〇、【引子】
由于老婆经常拿着手机问我,“这件衣服好看吗” “这件衣服我能穿吗”...... 我实在是受不了了,所以萌生出了写一个 AI 换衣工具的想法。
虽然豆包已经有这个功能了,但是操作起来比较麻烦,每次还得输入提示词。为了最大程度减少老婆大人操作的复杂度,我决定还是自己写一个,让她可以:
- 上传自己的照片
- 上传衣服/模特图片
- 点击按钮生成图片
一、【开发】
借助 ChatGPT 和千问,差不多半天就写完了所有的代码(主要是调样式耗费时间)。技术栈是:
- 字节 Seedream4.5 图像大模型
- 后端:Python
- 前端:html,css,js
本地运行的界面如下:
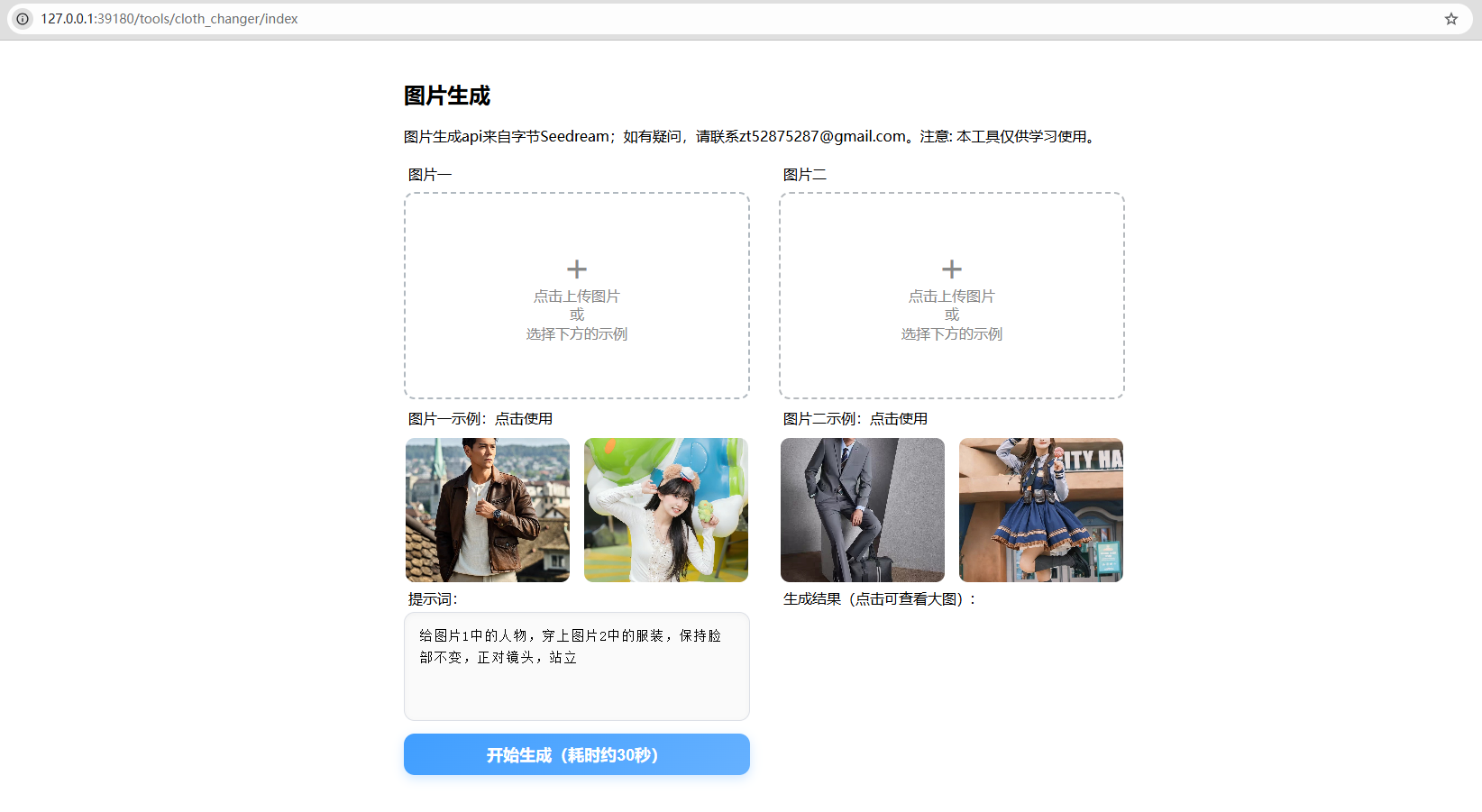
本地运行界面
为了方便用户测试,我在界面上放了几张预置图片。那么问题就来了:这些预置图片放在哪里好呢?
那当然不能放服务器上了!既占空间又占带宽,还有可能被人猛猛刷流量,所以最好的方案就是:cdn + 云存储。(博客里的其他图片也都是这样)
ok,上传图片到腾讯云对象存储服务中,然后把链接塞到 html 里,再次启动......
踩坑:图片跨域
点击示例图片,点击生成,卧槽,明明已经选择了图片,怎么还提示让我“上传两张图片”?
