState)
invalidPartitions.foreach(partition => logInvalidTransition(partition, targetState))
targetState match {
case NewPartition =>
validPartitions.foreach { partition =>
stateChangeLog.info(s"Changed partition $partition state from ${partitionState(partition)} to $targetState with " +
s"assigned replicas ${controllerContext.partitionReplicaAssignment(partition).mkString(",")}")
// 直接设置为 NewPartition
controllerContext.putPartitionState(partition, NewPartition)
}
Map.empty
case OnlinePartition =>
// 从 ctx 中找出状态是 NewPartition 的分区
val uninitializedPartitions = validPartitions.filter(partition => partitionState(partition) == NewPartition)
// 从 ctx 中找出状态是 OnlinePartition 或 OfflinePartition 的分区
val partitionsToElectLeader = validPartitions.filter(partition => partitionState(partition) == OfflinePartition || partitionState(partition) == OnlinePartition)
if (uninitializedPartitions.nonEmpty) {
// 新创建的分区,在 zk 的 /brokers/topics/<topic>/partitions/<partition>
// 目录下写入 leader 和 isr 信息
val successfulInitializations = initializeLeaderAndIsrForPartitions(uninitializedPartitions)
successfulInitializations.foreach { partition =>
stateChangeLog.info(s"Changed partition $partition from ${partitionState(partition)} to $targetState with state " +
s"${controllerContext.partitionLeadershipInfo(partition).get.leaderAndIsr}")
// 写入成功,更新状态为 OnlinePartition
controllerContext.putPartitionState(partition, OnlinePartition)
}
}
// 从上文 partitionsToElectLeader 的来源可知,这一步有两种可能:
// 1. 从 OfflinePartition 到 OnlinePartition
// 2. 从 OnlinePartition 到 OnlinePartition
if (partitionsToElectLeader.nonEmpty) {
val electionResults = electLeaderForPartitions(
partitionsToElectLeader,
partitionLeaderElectionStrategyOpt.getOrElse(
throw new IllegalArgumentException("Election strategy is a required field when the target state is OnlinePartition")
)
)
// 选举成功,更新 ctx 信息,记录日志
electionResults.foreach {
case (partition, Right(leaderAndIsr)) =>
stateChangeLog.info(
s"Changed partition $partition from ${partitionState(partition)} to $targetState with state $leaderAndIsr"
)
controllerContext.putPartitionState(partition, OnlinePartition)
case (_, Left(_)) => // Ignore; no need to update partition state on election error
}
electionResults
} else {
Map.empty
}
case OfflinePartition =>
// 直接更新 ctx
validPartitions.foreach { partition =>
if (traceEnabled)
stateChangeLog.trace(s"Changed partition $partition state from ${partitionState(partition)} to $targetState")
controllerContext.putPartitionState(partition, OfflinePartition)
}
Map.empty
case NonExistentPartition =>
// 直接更新 ctx
validPartitions.foreach { partition =>
if (traceEnabled)
stateChangeLog.trace(s"Changed partition $partition state from ${partitionState(partition)} to $targetState")
controllerContext.putPartitionState(partition, NonExistentPartition)
}
Map.empty
}
}
3、 创建新分区
private def initializeLeaderAndIsrForPartitions(partitions: Seq[TopicPartition]): Seq[TopicPartition] = {
val successfulInitializations = mutable.Buffer.empty[TopicPartition]
// 找到 replica
val replicasPerPartition = partitions.map(partition => partition -> controllerContext.partitionReplicaAssignment(partition))
// 找到存活的 replica
val liveReplicasPerPartition = replicasPerPartition.map { case (partition, replicas) =>
val liveReplicasForPartition = replicas.filter(replica => controllerContext.isReplicaOnline(replica, partition))
partition -> liveReplicasForPartition
}
val (partitionsWithoutLiveReplicas, partitionsWithLiveReplicas) = liveReplicasPerPartition.partition { case (_, liveReplicas) => liveReplicas.isEmpty }
// 对于 replica 全挂的分区,记录日志
partitionsWithoutLiveReplicas.foreach { case (partition, replicas) =>
val failMsg = s"Controller $controllerId epoch ${controllerContext.epoch} encountered error during state change of " +
s"partition $partition from New to Online, assigned replicas are " +
s"[${replicas.mkString(",")}], live brokers are [${controllerContext.liveBrokerIds}]. No assigned " +
"replica is alive."
logFailedStateChange(partition, NewPartition, OnlinePartition, new StateChangeFailedException(failMsg))
}
// 对于有 replica 存活的分区
val leaderIsrAndControllerEpochs = partitionsWithLiveReplicas.map { case (partition, liveReplicas) =>
// 将 liveReplicas 中第一个设置为 leader,其他的设置为 isr
val leaderAndIsr = LeaderAndIsr(liveReplicas.head, liveReplicas.toList)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
partition -> leaderIsrAndControllerEpoch
}.toMap
val createResponses = try {
// 在 zk 上创建目录 /brokers/topics/<topic>/partitions
// 在 zk 上创建节点 /brokers/topics/<topic>/partitions/<partition>
zkClient.createTopicPartitionStatesRaw(leaderIsrAndControllerEpochs, controllerContext.epochZkVersion)
} catch {
case e: ControllerMovedException =>
error("Controller moved to another broker when trying to create the topic partition state znode", e)
throw e
case e: Exception =>
partitionsWithLiveReplicas.foreach { case (partition, _) => logFailedStateChange(partition, partitionState(partition), NewPartition, e) }
Seq.empty
}
createResponses.foreach { createResponse =>
val code = createResponse.resultCode
val partition = createResponse.ctx.get.asInstanceOf[TopicPartition]
val leaderIsrAndControllerEpoch = leaderIsrAndControllerEpochs(partition)
if (code == Code.OK) {
// 在 zk 上创建成功,更新 ctx 中的 leaderAndIsr 信息
controllerContext.putPartitionLeadershipInfo(partition, leaderIsrAndControllerEpoch)
// 向 isr 中的成员发送 leaderAndIsr 请求,follower 会开始从 leader 拉取数据
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(leaderIsrAndControllerEpoch.leaderAndIsr.isr,
partition, leaderIsrAndControllerEpoch, controllerContext.partitionFullReplicaAssignment(partition), isNew = true)
// 记录成功完成初始化的分区
successfulInitializations += partition
} else {
logFailedStateChange(partition, NewPartition, OnlinePartition, code)
}
}
// 返回成功完成初始化的分区
successfulInitializations
}4、 分区选举
调整分区的时候,如果目标状态是 OnlinePartition,原始状态是 OnlinePartition (比如说更新了 LeaderAndIsr) 或者 OfflinePartition(比如说挂了的分区重新上线),则可能需要重新为分区选举 leader:
/**
* Repeatedly attempt to elect leaders for multiple partitions until there are no more remaining partitions to retry.