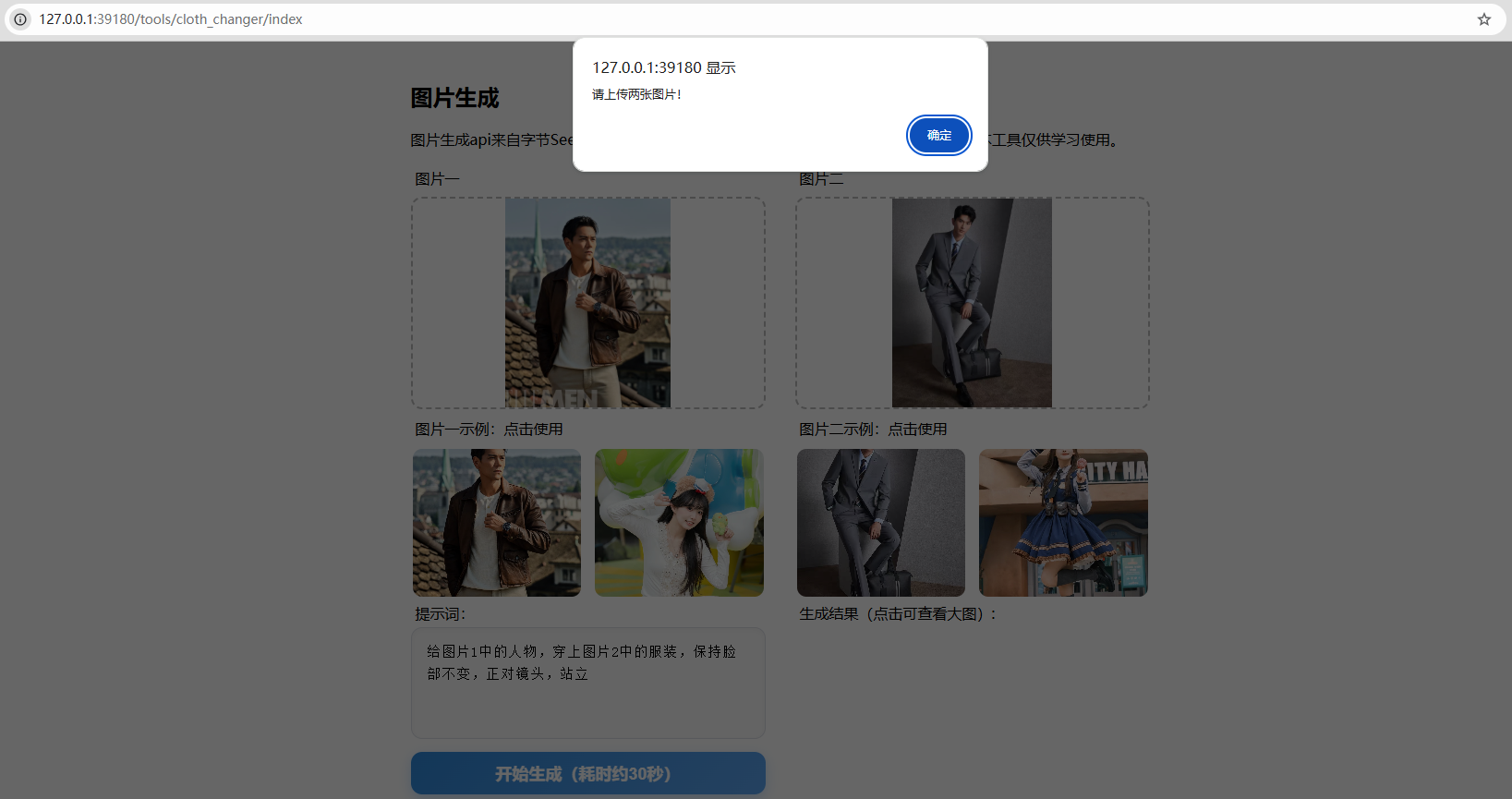
打开 console 一看,从 url 下载图片的时候跨域了......
原因是点击示例图片的时候,会下载图片并转换成 blob,这一步被拦住了,图片并没有被加载到 post body 里,所以点击 “生成” 的时候,会提示 “请上传两张图片”
不对啊,既然跨域了,那为什么界面上还能显示出图片,它应该是裂掉的才对呀?
为什么 HTML <img> 可以加载,而 JS 不能呢? ChatGPT 告诉我:
- HTML
<img src="...">是浏览器直接渲染图片,不涉及读取图片内容到 JavaScript,所以不会被浏览器的同源策略阻止。 - 但如果在 js 里使用 fetch(url) 读取(下载)图片内容时,浏览器就会检测跨域请求,此时如果服务器没有返回 Access-Control-Allow-Origin,就会报错。
出于安全考虑,我不打算放宽限制,(在 cdn 上把图片的访问策略 access-control-allow-origin 设置为 *),所以这个问题在本地是无法解决的。
我在本地只能验证 上传图片 + 生成图片 的 case,无法验证 点击选用示例图片 + 生成图片 的 case。
倒也不影响,只要部署到服务器上能跑就行。
二、【部署】
“对于一个程序来说,能够本地运行,才是第一步,距离对用户提供服务,还差着十万八千里”
本地代码写完,推到 github,然后到服务器拉取代码,配置 nginx:
location ^~ /tools/cloth_changer/ {
proxy_pass http://127.0.0.1:39180;
send_timeout 200s;
proxy_connect_timeout 200s;
proxy_send_timeout 200s;
proxy_read_timeout 200s;
}
字节的图片生成接口耗时在 15-50 秒左右,所以我把各种超时时间都拉大了许多。
三、【异象】
折腾了一大圈,总算把环境弄好了。打开页面,选择示例图片,生成~
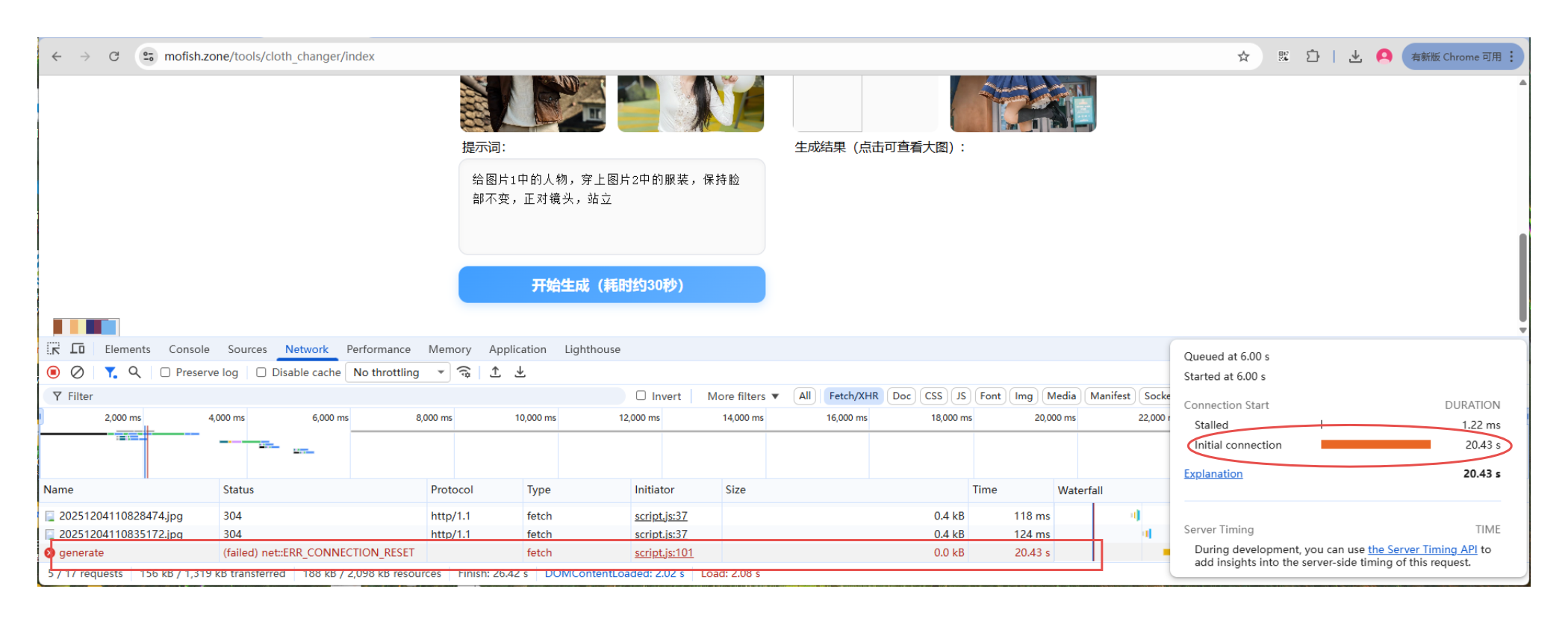
报错提示 err_connection_reset
我蒙了,怎么 20 秒就被 reset 了,而且连接一直处于 initial connection 阶段?

Chrome 官方对 initial connection 的说明
查了下服务的日志,发现:后台即时收到了请求,并且完整的执行完了,所以可以排除 request body 异常(或过大),导致传输失败,连接被掐断
而后台执行的整体耗时大约在 40~50 秒左右,还没有返回任何数据,请求就被被掐断了,所以可以排除是 response body 异常(或过大),导致传输失败,连接被掐断
这么看来,大概率还是中间 nginx 等待超时导致请求被掐断了。可我明明把 nginx 的超时时间设的很长呀,一水的 200s,怎么可能 20s 就被掐了呢。
为了验证这一点,我把端口直接暴露出来,从公网通过 ip + port 访问,这下果然正常了。
直连正常,过 nginx 会 reset,那基本可以确定问题出在 nginx 了。
四、【迷雾重重】
1. 检查 nginx 配置
由于 nginx 是用宝塔面板安装的,所以它的主配置文件结构如下:
stream {......}
events {......}
http
{
......
include proxy.conf;
keepalive_timeout 60;
client_header_timeout 200s;
client_body_timeout 200s;
send_timeout 200s;
......
include /www/server/panel/vhost/nginx/*.conf;
}proxy.conf
client_body_buffer_size 512k;
proxy_connect_timeout 60;
proxy_read_timeout 60;
proxy_send_timeout 60;
proxy_buffer_size 32k;
proxy_buffers 4 64k;
proxy_busy_buffers_size 128k;
proxy_temp_file_write_size 128k;
proxy_next_upstream error timeout invalid_header http_500 http_503 http_404;
proxy_cache cache_one;新加的服务路由:
server
{
listen 80;
listen 443 ssl;
......
location ^~ /tools/cloth_changer/ {
proxy_pass http://127.0.0.1:39180;
send_timeout 200s;
proxy_connect_timeout 200s;
proxy_send_timeout 200s;
proxy_read_timeout 200s;
}
......
}
看起来都没啥问题,甚至整个配置文件也搜不出来跟 20 相关的数字。
在 ChatGPT 的建议之下,我又分多次往 nginx 配置文件里塞了许多东西:
proxy_http_version 1.1;
proxy_set_header Connection "";
client_body_timeout 600s;
send_timeout 600s;
proxy_connect_timeout 600s;
proxy_send_timeout 600s;
proxy_read_timeout 600s;
proxy_request_buffering on;
proxy_buffering off;但不管怎么改,接口仍然是 20 秒超时。
nginx 的 error.log 里啥都没有,access.log 里倒是明明白白写着请求是 200

无论是浏览器、还是 curl 命令,后台实际上都成功了
然而我的 nginx 版本又不支持开启 Debug,这条路暂时走不通了。
2. 真正的超时时间
经过和 ChatGPT 的多轮博弈之后,它提示我在网站上 curl 的时候加上 time,看一看耗时到底是多少。我一试,立刻发现了端倪!
curl 的时候,超时时间是 10 秒!!!