*
* 不断尝试为传入的多个分区选举,直到所有分区都成功选出 leader
*
* @param partitions The partitions that we're trying to elect leaders for.
* @param partitionLeaderElectionStrategy The election strategy to use.
* @return A map of failed and successful elections. The keys are the topic partitions and the corresponding values are
* either the exception that was thrown or new leader & ISR.
*/
private def electLeaderForPartitions(
partitions: Seq[TopicPartition],
partitionLeaderElectionStrategy: PartitionLeaderElectionStrategy
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]] = {
var remaining = partitions
val finishedElections = mutable.Map.empty[TopicPartition, Either[Throwable, LeaderAndIsr]]
while (remaining.nonEmpty) {
val (finished, updatesToRetry) = doElectLeaderForPartitions(remaining, partitionLeaderElectionStrategy)
// updatesToRetry 指成功选出了 leader,但是更新 zk 失败的分区
remaining = updatesToRetry
// finished 中包含两部分,
// 一是成功选举且更新 zk 成功的分区,
// 二是找不到可用 replica 而导致选举失败的(这又分为两种情况,要么是 replcia 都挂了, 要么是 isr 中的 replica 都挂了且不支持 unclean 选举)
// 这种情况下就没有重试的必要了,等到有 replica 可用的时候,会重新触发选举的。
finished.foreach {
case (partition, Left(e)) =>
logFailedStateChange(partition, partitionState(partition), OnlinePartition, e)
case (_, Right(_)) => // Ignore; success so no need to log failed state change
}
finishedElections ++= finished
if (remaining.nonEmpty)
logger.info(s"Retrying leader election with strategy $partitionLeaderElectionStrategy for partitions $remaining")
}
finishedElections.toMap
}
具体的选举操作如下:
private def doElectLeaderForPartitions(
partitions: Seq[TopicPartition],
partitionLeaderElectionStrategy: PartitionLeaderElectionStrategy
): (Map[TopicPartition, Either[Exception, LeaderAndIsr]], Seq[TopicPartition]) = {
// 从 zk 的 /brokers/topics/<topic>/partitions/<partition>/state
// 节点查询分区信息
val getDataResponses = try {
zkClient.getTopicPartitionStatesRaw(partitions)
} catch {
case e: Exception =>
return (partitions.iterator.map(_ -> Left(e)).toMap, Seq.empty)
}
val failedElections = mutable.Map.empty[TopicPartition, Either[Exception, LeaderAndIsr]]
val validLeaderAndIsrs = mutable.Buffer.empty[(TopicPartition, LeaderAndIsr)]
getDataResponses.foreach { getDataResponse =>
val partition = getDataResponse.ctx.get.asInstanceOf[TopicPartition]
// 查询 ctx 中当前的分区状态
val currState = partitionState(partition)
if (getDataResponse.resultCode == Code.OK) {
TopicPartitionStateZNode.decode(getDataResponse.data, getDataResponse.stat) match {
case Some(leaderIsrAndControllerEpoch) =>
if (leaderIsrAndControllerEpoch.controllerEpoch > controllerContext.epoch) {
// 说明当前的 controller 已经被夺权了
val failMsg = s"Aborted leader election for partition $partition since the LeaderAndIsr path was " +
s"already written by another controller. This probably means that the current controller $controllerId went through " +
s"a soft failure and another controller was elected with epoch ${leaderIsrAndControllerEpoch.controllerEpoch}."
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
} else {
// 将 zk 上真实有效的 leaderAndIsr 信息存起来,以备后续使用
validLeaderAndIsrs += partition -> leaderIsrAndControllerEpoch.leaderAndIsr
}
case None =>
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
failedElections.put(partition, Left(exception))
}
} else if (getDataResponse.resultCode == Code.NONODE) {
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
failedElections.put(partition, Left(exception))
} else {
failedElections.put(partition, Left(getDataResponse.resultException.get))
}
}
// zk 上找不到对应的节点,直接退出
if (validLeaderAndIsrs.isEmpty) {
return (failedElections.toMap, Seq.empty)
}
// 选举
val (partitionsWithoutLeaders, partitionsWithLeaders) = partitionLeaderElectionStrategy match {
case OfflinePartitionLeaderElectionStrategy(allowUnclean) =>
// 因为 Leader 副本下线而引发的分区 Leader 选举
// 找出待选举的分区信息,以及他们是否支持 unclean leader election
// 1. 检查副本状态:根据每个分区的ISR检查是否有在线副本。
// 2. 判断是否允许不健康选举:
// 如果配置允许不健康选举(allowUnclean为true),直接返回允许选举。
// 如果配置不允许,查询 zk 获取该主题的独立配置,判断是否允许不健康选举。
// 3. 返回结果:最终返回每个分区的 isr 以及是否允许 unclean 选举
val partitionsWithUncleanLeaderElectionState = collectUncleanLeaderElectionState(
validLeaderAndIsrs,
allowUnclean
)
// 选出新 leader,返回新的 leaderAndIsr 信息
leaderForOffline(controllerContext, partitionsWithUncleanLeaderElectionState).partition(_.leaderAndIsr.isEmpty)
case ReassignPartitionLeaderElectionStrategy =>
// 因为执行分区副本重分配操作而引发的分区 Leader 选举
leaderForReassign(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
case PreferredReplicaPartitionLeaderElectionStrategy =>
// 因为执行 Preferred 副本 Leader选举而引发的分区 Leader 选举
leaderForPreferredReplica(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
case ControlledShutdownPartitionLeaderElectionStrategy =>
// 因为正常关闭 Broker 而引发的分区 Leader 选举
leaderForControlledShutdown(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
}
// 记录没有选举成功的 partition
partitionsWithoutLeaders.foreach { electionResult =>
val partition = electionResult.topicPartition
val failMsg = s"Failed to elect leader for partition $partition under strategy $partitionLeaderElectionStrategy"
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
}
val recipientsPerPartition = partitionsWithLeaders.map(result => result.topicPartition -> result.liveReplicas).toMap
val adjustedLeaderAndIsrs = partitionsWithLeaders.map(result => result.topicPartition -> result.leaderAndIsr.get).toMap
// 更新 zk 上的 LeaderAndIsr 信息
val UpdateLeaderAndIsrResult(finishedUpdates, updatesToRetry) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs, controllerContext.epoch, controllerContext.epochZkVersion)
// 若更新 zk 成功,则更新本地 ctx 中的信息,并通知分区 replica 所在的 broker
finishedUpdates.forKeyValue { (partition, result) =>
result.foreach { leaderAndIsr =>
val replicaAssignment = controllerContext.partitionFullReplicaAssignment(partition)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
// 则更新本地 ctx 中的信息
controllerContext.putPartitionLeadershipInfo(partition, leaderIsrAndControllerEpoch)
// 通知分区 replica 所在的 broker, 告诉他们去向新的 leader 拉取数据
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipientsPerPartition(partition), partition,
leaderIsrAndControllerEpoch, replicaAssignment, isNew = false)
}
}
if (isDebugEnabled) {
updatesToRetry.foreach { partition =>
debug(s"Controller failed to elect leader for partition $partition. " +
s"Attempted to write state ${adjustedLeaderAndIsrs(partition)}, but failed with bad ZK version. This will be retried.")