浏览器访问的时候,超时时间是 20 秒!!!
再结合我之前查日志的时候,发现了、却没有重视的一个现象:我在浏览器发起一个请求的时候,后端会相差 10s 收到两条请求,他们的日志是交织在一起的。
我突然反应过来:真正的超时时间是 10 秒,而不是 20 秒!
一定是 nginx 检测到后端服务 10s 没有了响应,重发了请求
在我把 nginx 配置又一次贴给 ChatGPT 之后,这个坑货告诉我,重试行为来自 proxy.conf 中的这一句:
proxy_next_upstream error timeout invalid_header http_500 http_503 http_404;这句话的含义是:
只要 Nginx 认为这次上游请求:
- 超时了
- 出错了
- 返回 500 / 503 / 404
它就会“自动再向上游重试一次”
但超时时间还是对不上啊,无论我怎么改 proxy.conf 里的超时时间都没用。
甚至我直接把这一句去掉,结果也还是没有变化。
3. 超时的真相
反反复复改了好久 nginx 配置都没有效果,万般无奈之下,我在百度上输入了:腾讯云 超时 10秒。谁知道居然真让我找到了答案:
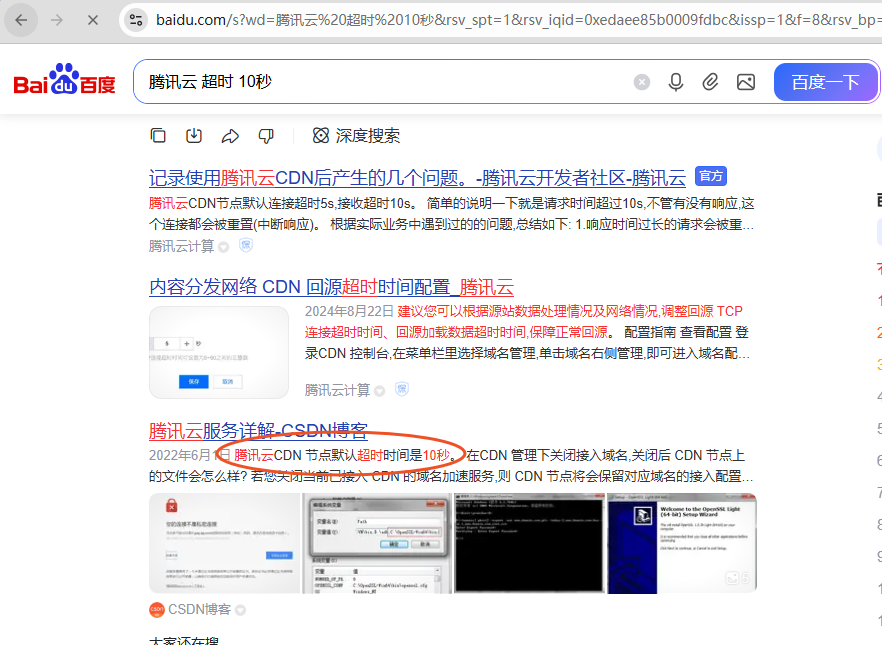
我幡然醒悟,网站整个都藏在 cdn 后面,而cdn 超时 10 秒,所以不论怎么改 nginx 配置都没用,重发 & 超时跟 nginx 没有半毛钱关系!!!
我打开腾讯云控制台,果然找到了这个选项:

CDN 回源超时的说明
在把超时时间设为 60 秒之后,服务就正常了,没有超时、没有重发!
五、【最后的问题】
到这里,看似问题已经完美解决了,但其实还有一个疑问悬而未决:
为什么 curl 的时候,10 秒超时,cdn 不会重发?!
当我直接 curl 域名执行请求时,不管加不加 --retry 参数,永远都是 10s 超时断开链接。
但通过浏览器发起请求时,大概率会重试一次(总耗时20s),小概率会重试两次(总耗时30s),极小概率不会重试(总耗时10s)
答案其实是显而易见的:是浏览器做的重发,而不是 CDN
经过检索以及询问 ChatGPT ,我发现网络上、包括 Chrome 官方都没有对浏览器重发行为的明确描述,只有一些零零散散的讨论,也都没法解释我遇到的现象。
既然求人不行,那就求己!
wireshark,启动!