}
}
(finishedUpdates ++ failedElections, updatesToRetry)
}a. collectUncleanLeaderElectionState
/* For the provided set of topic partition and partition sync state it attempts to determine if unclean
* leader election should be performed. Unclean election should be performed if there are no live
* replica which are in sync and unclean leader election is allowed (allowUnclean parameter is true or
* the topic has been configured to allow unclean election).
*
* 根据传入的 partition 及其 leaderAndIsr,判断是否允许 unclean leader election。
*
* unclean leader election 是指在 isr 列表为空的情况下, Kafka 选择一个非 isr 副本作为新的 Leader,
* 此时存在丢失数据的风险,需要配置文件中的 unclean.leader.election.enable 为 true
* 或者 topic 被配置为允许 unclean election 时才会执行。
*
* @param leaderIsrAndControllerEpochs set of partition to determine if unclean leader election should be
* allowed
* @param allowUnclean whether to allow unclean election without having to read the topic configuration
* @return a sequence of three element tuple:
* 1. topic partition
* 2. leader, isr and controller epoc. Some means election should be performed
* 3. allow unclean
*/
private def collectUncleanLeaderElectionState(
leaderAndIsrs: Seq[(TopicPartition, LeaderAndIsr)],
allowUnclean: Boolean
): Seq[(TopicPartition, Option[LeaderAndIsr], Boolean)] = {
// 根据 isr 中是否有 online replica 分为两组
val (partitionsWithNoLiveInSyncReplicas, partitionsWithLiveInSyncReplicas) = leaderAndIsrs.partition {
case (partition, leaderAndIsr) =>
val liveInSyncReplicas = leaderAndIsr.isr.filter(controllerContext.isReplicaOnline(_, partition))
liveInSyncReplicas.isEmpty
}
// 如果配置文件中
// 支持 unclean 选举,则直接返回 (partition, isr, true)
// 不支持 unclean 选举,则去 zk 查询每个 topic 的独立配置,看是否支持 unclean 选举
val electionForPartitionWithoutLiveReplicas = if (allowUnclean) {
// 如果允许 unclean 选举,则直接返回这部分数据
partitionsWithNoLiveInSyncReplicas.map { case (partition, leaderAndIsr) =>
(partition, Option(leaderAndIsr), true)
}
} else {
// 查询 zk 上 /config/topics/{topic} 配置信息
val (logConfigs, failed) = zkClient.getLogConfigs(
partitionsWithNoLiveInSyncReplicas.iterator.map { case (partition, _) => partition.topic }.toSet,
config.originals()
)
partitionsWithNoLiveInSyncReplicas.map { case (partition, leaderAndIsr) =>
if (failed.contains(partition.topic)) {
// 如果没查到配置信息,则不允许 unclean 选举
logFailedStateChange(partition, partitionState(partition), OnlinePartition, failed(partition.topic))
(partition, None, false)
} else {
// 如果查到了配置信息,则以配置信息为准
(
partition,
Option(leaderAndIsr),
logConfigs(partition.topic).uncleanLeaderElectionEnable.booleanValue()
)
}
}
}
// 将支持 unclean 选举的分区信息,与符合正常选举条件的分区信息合并起来
electionForPartitionWithoutLiveReplicas ++
partitionsWithLiveInSyncReplicas.map { case (partition, leaderAndIsr) =>
(partition, Option(leaderAndIsr), false)
}
}b. 分区选举核心逻辑
private def leaderForOffline(partition: TopicPartition,
leaderAndIsrOpt: Option[LeaderAndIsr],
uncleanLeaderElectionEnabled: Boolean,
controllerContext: ControllerContext): ElectionResult = {
// 从 ctx 中找到分区的 replica 信息
val assignment = controllerContext.partitionReplicaAssignment(partition)
// 再筛出处于 OnlineReplica 状态的 replica
val liveReplicas = assignment.filter(replica => controllerContext.isReplicaOnline(replica, partition))
leaderAndIsrOpt match {
case Some(leaderAndIsr) =>
val isr = leaderAndIsr.isr
// 选举
val leaderOpt = PartitionLeaderElectionAlgorithms.offlinePartitionLeaderElection(
assignment, isr, liveReplicas.toSet, uncleanLeaderElectionEnabled, controllerContext)
val newLeaderAndIsrOpt = leaderOpt.map { leader =>
// 如果新 leader 就在 isr 中,则继续使用原来的 isr,保留 OnlineReplica 的即可
// 如果新 leader 不再 isr 中,则说明选出了新的 leader,则原来的 isr 不可用了,
// 新的 isr 中只有一个 leader,需要其他的 replica 的数据同步之后才能加入 isr
val newIsr = if (isr.contains(leader)) isr.filter(replica => controllerContext.isReplicaOnline(replica, partition))
else List(leader)
// 更新 leaderAndIsr 信息
leaderAndIsr.newLeaderAndIsr(leader, newIsr)
}
ElectionResult(partition, newLeaderAndIsrOpt, liveReplicas)
case None =>
ElectionResult(partition, None, liveReplicas)
}
}这段代码中有一个 PartitionLeaderElectionAlgorithms,我们看看它到底是啥东西:
object PartitionLeaderElectionAlgorithms {
/**
* 因为 Leader 副本下线而引发的分区 Leader 选举
*
* @param assignment ctx 中保存的 replica assignment 信息