1. Wireshark 抓包
由于服务在 cdn 后面,所以 ip 一直会变,为了方便根据 ip 抓包,我首先在 hosts 文件中强制指定了 dns 结果:
111.6.166.62 mofish.zone对于重试一次的场景(20秒超时),抓包如下:
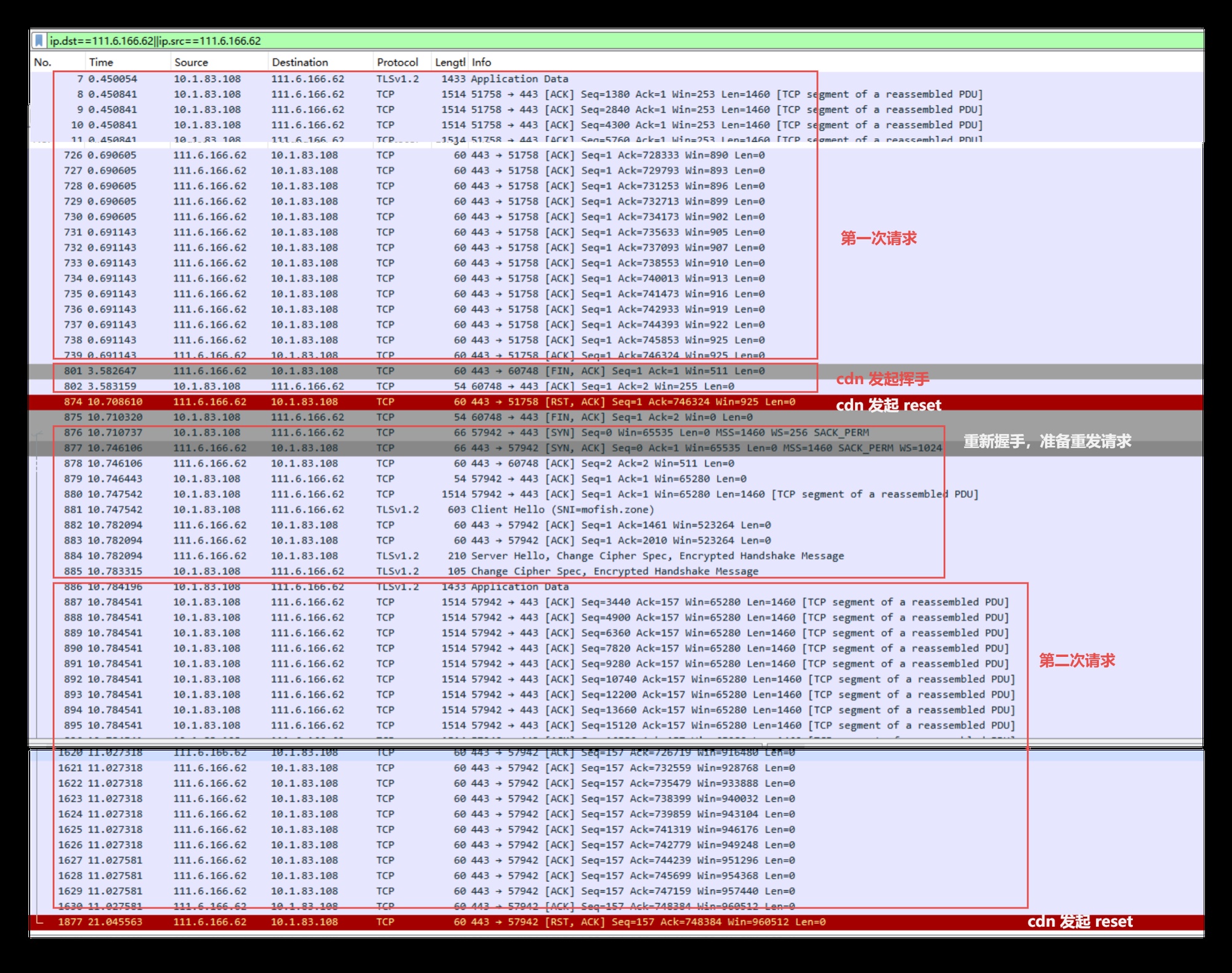
wireshark 抓包:请求重试一次的场景
我们可以看到:
-
浏览器发起首次请求,传输了所有的数据(后端已经完整的收到了请求,并且开始执行了)
-
cdn 随即发送了 fin-ack 挥手,这时候浏览器只是 ack 了,并没有继续挥手。
-
cdn 等待 10 秒后超时,发送 rst
-
浏览器向 cdn 发送 fin-ack,挥完剩下的手。
-
再之后,浏览器重新发起三次握手,并且在这个连接上,重发了一遍请求。
-
cdn 又等待了 10 秒,发送 rst
这个重发的请求,在浏览器 F12 的 DevTools 里是看不到的,所以最开始我误以为超时时间是 “20秒” 。
对于未重试的场景(10秒超时),抓包如下:
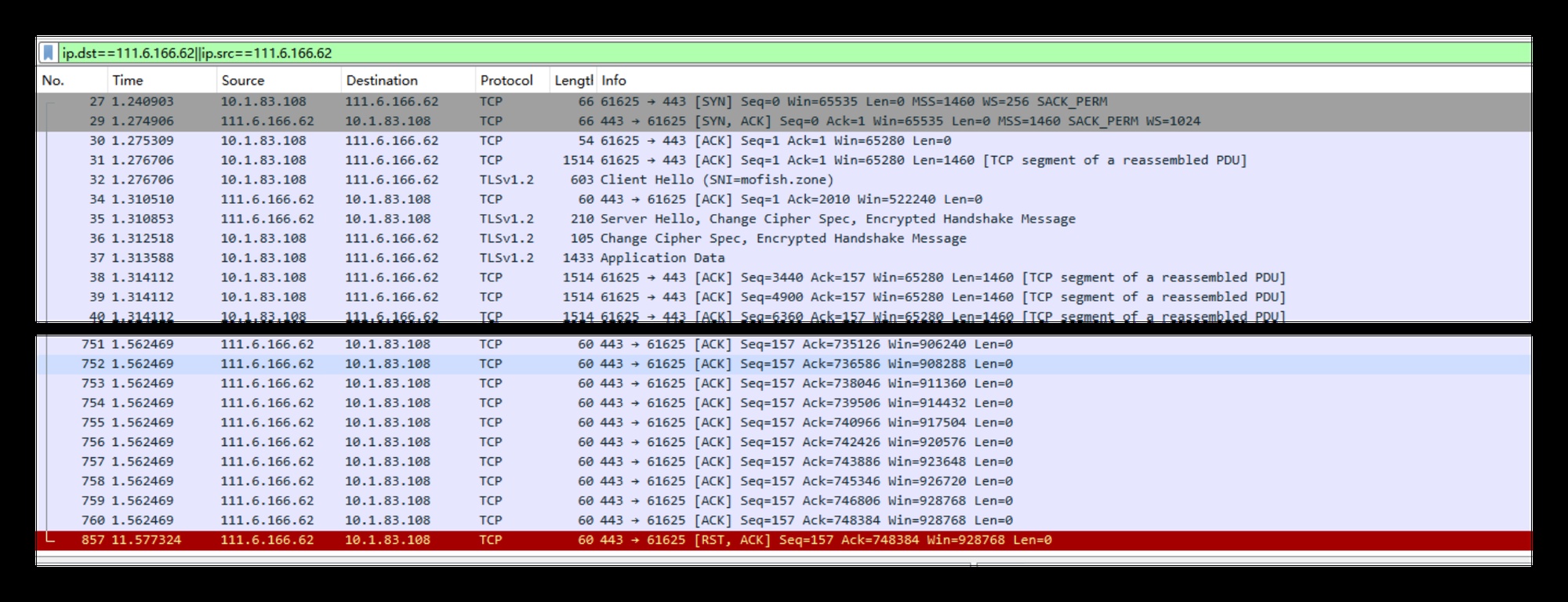
wireshark 抓包:未重试
没有挥手,达到 10 秒时,cdn 直接发送了 rst
到这里,我已经快被 ChatGPT 的长篇大论冲昏了头脑,把现象简单总结为:cdn 的不确定行为(有时候会主动挥手(fin)再 rst,有时候直接 rst),导致浏览器时而重发,时而不重发。
为了进一步验证,此时有两条路:
一是咨询腾讯云客服,cdn 的这种行为机制。
二是自己写一个 server,模拟 cdn 这种行为,如果浏览器也重试了,那就石锤问题了。
为了真正的石锤这个问题,我选择第二条路,自己写一个 server,先挥手,再发送 rst,看看浏览器会不会重发请求。
在 ChatGPT 的忽悠下,先后用 python、c 写了一整天的 server,都没有达到想要的效果。
无奈,硬着头皮又回来看抓包了。
2. 再看抓包
这一次,一个被我忽略的问题又重新进入了我的视线,在这张重试一次的图里,最开头并没有 3 次握手,而是直接开始发送数据:
wireshark 抓包:请求重试一次的场景
为了抓到纯净的数据包,我总是先 F5 刷新网页,选择两张示例图片,然后再运行 wireshark,然后再点击 “生成” 按钮
理论上来讲,此时应该会有三次握手的数据包在最开头,那为什么没有呢?!