* @param isr zk 上保存的 isr 信息
* @param liveReplicas ctx 中处于 OnlineReplica 状态的 replica id
* @param uncleanLeaderElectionEnabled 是否允许 unclean 选举
* @param controllerContext ctx
* @return
*/
def offlinePartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], uncleanLeaderElectionEnabled: Boolean, controllerContext: ControllerContext): Option[Int] = {
// 找出
// 既处于 zk 的 isr 中,又处于 OnlineReplica 状态的 replica
// 或者
// 如果允许 unclean 选举,则忽略 isr,直接从 OnlineReplica 状态的 replica 中找
assignment.find(id => liveReplicas.contains(id) && isr.contains(id)).orElse {
if (uncleanLeaderElectionEnabled) {
val leaderOpt = assignment.find(liveReplicas.contains)
if (leaderOpt.isDefined)
controllerContext.stats.uncleanLeaderElectionRate.mark()
leaderOpt
} else {
None
}
}
}
// 因为执行分区副本重分配操作而引发的分区 Leader 选举
def reassignPartitionLeaderElection(reassignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
// 既处于 zk 的 isr 中,又处于 OnlineReplica 状态的 replica
reassignment.find(id => liveReplicas.contains(id) && isr.contains(id))
}
// 因为执行 Preferred 副本 Leader选举而引发的分区 Leader 选举
def preferredReplicaPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
// 只看 assignment 中的第一个元素,
// 如果既处于 zk 的 isr 中,又处于 OnlineReplica 状态的 replica,则返回
assignment.headOption.filter(id => liveReplicas.contains(id) && isr.contains(id))
}
// 因为正常关闭 Broker 而引发的分区 Leader 选举
def controlledShutdownPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], shuttingDownBrokers: Set[Int]): Option[Int] = {
assignment.find(id => liveReplicas.contains(id) && isr.contains(id) && !shuttingDownBrokers.contains(id))
}
}ok 原来这才是真正选 leader 的代码
三、onTopicDeletion()
有了对 PartitionStateMachine 的基本认识之后,现在我们再来看一看 onTopicDeletion 方法:
private def onTopicDeletion(topics: Set[String]): Unit = {
// 过滤掉已经进入删除流程的 topic,留下将要删除的 topic
val unseenTopicsForDeletion = topics.diff(controllerContext.topicsWithDeletionStarted)
// 首次执行删除,将 topic 添加到 topicsWithDeletionStarted 列表中
// 表示开始删除
if (unseenTopicsForDeletion.nonEmpty) {
val unseenPartitionsForDeletion = unseenTopicsForDeletion.flatMap(controllerContext.partitionsForTopic)
// 由于状态机严格限制 partition 状态之间的流转关系,
// 所以这里先将 partition 标记为 offline 状态,再标记为 NonExistent 状态
partitionStateMachine.handleStateChanges(unseenPartitionsForDeletion.toSeq, OfflinePartition)
partitionStateMachine.handleStateChanges(unseenPartitionsForDeletion.toSeq, NonExistentPartition)
// adding of unseenTopicsForDeletion to topics with deletion started must be done after the partition
// state changes to make sure the offlinePartitionCount metric is properly updated
//
// 一定要先更新 partition 的状态
// 再去把还没开始删除的 topic 列表加入到 topicsWithDeletionStarted 中;
// 否则会影响到 offlinePartitionCount 这个 metric 的值
//
// 将 topic 加入到 topicsWithDeletionStarted 列表中
controllerContext.beginTopicDeletion(unseenTopicsForDeletion)
}
// send update metadata so that brokers stop serving data for topics to be deleted
// 发送更新元数据的请求
client.sendMetadataUpdate(topics.flatMap(controllerContext.partitionsForTopic))
// 删除 partition
onPartitionDeletion(topics)
}要删 topic 就得删除 partition,要删 partition 就得删除 replica,这里的 onPartitionDeletion() 方法,实际上是去更新 Replica State Machine 的。
四、副本状态机
和分区状态机 ParititionStateMachine 一样,当 controller 选举成功之后,就会调用 stateMachine 的 startup 方法,来启动副本状态机 ReplicaStateMachine
1、ReplicaStateMachine.startup()
下面是 ReplicaStateMachine 的定义以及 startup 方法:
abstract class ReplicaStateMachine(controllerContext: ControllerContext) extends Logging {
/**
* Invoked on successful controller election.
*/
def startup(): Unit = {
// 对于每一个 replica,
// 如果所在的 broker 可以正常工作,则标记为 OnlineReplica
// 如果所在的 broker 挂了,则标记为暂不允许删除 ReplicaDeletionIneligible
info("Initializing replica state")
initializeReplicaState()
// 读取 ctx 中的 partitionAssignments 信息,将所有的 replica 分为两组,
// 所在 broker 正常工作的放入 onlineReplicas
// 所在 broker 无法正常工作的放入 offlineReplicas
val (onlineReplicas, offlineReplicas) = controllerContext.onlineAndOfflineReplicas
// 流转状态机
info("Triggering online replica state changes")
handleStateChanges(onlineReplicas.toSeq, OnlineReplica)
// 流转状态机
info("Triggering offline replica state changes")
handleStateChanges(offlineReplicas.toSeq, OfflineReplica)
debug(s"Started replica state machine with initial state -> ${controllerContext.replicaStates}")
}
......