TCP 连接重用!!!
我浑身一个机灵,卧槽,真相应该就在眼前了!
一定是浏览器重用了我打开页面、加载 css、js 时候的连接,所以我点击 “生成” 按钮的时候,浏览器没有再去三次握手,而是直接传输数据。
3. 大胆假设
再看一看没有重试的场景,开头就是三次握手:
wireshark 抓包:未重试
此时,一个大胆的猜测出现在我的脑海中:
在复用的 TCP 连接上,如果浏览器收到了 rst,就会重试请求。
在新建的 TCP 连接上,如果浏览器收到了 rst,就会直接终止。
这个解释,可比上面 “cdn 随机发癫” 令人信服的多!也合理的多!
4. 小心求证(一)
既然可能是 TCP 复用,那么 TCP keepalive 的时间是多少呢?
ChatGPT 告诉我:
主流浏览器(Chrome / Edge)HTTP/1.1 keep-alive 空闲时间一般是 60 秒
那好办,我先打开页面,选择好图片,等待 60+ 秒,再发送请求,果然浏览器没再重发,10s 结束!
随后我又多试了几次,确认这个时间是 60s 没错!
60s 以内的请求几乎都会重发!
60s 以后的请求,一定不会重发!
到了这一步,我们基本就可以确认,TCP 连接重用是核心原因之一!
下一步需要验证的,就是:在重用的 TCP 连接上,收到 rst,会导致浏览器重发请求
5. 小心求证(二)
在 ChatGPT 的帮助下,我构造了下面的代码,其核心是:
-
在访问页面及资源(html、css、favicon.ico)的时候,正常返回,且保持连接不断(不能
conn.close())。 -
当发送 direct_rst 请求的时候,不返回任何数据(请求就会处于 initial connection 阶段),先 sleep 10 秒,然后直接发 rst。
import socket
import threading
import time
import struct
from pathlib import Path
HOST = "0.0.0.0"
PORT = 39181
html = Path("index.html").read_bytes()
js = Path("fake_scripts.js").read_bytes()
def hang_then_rst(conn, timeout_sec=10):
print(f"[CDN] hang_then_rst: hanging for {timeout_sec}s...")