def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit
}
2、状态机流转
和 PartitionStateMachine 类似,ReplicaStateMachine 也是一个抽象类,它同样有两个子类,一个叫 MockReplicaStateMachine,看名字就知道是测试用的。另一个就是真正干活的 ZkReplicaStateMachine,我们这里直接去看它是如何实现 handleStateChanges() 方法的:
class ZkReplicaStateMachine(config: KafkaConfig,
stateChangeLogger: StateChangeLogger,
controllerContext: ControllerContext,
zkClient: KafkaZkClient,
controllerBrokerRequestBatch: ControllerBrokerRequestBatch)
extends ReplicaStateMachine(controllerContext) with Logging {
private val controllerId = config.brokerId
this.logIdent = s"[ReplicaStateMachine controllerId=$controllerId] "
override def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
if (replicas.nonEmpty) {
try {
// 确保缓存中没有未发送的请求,如果有的话会抛出异常
controllerBrokerRequestBatch.newBatch()
// 进行状态转换。
// 注意这里是根据 replicaId 分组执行的,
// 即一次将一个 broker 的请求都处理完,避免多次发送请求。
//
// 状态转换过程后,如果有以下三类请求需要发送,
// 1. LeaderAndIsr
// 2. UpdateMetadata
// 3. StopReplica
// 会先暂存起来,然后通过下文的 sendRequestsToBrokers 方法发送给其他 broker
replicas.groupBy(_.replica).forKeyValue { (replicaId, replicas) =>
doHandleStateChanges(replicaId, replicas, targetState)
}
// 将上文暂存的请求发送给 broker
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
} catch {
case e: ControllerMovedException =>
error(s"Controller moved to another broker when moving some replicas to $targetState state", e)
throw e
case e: Throwable => error(s"Error while moving some replicas to $targetState state", e)
}
}
}
......
}
从上面的代码可以看到,为了提高通信效率,kafka 都是依次处理完所有的 replica,然后将需要发送的请求收集起来,最后统一处理的。
其中的 doHandleStateChanges() 方法,是真正去处理状态机的流转的,源码中,为 ReplicaState 定义了七种状态:
NewReplica:副本被创建之后所处的状态
OnlineReplica:副本正常运行
OfflineReplica:副本下线
ReplicaDeletionStarted:副本删除任务已启动
ReplicaDeletionSuccessful:副本删除成功
ReplicaDeletionIneligible:副本暂时无法被删除(所在的 broker 宕机,或者无法正确响应 LeaderAndIsr 请求)
NonExistentReplica:副本从副本状态机被移除前所处的状态他们之间的流转关系如图所示:
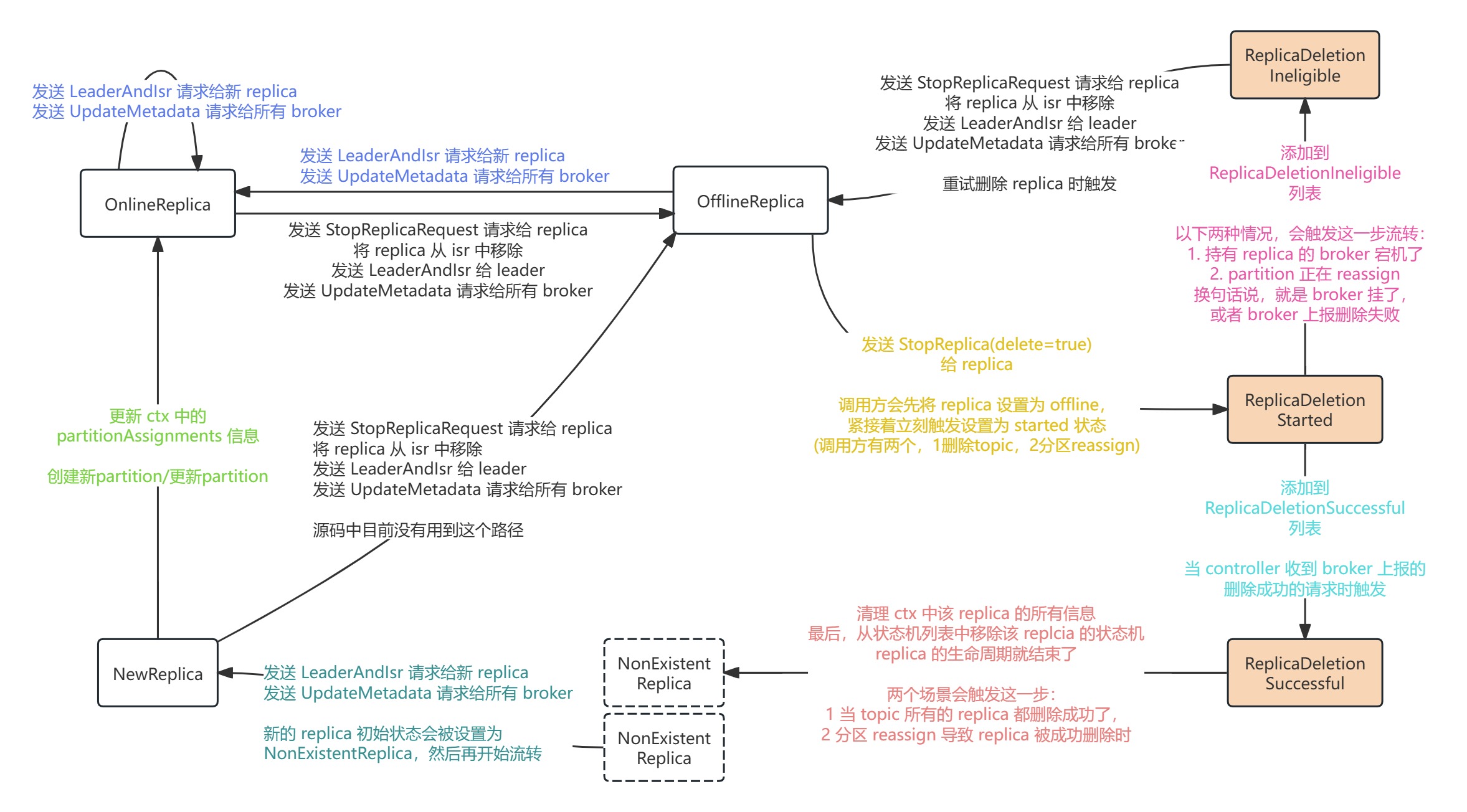
参照这张图,我们再来看 doHandleStateChanges() 的具体实现:
private def doHandleStateChanges(replicaId: Int, replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
val stateLogger = stateChangeLogger.withControllerEpoch(controllerContext.epoch)
val traceEnabled = stateLogger.isTraceEnabled
// 新加入的 replica,其状态都会被设置为 NonExistentReplica,然后再开始流转
replicas.foreach(replica => controllerContext.putReplicaStateIfNotExists(replica, NonExistentReplica))
// 状态机之间有严格的流转关系,这里过略掉非法的状态流转
val (validReplicas, invalidReplicas) = controllerContext.checkValidReplicaStateChange(replicas, targetState)
invalidReplicas.foreach(replica => logInvalidTransition(replica, targetState))
// 根据目标状态,流转状态,执行具体操作
targetState match {
case NewReplica =>
validReplicas.foreach { replica =>
val partition = replica.topicPartition
val currentState = controllerContext.replicaState(replica)
// 尝试从元数据缓存中获取分区信息,包括 Leader 信息、ISR 都有哪些副本等
controllerContext.partitionLeadershipInfo(partition) match {
// 如果成功拿到分区数据信息
case Some(leaderIsrAndControllerEpoch) =>
// 如果该副本是 Leader
if (leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId) {
// 记录错误日志。Leader副本不能被设置成 NewReplica 状态
val exception = new StateChangeFailedException(s"Replica $replicaId for partition $partition cannot be moved to NewReplica state as it is being requested to become leader")
logFailedStateChange(replica, currentState, OfflineReplica, exception)
} else {
// 如果该副本不是 Leader,
// 给该副本所在的 Broker 发送 LeaderAndIsrRequest
// 然后给集群当前所有 Broker 发送 UpdateMetadataRequest 通知它们该分区数据发生变更
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(replica.topicPartition),
isNew = true)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, NewReplica)
// 更新本地缓存
controllerContext.putReplicaState(replica, NewReplica)
}
case None =>
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, NewReplica)