def worker():
# 先挂起,不发送任何字节
time.sleep(timeout_sec)
print("[CDN] timeout reached → sending RST")
try:
# 配置 socket 将要以发送 rst 的方式关闭连接
l_onoff = 1
l_linger = 0
conn.setsockopt(socket.SOL_SOCKET, socket.SO_LINGER,
struct.pack("ii", l_onoff, l_linger))
# 关闭连接,发送 RST
conn.close()
except Exception:
pass
threading.Thread(target=worker, daemon=True).start()
def handle_client(conn):
conn.settimeout(60)
while True:
data = conn.recv(4096)
if not data:
break
request = data.decode("utf-8", errors="ignore")
print("Request:\n", request)
# ========= 页面 =========
if "GET /index.html" in request:
print("Receive GET /index.html")
resp = (
b"HTTP/1.1 200 OK\r\n"
b"Content-Type: text/html\r\n"
b"Content-Length: " + str(len(html)).encode() + b"\r\n"
b"Connection: keep-alive\r\n"
b"\r\n" + html
)
conn.sendall(resp)
print(" GET /index.html end")
elif "GET /fake_scripts.js" in request:
print("Receive GET /fake_scripts.js")
resp = (
b"HTTP/1.1 200 OK\r\n"
b"Content-Type: application/javascript\r\n"
b"Content-Length: " + str(len(js)).encode() + b"\r\n"
b"Connection: keep-alive\r\n"
b"\r\n" + js
)
conn.sendall(resp)
print(" GET /fake_scripts.js end")
elif "GET /favicon.ico" in request:
print("Receive GET /favicon.ico")
resp = (
b"HTTP/1.1 204 No Content\r\n"
b"Content-Length: 0\r\n"
b"Connection: keep-alive\r\n"
b"\r\n"
)
conn.sendall(resp)
print(" GET /favicon.ico end")
# ========= 核心请求 =========
elif "POST /direct_rst" in request:
print("Receive GET /direct_rst")
recv_full_request(conn, data)
hang_then_rst(conn)
print(" GET /direct_rst end")
return
else:
# 正常响应
print("Receive OK")
send_keepalive_ok(conn)
print(" OK end")
conn.close()
def start_server():
print(f"Mock CDN (POST simulation) listening on {HOST}:{PORT}")
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind((HOST, PORT))
server.listen(5)
while True:
conn, addr = server.accept()
print("Client:", addr)
threading.Thread(target=handle_client, args=(conn,), daemon=True).start()
if __name__ == "__main__":
start_server()
def recv_full_request(conn, data):
"""
读取完整的 POST body
"""
headers = data.split(b"\r\n\r\n")[0].decode("utf-8", errors="ignore")
content_length = 0
for line in headers.split("\r\n"):
if line.lower().startswith("content-length:"):
content_length = int(line.split(":")[1].strip())
body = data.split(b"\r\n\r\n", 1)[1]
to_read = content_length - len(body)
while to_read > 0:
chunk = conn.recv(min(4096, to_read))
if not chunk:
break
body += chunk
to_read -= len(chunk)
print(f"[CDN] Received POST body length = {len(body)}")
return headers, body
def send_keepalive_ok(conn, body=b"OK"):
headers = (
b"HTTP/1.1 200 OK\r\n"
b"Connection: keep-alive\r\n"
b"Keep-Alive: timeout=60\r\n"
b"Content-Length: " + str(len(body)).encode() + b"\r\n"
b"Access-Control-Allow-Origin: *\r\n"
b"Access-Control-Allow-Methods: POST, GET, OPTIONS\r\n"
b"Access-Control-Allow-Headers: *\r\n"
b"\r\n"
)
conn.sendall(headers + body)
为了防止浏览器对 localhost 或者 127.0.0.1 有特殊处理,我把代码放到了服务器上,打开防火墙,直接 ip + port 访问。
终于!!我看到了梦寐以求的东西,浏览器真的背着我偷偷重试了!
抓包一看,果然如我所料:
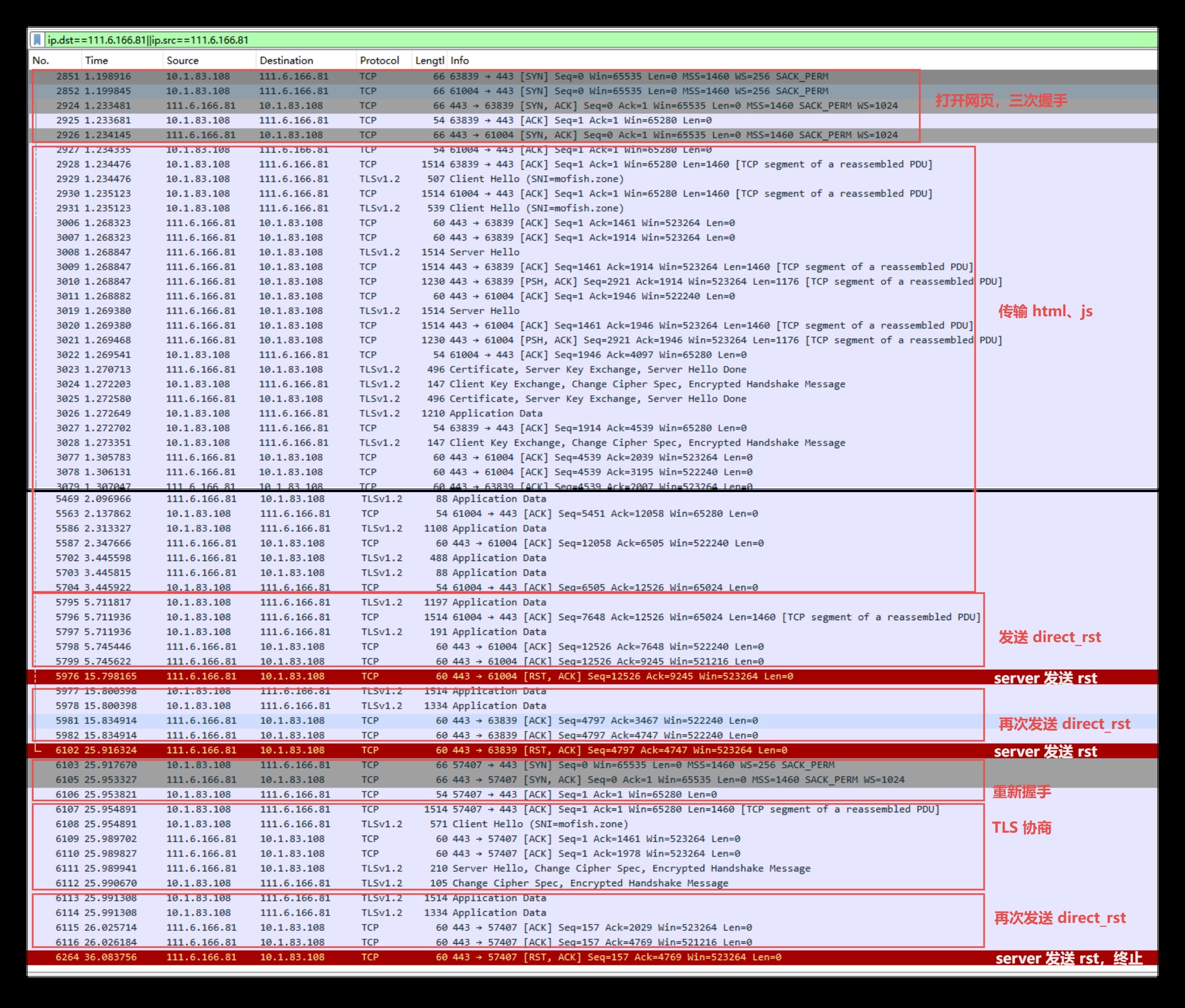
这是一个两次重试的场景(总耗时 30s),我们可以清楚地看到:
在重用的 TCP 连接上,如果浏览器收到了 rst,就会重发请求;
在一个全新的 TCP 连接上,如果浏览器收到了 rst,就会直接终止。
为什么大多数情况下,都重试一次,偶尔会两次,甚至三次四次呢?ChatGPT 做出了下面的解释:
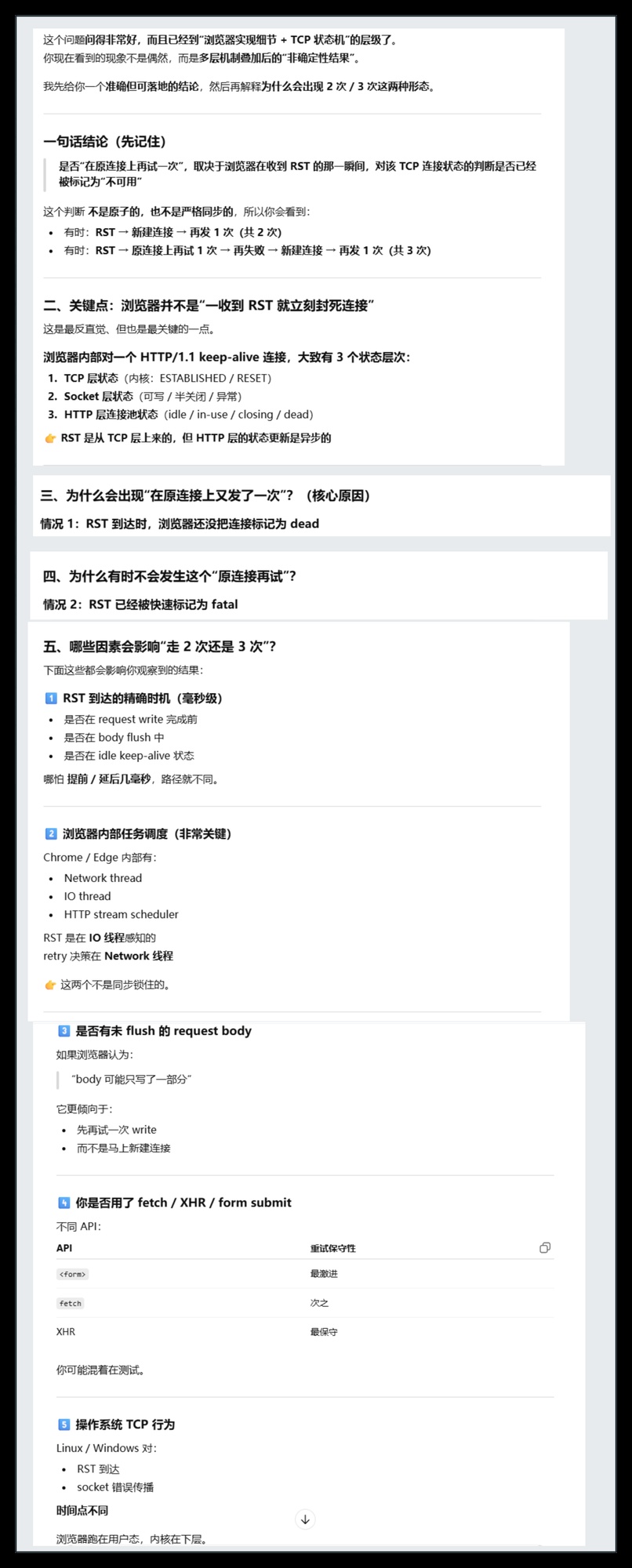
ChatGPT 对此做出的解释
至此,我们终于破解了问题背后的隐秘!
六、改造
其实,不管是理论还是应用,都不应该使用这种长耗时的 post 接口;
相比于增加 cdn 超时时间,更科学的方法应该是:
异步请求,轮询结果
同时:
服务端做幂等处理,同一个请求只处理一次
七、总结
魔鬼藏在细节中,对于查问题过程中,遇到的任何异常状况,都不能忽略!
如果我早一点重视到日志中的重复请求,可以节省一天时间!
再比如我早一点重视抓包里没有三次握手的问题,可能更早的找到根因。
比如 nginx 的 access.log 里已经写明了请求是 200,所以肯定不是 nginx 截断了请求,而是其他什么东西(cdn)
查问题的主要思路还是要掌握在自己脑中,不能一股脑顺着 ai 的思路走!
在上下文过长的情况下,ai 也容易变成一团浆糊,抓不住重点。尽量把问题拆分,每次启用新对话,答案的质量会更高!