// 如果找不到 leader 信息,则仅更新元数据缓存的状态为 NewReplica
controllerContext.putReplicaState(replica, NewReplica)
}
}
case OnlineReplica =>
validReplicas.foreach { replica =>
val partition = replica.topicPartition
val currentState = controllerContext.replicaState(replica)
currentState match {
case NewReplica =>
val assignment = controllerContext.partitionFullReplicaAssignment(partition)
// 如果 replica 不在 assignment cache 中,则添加到 assignment cache 中
if (!assignment.replicas.contains(replicaId)) {
error(s"Adding replica ($replicaId) that is not part of the assignment $assignment")
val newAssignment = assignment.copy(replicas = assignment.replicas :+ replicaId)
controllerContext.updatePartitionFullReplicaAssignment(partition, newAssignment)
}
// 在变为 NewReplica 状态的时候,已经通知了其他 broker,这里不需要再通知了
case _ =>
controllerContext.partitionLeadershipInfo(partition) match {
case Some(leaderIsrAndControllerEpoch) =>
// 发送 LeaderAndIsr 请求给对应的 broker 来更新 replica 信息
// 发送 UpdateMetadata 请求给所有 broker
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
case None =>
}
}
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, OnlineReplica)
controllerContext.putReplicaState(replica, OnlineReplica)
}
case OfflineReplica =>
// 这里的 validReplicas 类型是 PartitionAndReplica
// 准备发送 StopReplica 请求,注意这里不是直接发送,只是将请求先暂存起来
// 等状态机处理完后,再统一发送。
// (broker 在收到 StopReplica 请求后,会从 ctx 中移除 replica 的信息,并停止拉取数据)
validReplicas.foreach { replica =>
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = false)
}
// 查询 ctx 中的分区 leader 信息
val (replicasWithLeadershipInfo, replicasWithoutLeadershipInfo) = validReplicas.partition { replica =>
controllerContext.partitionLeadershipInfo(replica.topicPartition).isDefined
}
// 对于 ctx 中有 leader 信息的分区,将 replica 从 ISR 中移除
// 更新 ctx,同时更新到 zk 的节点:
// /brokers/topics/[topic_name]/partitions/[partition_id]/state
// 这个节点里的数据长这样:
// {
// "controller_epoch": 9,
// "leader": 0,
// "version": 1,
// "leader_epoch": 1,
// "isr": [0, 1]
// }
// 下文会详细阅读这个方法的代码。
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasWithLeadershipInfo.map(_.topicPartition))
updatedLeaderIsrAndControllerEpochs.forKeyValue { (partition, leaderIsrAndControllerEpoch) =>
stateLogger.info(s"Partition $partition state changed to $leaderIsrAndControllerEpoch after removing replica $replicaId from the ISR as part of transition to $OfflineReplica")
// 如果不是待删除的 topic,需要发送 LeaderAndIsr 请求给其余 broker
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
partition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
}
// 记录日志
val replica = PartitionAndReplica(partition, replicaId)
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, OfflineReplica)
// 最终设置为 offline
controllerContext.putReplicaState(replica, OfflineReplica)
}
// 对于 ctx 中找不到 leader 信息的分区,记录日志并设置为 offline
replicasWithoutLeadershipInfo.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, replica.topicPartition, currentState, OfflineReplica)
// 由于找不到 leader 信息,所以这个方法里仅记录日志,什么都不做
// "Leader not yet assigned for partition $partition
// Skip sending UpdateMetadataRequest."
controllerBrokerRequestBatch.addUpdateMetadataRequestForBrokers(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(replica.topicPartition))
// 最终设置为 offline
controllerContext.putReplicaState(replica, OfflineReplica)
}
case ReplicaDeletionStarted =>
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, replica.topicPartition, currentState, ReplicaDeletionStarted)
// 设置为 ReplicaDeletionStarted
controllerContext.putReplicaState(replica, ReplicaDeletionStarted)
// enqueue stopReplica 请求
// 注意这里 deletePartition = true,所以
// broker 在收到 StopReplica 请求后,会停止拉取数据,
// 还会将对应的分区(副本)目录加上 -delete 后缀,最终会删除掉整个 log 目录
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = true)
// 这里有一个疑问,发送了StopReplica,为什么不发送 UpdateMetadata 请求更新元数据呢?
// 我理解是,ReplicaDeletionStarted 状态,是由 OfflineReplica 状态流转过来的,
// 在 OfflineReplica 状态下,已经发送了 UpdateMetadata 更新过元数据了,
// 上面这段代码只是做状态的流转,并没有其他变更,所以不需要再发送 UpdateMetadata 请求
}
case ReplicaDeletionIneligible =>
// 单纯做标记
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, replica.topicPartition, currentState, ReplicaDeletionIneligible)
controllerContext.putReplicaState(replica, ReplicaDeletionIneligible)
}
case ReplicaDeletionSuccessful =>
// 单纯做标记
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, replica.topicPartition, currentState, ReplicaDeletionSuccessful)
controllerContext.putReplicaState(replica, ReplicaDeletionSuccessful)
}
case NonExistentReplica =>
// 这里的 replica 类型是 PartitionAndReplica
validReplicas.foreach { replica =>
// 查出 PartitionAndReplica 当前 state
val currentState = controllerContext.replicaState(replica)
// 从 ctx 中删除当前 replica
val newAssignedReplicas = controllerContext
// 根据 topic 和 partition,查出所有的 ReplicaAssignment 列表
.partitionFullReplicaAssignment(replica.topicPartition)
// 删除当前 replicaId
.removeReplica(replica.replica)
controllerContext.updatePartitionFullReplicaAssignment(replica.topicPartition, newAssignedReplicas)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, replica.topicPartition, currentState, NonExistentReplica)
// 从状态机列表中删除当前 replica 的状态机,它的生命周期就结束了
controllerContext.removeReplicaState(replica)
}
}
}a. 移出 ISR
下面再来看看 kafka 是如何从 ISR 中移除 replica 的
private def removeReplicasFromIsr(
replicaId: Int,
partitions: Seq[TopicPartition]
): Map[TopicPartition, LeaderIsrAndControllerEpoch] = {
var results = Map.empty[TopicPartition, LeaderIsrAndControllerEpoch]
var remaining = partitions
while (remaining.nonEmpty) {
val (finishedRemoval, removalsToRetry) = doRemoveReplicasFromIsr(replicaId, remaining)
remaining = removalsToRetry
finishedRemoval.foreach {
// 移出 isr 过程中出现异常,则记录日志
case (partition, Left(e)) =>
val replica = PartitionAndReplica(partition, replicaId)
val currentState = controllerContext.replicaState(replica)
logFailedStateChange(replica, currentState, OfflineReplica, e)
// 成功移出 isr,记录结果
case (partition, Right(leaderIsrAndEpoch)) =>
results += partition -> leaderIsrAndEpoch
}
}
results
}
/**
* Try to remove a replica from the isr of multiple partitions.
* Removing a replica from isr updates partition state in zookeeper.
*
* 尝试从多个分区的 ISR(同步副本集合)中移除一个副本。
* 从 ISR 中移除副本会更新 Zookeeper 中的分区状态。
*
* @param replicaId The replica being removed from isr of multiple partitions
* 要从多个分区的 ISR 中移除的副本 ID
*
* @param partitions The partitions from which we're trying to remove the replica from isr
* 需要从这些分区的 ISR 中移除副本
*
*@return A tuple of two elements:
* 1. The updated Right[LeaderIsrAndControllerEpochs] of all partitions for which we successfully
* removed the replica from isr. Or Left[Exception] corresponding to failed removals that should
* not be retried
* 2. The partitions that we should retry due to a zookeeper BADVERSION conflict. Version conflicts can occur if
* the partition leader updated partition state while the controller attempted to update partition state.
*
*一个包含两个元素的元组:
* 1. 一个映射,包含成功从 ISR 中移除副本的所有分区的新状态:
* - 如果成功,返回 Right[LeaderIsrAndControllerEpochs]。
* - 如果失败且不应重试,返回 Left[Exception]。
* 2. 由于 Zookeeper 的 BADVERSION 冲突而需要重试的分区列表。
* 版本冲突可能发生在 controller 尝试更新分区状态的同时,分区的 Leader 也更新了分区状态。
*/
private def doRemoveReplicasFromIsr(
replicaId: Int,
partitions: Seq[TopicPartition]
): (Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]], Seq[TopicPartition]) = {
// 查询 /brokers/topics/[topic_name]/partitions/[partition_id]/state 下的数据
// 数据长这样:
// {
// "controller_epoch": 9,
// "leader": 0,
// "version": 1,
// "leader_epoch": 1,
// "isr": [0, 1]
// }
//
// 如果在 zk 上找不到 node,就把 partition 放入 partitionsWithNoLeaderAndIsrInZk 中
val (leaderAndIsrs, partitionsWithNoLeaderAndIsrInZk) = getTopicPartitionStatesFromZk(partitions)
// 找出待移除的条目 (即 isr 中包含 replicaId 的条目)
val (leaderAndIsrsWithReplica, leaderAndIsrsWithoutReplica) = leaderAndIsrs.partition { case (_, result) =>
result.map { leaderAndIsr =>
leaderAndIsr.isr.contains(replicaId)
}.getOrElse(false)
}
// 调整 leader 和 ISR
val adjustedLeaderAndIsrs: Map[TopicPartition, LeaderAndIsr] = leaderAndIsrsWithReplica.flatMap {
case (partition, result) =>
result.toOption.map { leaderAndIsr =>
// 确定 leader。如果待移除的 replicaId 是 leader,则将 leader_id 设置为 -1
val newLeader = if (replicaId == leaderAndIsr.leader) LeaderAndIsr.NoLeader else leaderAndIsr.leader
// 确定 isr。如果 isr 中只有一个元素,而且是 replicaId,则不变。否则,从查询出的 isr 中移除 replicaId
val adjustedIsr = if (leaderAndIsr.isr.size == 1) leaderAndIsr.isr else leaderAndIsr.isr.filter(_ != replicaId)
partition -> leaderAndIsr.newLeaderAndIsr(newLeader, adjustedIsr)
}
}
// 更新 zk 上的数据
// /brokers/topics/[topic_name]/partitions/[partition_id]/state
val UpdateLeaderAndIsrResult(finishedPartitions, updatesToRetry) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs, controllerContext.epoch, controllerContext.epochZkVersion)
// zk 上找不到 node 并且 partition 不在删除队列中,找出这部分数据
val exceptionsForPartitionsWithNoLeaderAndIsrInZk: Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]] =
partitionsWithNoLeaderAndIsrInZk.iterator.flatMap { partition =>
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
val exception = new StateChangeFailedException(
s"Failed to change state of replica $replicaId for partition $partition since the leader and isr " +
"path in zookeeper is empty"
)
Option(partition -> Left(exception))
} else None
}.toMap
// 收集: 不需要做删除操作的 ++ 执行完删除操作的
val leaderIsrAndControllerEpochs: Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]] = {
// 更新 ctx 中的 LeaderAndIsr 信息
(leaderAndIsrsWithoutReplica ++ finishedPartitions).map { case (partition, result) =>
(partition, result.map { leaderAndIsr =>
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
controllerContext.putPartitionLeadershipInfo(partition, leaderIsrAndControllerEpoch)
leaderIsrAndControllerEpoch
})
}
}
if (isDebugEnabled) {
updatesToRetry.foreach { partition =>
debug(s"Controller failed to remove replica $replicaId from ISR of partition $partition. " +
s"Attempted to write state ${adjustedLeaderAndIsrs(partition)}, but failed with bad ZK version. This will be retried.")
}
}
// 返回结果
// Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]]
// 对于执行成功的, value 是 LeaderIsrAndControllerEpoch
// 对于没成功的(不属于删除队列,且在 zk 上不存在), value 是 Exception
(leaderIsrAndControllerEpochs ++ exceptionsForPartitionsWithNoLeaderAndIsrInZk, updatesToRetry)
}
五、onPartitionDeletion()
了解了 Replica State Machine 的基本工作流程,我们再来看 onPartitionDeletion 方法:
/**
* Invoked by onTopicDeletion with the list of partitions for topics to be deleted
* It does the following -
* 1. Move all dead replicas directly to ReplicaDeletionIneligible state. Also mark the respective topics ineligible
* for deletion if some replicas are dead since it won't complete successfully anyway
* 2. Move all replicas for the partitions to OfflineReplica state. This will send StopReplicaRequest to the replicas
* and LeaderAndIsrRequest to the leader with the shrunk ISR. When the leader replica itself is moved to OfflineReplica state,
* it will skip sending the LeaderAndIsrRequest since the leader will be updated to -1
* 3. Move all replicas to ReplicaDeletionStarted state. This will send StopReplicaRequest with deletePartition=true. And
* will delete all persistent data from all replicas of the respective partitions
*
* 1. 把宕机的 replica 设置为 ReplicaDeletionIneligible 状态。
* 其他相关的 topics 也都设置为该状态。因为 broker 挂了,这个请求无法完成。
* 2. 将分区的所有 replica 设置为 OfflineReplica。
* 向其他 replica 发送 StopReplicaRequest 请求
* 并向 leader 副本发送 LeaderAndIsrRequest 请求,参数中携带了发生减员的 ISR。
* 当 leader 副本被设置为 OfflineReplica 时,不会发送 LeaderAndIsrRequest,
* 因为 leader 已经不存在了(被更新为-1)。
* 3. 将所有的 replica 加入 ReplicaDeletionStarted 列表。
* 发送 StopReplicaRequest(deletePartition=true) 给 replica,
* 然后从磁盘中删除数据
*
*/
private def onPartitionDeletion(topicsToBeDeleted: Set[String]): Unit = {
val allDeadReplicas = mutable.ListBuffer.empty[PartitionAndReplica]
val allReplicasForDeletionRetry = mutable.ListBuffer.empty[PartitionAndReplica]
val allTopicsIneligibleForDeletion = mutable.Set.empty[String]
topicsToBeDeleted.foreach { topic =>
// 此处的 deadReplicas 指
// 在 shuttingDownBrokerIds 中的 broker (收到关机请求 ApiKeys.CONTROLLED_SHUTDOWN 的 broker)
// 或者 无法正常响应 LeaderAndIsr 请求的 broker
val (aliveReplicas, deadReplicas) = controllerContext.replicasForTopic(topic).partition { r =>
controllerContext.isReplicaOnline(r.replica, r.topicPartition)
}
val successfullyDeletedReplicas = controllerContext.replicasInState(topic, ReplicaDeletionSuccessful)
val replicasForDeletionRetry = aliveReplicas.diff(successfullyDeletedReplicas)
// 统计宕机/关机的 broker,设置为 ReplicaDeletionIneligible
allDeadReplicas ++= deadReplicas
// 统计尚未删除的 replica,执行删除任务
allReplicasForDeletionRetry ++= replicasForDeletionRetry
// 大原则,关机/挂了的 broker 不能删,因为它们处理不了请求
if (deadReplicas.nonEmpty) {
debug(s"Dead Replicas (${deadReplicas.mkString(",")}) found for topic $topic")
allTopicsIneligibleForDeletion += topic
}
}
// 统计宕机/关机的 broker,设置为 ReplicaDeletionIneligible
replicaStateMachine.handleStateChanges(allDeadReplicas, ReplicaDeletionIneligible)
// send stop replica to all followers that are not in the OfflineReplica state so they stop sending fetch requests to the leader
//
// 发送 stopReplica(deletion=false),发送更新 ISR 请求,发送 updateMetadata 请求
replicaStateMachine.handleStateChanges(allReplicasForDeletionRetry, OfflineReplica)
// 发送 stopReplica(deletion=true),broker 在收到请求后,会将整个目录加上 -delete 后缀
replicaStateMachine.handleStateChanges(allReplicasForDeletionRetry, ReplicaDeletionStarted)
if (allTopicsIneligibleForDeletion.nonEmpty) {
markTopicIneligibleForDeletion(allTopicsIneligibleForDeletion, reason = "offline replicas")
}
}
至此,这个 topic 相关的概念,就完全从 kafka 里移除了。
但其实还留有最后一个尾巴,就是 kafka 并没有立刻删除所有的 log 文件,而是给 topic 对应的 log 目录加上了 -deleted 后缀;Kafka 的 LogManager 组件负责定期检查并删除这些带 -deleted 后缀的目录(执行间隔由 log.retention.check.interval.ms(默认 5 分钟)控制),到这一步,topic 就完全从世界上消失了。
